1 个不稳定版本
| 新功能 0.1.1 | 2024年8月13日 |
|---|
#292 在 文本处理
104 每月下载量
760KB
1K SLoC
BlitzText
BlitzText 是一个高性能库,用于在字符串中高效地提取和替换关键字。它基于 FlashText 和 Aho-Corasick 算法。它有 Rust 和 Python 实现版本。与 Aho-Corasick 的主要区别在于 BlitzText 以贪婪的方式只匹配最长的模式。
目录
安装
Rust
将其添加到您的 Cargo.toml
[dependencies]
blitztext = "0.1.0"
或
cargo add blitztext
Python
使用 pip 安装库
pip install blitztext
用法
Rust 用法
use blitztext::KeywordProcessor;
fn main() {
let mut processor = KeywordProcessor::new();
processor.add_keyword("rust", Some("Rust Lang"));
processor.add_keyword("programming", Some("Coding"));
let text = "I love rust programming";
let matches = processor.extract_keywords(text, None);
for m in matches {
println!("Found '{}' at [{}, {}]", m.keyword, m.start, m.end);
}
let replaced = processor.replace_keywords(text, None);
println!("Replaced text: {}", replaced);
// Output: "I love Rust Lang Coding"
}
Python 用法
from blitztext import KeywordProcessor
processor = KeywordProcessor()
processor.add_keyword("rust", "Rust Lang")
processor.add_keyword("programming", "Coding")
text = "I love rust programming"
matches = processor.extract_keywords(text)
for m in matches:
print(f"Found '{m.keyword}' at [{m.start}, {m.end}]")
replaced = processor.replace_keywords(text)
// Output: "I love Rust Lang Coding"
print(f"Replaced text: {replaced}")
特性
1. 并行处理
用于并行处理多个文本
// Rust
let texts = vec!["Text 1", "Text 2", "Text 3"];
let results = processor.parallel_extract_keywords_from_texts(&texts, None);
# Python
texts = ["Text 1", "Text 2", "Text 3"]
results = processor.parallel_extract_keywords_from_texts(texts)
2. 模糊匹配
Rust 和 Python 实现都支持模糊匹配
// Rust
let matches = processor.extract_keywords(text, Some(0.8));
# Python
matches = processor.extract_keywords(text, threshold=0.8)
3. 区分大小写
您可以选择启用区分大小写的匹配
// Rust
let mut processor = KeywordProcessor::with_options(true, false);
processor.add_keyword("Rust", Some("Rust Lang"));
let matches = processor.extract_keywords("I love Rust and rust", None);
// Only "Rust" will be matched, not "rust"
# Python
processor = KeywordProcessor(case_sensitive=True)
processor.add_keyword("Rust", "Rust Lang")
matches = processor.extract_keywords("I love Rust and rust")
