10个版本
| 0.3.7 | 2023年10月7日 |
|---|---|
| 0.3.6 | 2023年5月21日 |
| 0.3.5 | 2021年4月1日 |
| 0.3.4 | 2020年12月21日 |
| 0.1.0 | 2020年7月4日 |
#143 in 数据结构
535 每月下载量
在 2 个crate中使用(通过 indexmap-amortized)
105KB
2K SLoC
![]()
![]()
![]()
![]()
一种将resize负载分散到push操作中的VecDeque(和Vec)变体。
大多数类似向量的实现,例如 Vec 和 VecDeque,必须偶尔“调整大小”以适应向量背后的内存,因为元素的数量增长。这意味着分配一个新的向量(通常是原来大小的两倍),并将所有元素从旧向量移动到新向量中。随着向量变大,这个过程会越来越慢。
对于大多数应用程序来说,这种行为是可接受的——如果一些非常小的push操作比其他操作慢,应用程序甚至不会注意到。如果向量本身相对较小,即使是那些“慢”的push操作也相当快。同样,如果您的向量增长了一段时间,然后 停止 增长,应用程序的“稳态”根本看不到任何调整大小的暂停。
调整大小成为问题的地方在于使用向量保持不断增长的状态的应用程序,其中尾部延迟很重要。在大型规模上,一个push操作需要30毫秒,而大多数操作只需要十几个纳秒,这是绝对不行的。更糟糕的是,这些调整大小的暂停可以累积,导致尾部延迟的显著峰值。
此crate实现了一种称为“增量调整大小”的技术,与上面概述的常见“一次性”方法相反。其核心思想非常简单:不是立即将所有元素移动到调整大小的向量中,而是在每次push操作时移动几个元素。这分散了移动元素的成本,使得每个push操作都稍微慢一些,直到调整大小完成,而不是一个push操作变得非常慢。
然而,这种方法并非没有代价。在调整大小过程中,必须保留旧向量(因此内存不会被立即回收),并且迭代器和其他向量级操作必须访问两个向量,这使它们变慢。只有当调整大小完成后,才能回收旧向量并恢复完整性能。
为了帮助您决定此实现是否适合您,以下是如何与此实现与标准库向量进行比较的便捷参考
- 所有push操作的时间大致相同。调整大小后,它们会慢一段时间,但只慢一个相对较小的系数。
- 调整大小时,内存不会立即回收。
- 由于需要检查两个向量,访问操作略慢。
- 增量向量在栈上稍微大一些。
- 由于一次性调整大小会将项目从小向量批量移动到大小向量,而增量操作则执行一系列推送,因此调整大小的“效率”略低。
此外,由于这个crate必须保持两个向量,因此不能保证元素存储在连续的内存块中。由于它必须在它们之间移动元素而不会丢失顺序,因此它由VecDeque支持,这意味着即使在调整大小完成后也是如此。因此,这个crate提供的接口比Vec更类似于VecDeque。尽管如此,它仍然提供了类似于Vec的方法。如果需要连续内存,没有很好的方法在不使用低级内存映射魔法的情况下进行增量调整大小,这是我所知的情况。
基准测试
在benches/vroom.rs中有一个愚蠢但具有说明性的基准测试。它只是连续运行多次推送操作,并测量每次操作所需的时间。问题很快就会显现出来。
$ cargo bench --bench vroom > vroom.dat
Vec max: 2.440556ms, mean: 25ns
VecDeque max: 4.512806ms, mean: 25ns
atone::Vc max: 25.789µs, mean: 26ns
您可以看到标准库实现有一些相当严重的延迟峰值。这可以通过时间线延迟图(misc/vroom.plt)更清晰地看到。
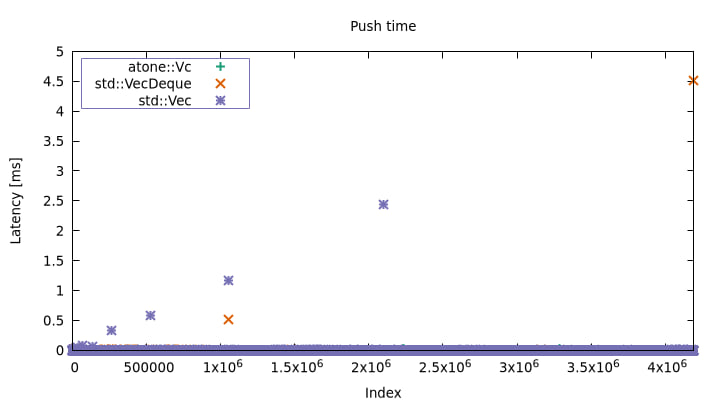
随着向量的增长,调整大小的频率较低,但它们在发生时也变得更长。使用atone,这些峰值大多消失了。
有关原地调整大小的说明
一些内存分配器有API可以用于原地增加分配的大小。这个操作不一定总是成功,在这种情况下,它会回退到常规分配加memcpy,但成功时,调整大小基本上是免费的。Vec和VecDeque有时可以利用这种类型的原地调整大小,而atone::Vc则不行。
在实践中,您不太可能为适合atone::Vc用例的向量获得原地调整大小。如果运行的应用程序继续在别处分配内存,那么很可能会在向量的当前后端内存之后的堆空间中分配某些东西,在这种情况下,原地重新分配是不可能的。
Vec特别还有一个优化(我不确定这个名字是什么),即使分配在堆上被包围,它也可以执行原地调整大小。我假设这涉及到一些内存重映射技巧。但这只适用于特定的分配器(例如,它不适用于jemalloc)。
实现
atone由两个VecDeque支持。一个是“当前”向量,另一个持有上次调整大小后的任何剩余部分。从逻辑上讲,剩余部分被处理为向量的头部,而当前向量被处理为尾部。然后通过从剩余部分中弹出元素并将它们推送到当前向量的前面来实现推送时的“增量”部分。正是这种移动以及支持push的需要使我选择了VecDeque,因为使用Vec,推送到前面将需要移动所有元素。
atone的目标是在代码和API方面尽可能接近Vec和VecDeque。在src/lib.rs文件中,实际上与src/liballoc/collections/vec_deque.rs在std中的内容几乎完全相同(我鼓励您对比它们!)。
为什么叫做“atone”?
我们让向量因为犯下重新分配的罪行而进行更昂贵的推送来进行赎罪吗?..?
许可证
许可协议为以下之一
- Apache License, Version 2.0 (LICENSE-APACHE 或 https://apache.ac.cn/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT 或 https://open-source.org.cn/licenses/MIT)
由您选择。
贡献
除非您明确说明,否则您有意提交的任何贡献,根据Apache-2.0许可证定义,应按照上述方式双许可,不附加任何额外条款或条件。
依赖关系
~0–440KB