19个版本 (7个稳定版)
| 1.1.4 | 2024年1月8日 |
|---|---|
| 1.1.1 | 2023年10月3日 |
| 1.0.1 | 2023年6月1日 |
| 0.7.2 | 2022年5月9日 |
| 0.6.0 | 2022年3月17日 |
#113 in 算法
89每月下载量
355KB
2K SLoC
随机森林用于变化点检测
变化点检测旨在识别时间序列概率分布中的结构变化。现有方法要么假设分段分布的参数模型,要么基于秩或距离,因此在具有合理大维度的情况下失效。
changeforest实现了一个基于分类器的算法,该算法在没有任何参数假设的情况下,即使在高维情况下也能一致地估计变化点。它使用随机森林的袋外概率预测来构建一个分类器对数似然比,该比通过一种计算可行的两步法进行优化。
详情见[1]。
changeforest作为rust crate、Python包(在PyPI和conda-forge上)以及R包(在conda-forge,仅限Linux和MacOS)提供。下面是它们相应的用户指南。
Python
安装
要从conda-forge安装(推荐),运行
conda install -c conda-forge changeforest
要从PyPI安装,运行
pip install changeforest
示例
在下面的示例中,我们使用n=600个观测值和在t=200, 400处的协方差变化,对模拟数据集执行基于随机森林的变化点检测。
In [1]: import numpy as np
...:
...: Sigma = np.full((5, 5), 0.7)
...: np.fill_diagonal(Sigma, 1)
...:
...: rng = np.random.default_rng(12)
...: X = np.concatenate(
...: (
...: rng.normal(0, 1, (200, 5)),
...: rng.multivariate_normal(np.zeros(5), Sigma, 200, method="cholesky"),
...: rng.normal(0, 1, (200, 5)),
...: ),
...: axis=0,
...: )
模拟数据集X与[1]中描述的协方差变化(CIC)设置一致。第一和最后一段的观测值是独立地从标准多元高斯分布中抽取的。第二段的观测值是独立同分布的正态分布,均值为零,方差为1,但坐标之间的协方差为ρ = 0.7。这是一个具有挑战性的场景。
In [2]: from changeforest import changeforest
...:
...: result = changeforest(X, "random_forest", "bs")
...: result
Out[2]:
best_split max_gain p_value
(0, 600] 400 14.814 0.005
¦--(0, 400] 200 59.314 0.005
¦ ¦--(0, 200] 6 -1.95 0.67