# Only "Rust" will be matched, not "rust"
4. 重复匹配
启用重复匹配
// Rust
let mut processor = KeywordProcessor::with_options(false, true);
processor.add_keyword("word", None);
processor.add_keyword("sword", None);
let matches = processor.extract_keywords("I have a sword", None);
// "word" will be matched
# Python
processor = KeywordProcessor(allow_overlaps=True)
processor.add_keyword("word")
matches = processor.extract_keywords("I have a sword")
# "word" will be matched
5. 自定义非单词边界
此库使用非单词边界的概念来确定单词的开始和结束位置。默认情况下,字母数字字符和下划线被认为是单词的一部分。您可以自定义此行为以满足特定需求。
理解非单词边界
- 定义为非单词边界的字符被认为是单词的一部分。
- 未定义为非单词边界的字符被视为单词分隔符。
示例
// Rust
let mut processor = KeywordProcessor::new();
processor.add_keyword("rust", None);
processor.add_keyword("programming", Some("coding"));
let text = "I-love-rust-programming-and-1coding2";
// Default behavior: '-' is a word separator
let matches = processor.extract_keywords(text, None);
assert_eq!(matches.len(), 2);
// Matches: "rust" and "coding"
// Add '-' as a non-word boundary
processor.add_non_word_boundary('-');
// Now '-' is considered part of words
let matches = processor.extract_keywords(text, None);
assert_eq!(matches.len(), 0);
// No matches, because "rust" and "programming" are now part of larger "words"
# Python
processor = KeywordProcessor()
processor.add_keyword("rust")
processor.add_keyword("programming", "coding")
text = "I-love-rust-programming-and-1coding2"
# Default behavior: '-' is a word separator
matches = processor.extract_keywords(text)
assert len(matches) == 2
# Matches: "rust" and "coding"
# Add '-' as a non-word boundary
processor.add_non_word_boundary('-')
# Now '-' is considered part of words
matches = processor.extract_keywords(text)
assert len(matches) == 0
# No matches, because "rust" and "programming" are now part of larger "words"
设置全新的非单词边界集合
// Rust
processor.set_non_word_boundaries(&['-', '_', '@']);
# Python
processor.set_non_word_boundaries(['-', '_', '@'])
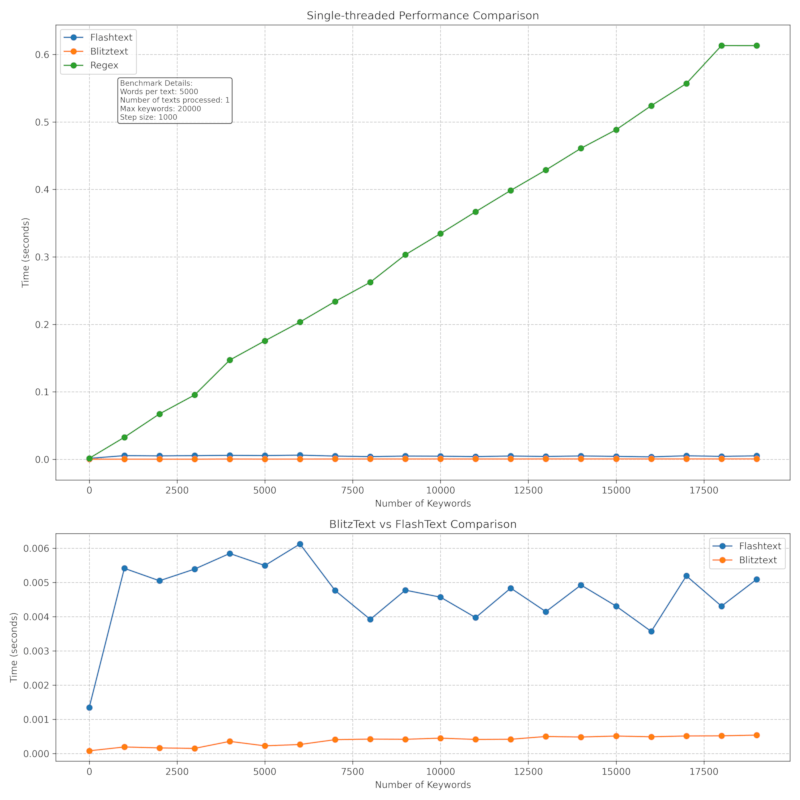
性能
BlitzText 为高性能而设计,适用于处理大量文本。基准测试细节在此。
多线程性能: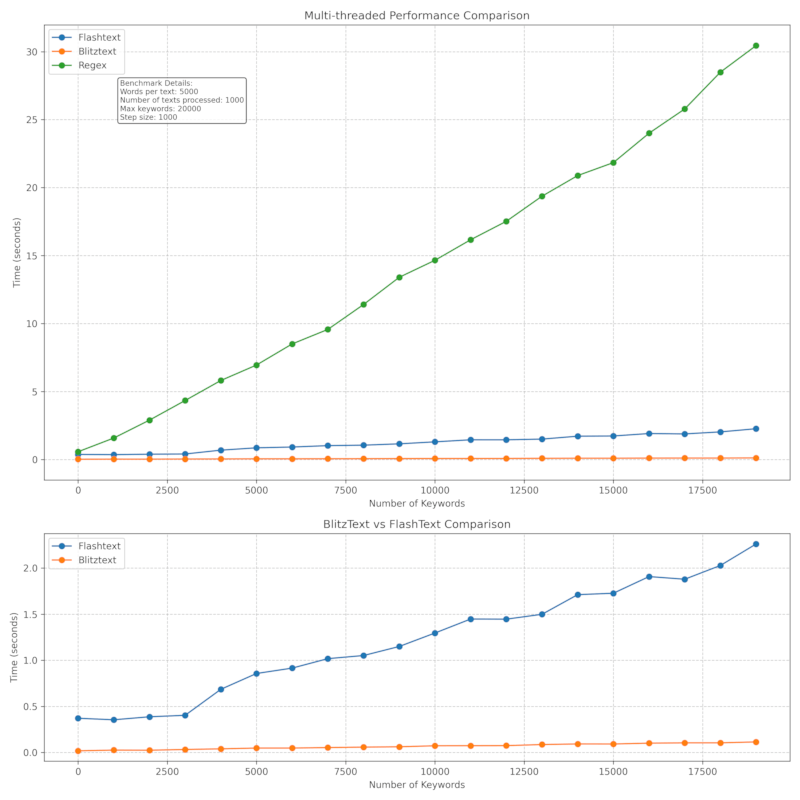
贡献
欢迎贡献!请随时提交拉取请求。
问题
如果您遇到任何问题,请附带详细描述,在问题页面提交。
许可协议
本项目采用MIT许可证授权。
依赖项
~9MB
~167K SLoC