¦ °--(200, 400] 393 -8.668 0.81
°--(400, 600] 412 -9.047 0.66
In [3]: result.split_points()
Out[3]: [200, 400]
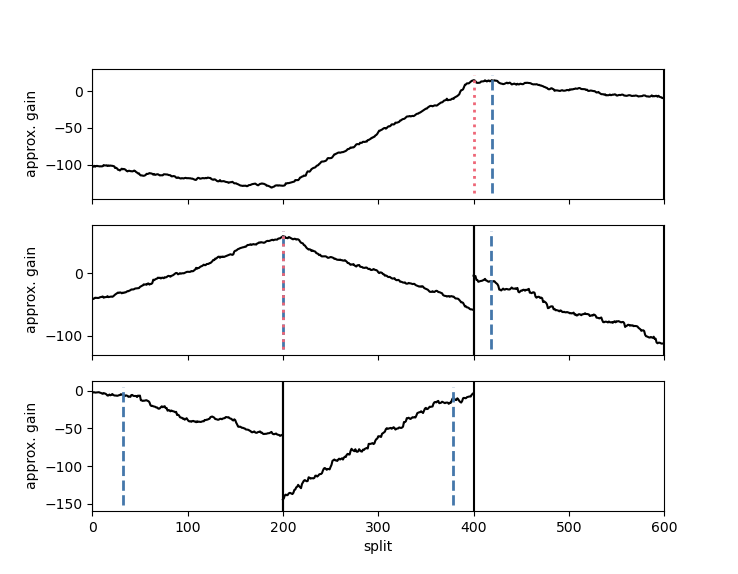
changeforest 正确识别了在 t=200 和 t=400 处的变化点。函数 changeforest 返回一个 BinarySegmentationResult 对象。我们使用其 plot 方法来研究变化点估计值最大化的增益曲线
In [4]: result.plot().show()
对于 method="random_forest" 和 method="knn",changeforest 算法采用两步法来寻找增益的优化器。这种方法在段落的 1/4、1/2 和 3/4 分位数处为三个分割候选者拟合分类器,使用结果分类器的对数似然比来计算近似的增益曲线,并将整体优化器作为第二次猜测来选择。我们可以使用 OptimizerResult 的 plot 方法来研究优化器的增益曲线。初始猜测用蓝色标记。
In [5]: result.optimizer_result.plot().show()
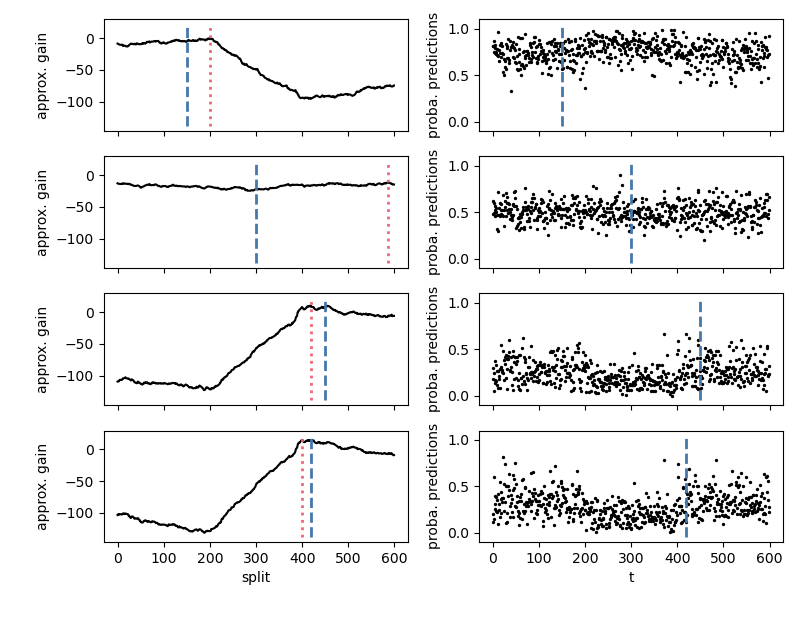
可以观察到,近似的增益曲线是分段线性的,最大值出现在真实的变化点上。
changeforest 返回的 BinarySegmentationResult 是一个具有属性 start、stop、best_split、max_gain、p_value、is_significant、optimizer_result、model_selection_result、left、right 和 segments 的树形对象。这些属性可以用来进一步研究算法的输出。
可以使用超参数调整 changeforest 算法。有关它们的描述和默认值,请参阅此处。在 Python 中,可以使用 Control 类来指定参数,并将其传递给 changeforest。以下代码将构建具有 50 棵树的随机森林:
In [6]: from changeforest import Control
...: changeforest(X, "random_forest", "bs", Control(random_forest_n_estimators=50))
Out[6]:
best_split max_gain p_value
(0, 600] 416 7.463 0.01
¦--(0, 416] 200 43.935 0.005
¦ ¦--(0, 200] 193 -14.993 0.945
¦ °--(200, 416] 217 -9.13 0.085
°--(416, 600] 591 -12.07 1
changeforest 算法仍然在 t=200 处检测到变化点,但在 t=416 处略有偏差。
由于变化的原因,method="change_in_mean" 无法检测到任何变化点。
In [7]: changeforest(X, "change_in_mean", "bs")
Out[7]:
best_split max_gain p_value
(0, 600] 589 8.625
R
要从 conda-forge 安装,请运行
conda install -c conda-forge r-changeforest
有关使用 conda 安装 changeforest R 包的详细说明,请参阅此处。
示例
在下面的示例中,我们使用n=600个观测值和在t=200, 400处的协方差变化,对模拟数据集执行基于随机森林的变化点检测。
> library(MASS)
> set.seed(0)
> Sigma = matrix(0.7, nrow=5, ncol=5)
> diag(Sigma) = 1
> mu = rep(0, 5)
> X = rbind(
mvrnorm(n=200, mu=mu, Sigma=diag(5)),
mvrnorm(n=200, mu=mu, Sigma=Sigma),
mvrnorm(n=200, mu=mu, Sigma=diag(5))
)
模拟数据集X与[1]中描述的协方差变化(CIC)设置一致。第一和最后一段的观测值是独立地从标准多元高斯分布中抽取的。第二段的观测值是独立同分布的正态分布,均值为零,方差为1,但坐标之间的协方差为ρ = 0.7。这是一个具有挑战性的场景。
> library(changeforest)
> result = changeforest(X, "random_forest", "bs")
> result
name best_split max_gain p_value is_significant
1 (0, 600] 410 13.49775 0.005 TRUE
2 ¦--(0, 410] 199 61.47201 0.005 TRUE
3 ¦ ¦--(0, 199] 192 -22.47364 0.955 FALSE
4 ¦ °--(199, 410] 396 11.50559 0.190 FALSE
5 °--(410, 600] 416 -23.52932 0.965 FALSE
> result$split_points()
[1] 199 410
changeforest 正确地识别了大约在 t=200 的变化点,但在 t=410 处略有偏差。函数 changeforest 返回一个类为 binary_segmentation_result 的对象。我们使用其 plot 方法来研究变化点估计值最大化的增益曲线
> plot(result)
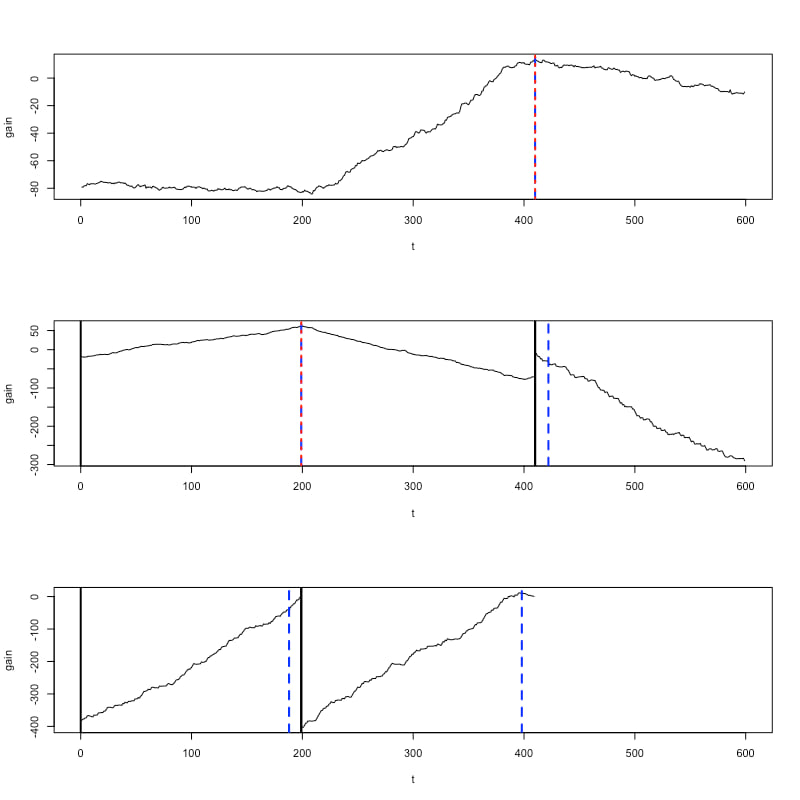
变化点估计用红色标记。
对于 method="random_forest" 和 method="knn",changeforest 算法采用两步法来寻找增益优化器。该方法在段落的 1/4、1/2 和 3/4 分位数处对三个分割候选者进行分类器拟合,使用所得分类器的对数似然比计算近似增益曲线,并将总体优化器作为第二次猜测选择。我们可以使用 optimizer_result 的 plot 方法调查优化器的增益曲线。初始猜测用蓝色标注。
> plot(result$optimizer_result)
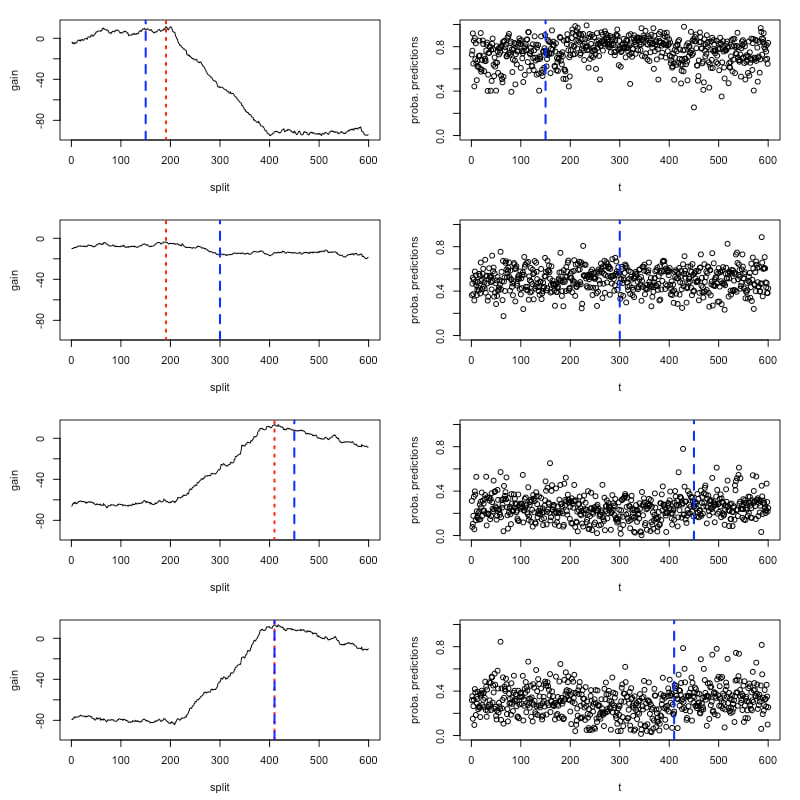
可以观察到,近似的增益曲线是分段线性的,最大值出现在真实的变化点上。
changeforest 返回的 binary_segmentation_result 对象是一个树形对象,具有属性 start、stop、best_split、max_gain、p_value、is_significant、optimizer_result、model_selection_result、left、right 和 segments。这些属性可以用于进一步研究算法的输出。
changeforest 算法可以通过超参数进行调整。有关它们的描述和默认值,请参阅此处。在 R 中,可以使用 Control 类指定参数,并将其传递给 changeforest。以下示例将构建具有 20 棵树的随机森林:
> changeforest(X, "random_forest", "bs", Control$new(random_forest_n_estimators=20))
name best_split max_gain p_value is_significant
1 (0, 600] 15 -6.592136 0.010 TRUE
2 ¦--(0, 15] 6 -18.186534 0.935 FALSE
3 °--(15, 600] 561 -4.282799 0.005 TRUE
4 ¦--(15, 561] 116 -8.084126 0.005 TRUE
5 ¦ ¦--(15, 116] 21 -17.780523 0.130 FALSE
6 ¦ °--(116, 561] 401 11.782002 0.005 TRUE
7 ¦ ¦--(116, 401] 196 22.792401 0.150 FALSE
8 ¦ °--(401, 561] 554 -16.338703 0.800 FALSE
9 °--(561, 600] 568 -5.230075 0.120 FALSE
changeforest 算法仍然在 t=200 附近检测到变化点,但也返回了假阳性。
由于变化的原因,method="change_in_mean" 无法检测到任何变化点。
> changeforest(X, "change_in_mean", "bs")
name best_split max_gain p_value is_significant
1 (0, 600] 498 17.29389 NA FALSE
参考文献
[1] M. Londschien, P. Bühlmann 和 S. Kovács (2023)。 "随机森林用于变化点检测",机器学习研究杂志
依赖关系
~3MB
~58K SLoC