30 个版本
| 0.33.47 | 2023 年 8 月 15 日 |
|---|---|
| 0.33.46 | 2023 年 8 月 14 日 |
| 0.33.41 | 2023 年 7 月 28 日 |
| 0.33.30 | 2023 年 6 月 23 日 |
| 0.33.22 | 2023 年 5 月 31 日 |
#1019 在 数据库接口 中
16,011 星 & 150 关注者
2.5MB
60K SLoC
![]()
网站 • 入门 • 文档 • 示例 • 博客 • Slack • Twitter
![]()
![]()
![]()
Cube 是构建数据应用程序的语义层。 它帮助数据工程师和应用程序开发者访问来自现代数据存储的数据,将其组织成一致的定义,并将其提供给每个应用程序。
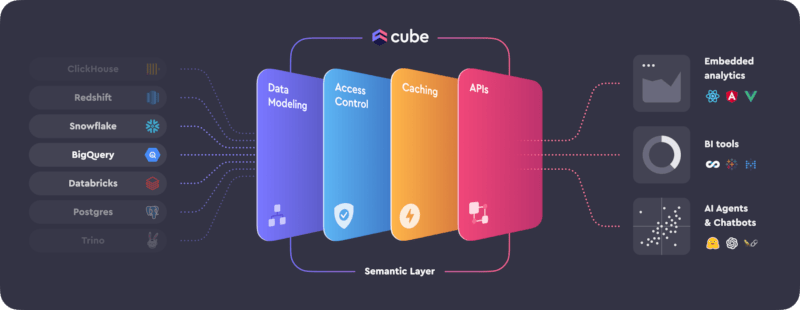
了解更多关于将 Cube 连接到 数据源 和 分析 & 可视化工具 的信息。
Cube 设计用于与所有启用 SQL 的数据源一起工作,包括 Snowflake 或 Google BigQuery 这样的云数据仓库、Presto 或 Amazon Athena 这样的查询引擎,以及 Postgres 这样的应用程序数据库。Cube 内置了关系缓存引擎,以提供亚秒级延迟和高并发性,以满足 API 请求。
有关更多详细信息,请参阅我们的文档中的简介页面。
为什么选择Cube?
如果您正在构建数据应用——例如商业智能工具或面向客户的分析功能——您可能会遇到以下问题
- SQL代码组织。 使用纯SQL查询建模十几个指标和十几个维度,最终会成为维护噩梦,这导致建立建模框架。
- 性能。 在现代分析软件开发的很大一部分时间和精力都花在提供足够的时间来洞察。在一个每个公司的数据都是大数据的世界里,仅仅编写SQL查询来获得洞察力已经不够了。
- 访问控制。 对于所有下游数据消耗应用来说,确保和治理数据访问非常重要。
Cube具有实施高效数据建模、访问控制和性能优化的必要基础设施和功能,以便每个应用——如嵌入式分析、仪表板和报告工具、数据笔记本和其他工具——都可以通过REST、SQL和GraphQL API访问一致的数据。

入门 🚀
Cube Cloud
Cube Cloud 是开始使用Cube最快的方式。它提供托管基础设施以及为开发项目和概念验证提供即时免费访问。

有关Cube Cloud的逐步指南,请参阅文档。
Docker
或者,您可以使用Docker在本地开始使用Cube或自行托管它。Docker。
一旦安装了Docker,在您项目的新的文件夹中,运行以下命令
docker run -p 4000:4000 \
-p 15432:15432 \
-v ${PWD}:/cube/conf \
-e CUBEJS_DEV_MODE=true \
cubejs/cube
然后,在浏览器中打开https://:4000 继续设置。
有关Docker的逐步指南,请参阅文档。
资源
贡献
您有多种方式可以为Cube做出贡献!以下是一些可能性
- 在GitHub上关注此仓库,并关注我们的Twitter。
- 在Stackshare上添加Cube到您的技术栈。
- 对问题使用👍反应进行投票,这样我们就知道特定问题的需求,以便在路线图中进行优先排序。
- 每次您觉得缺少或出现问题的时候,都创建一个issue。
- 如果您认为其他人也会提出这些问题,请在Stack Overflow上用cube.js标签提问。
- 为所有开放问题提供pull requests,特别是那些带有需要帮助和良好入门问题标签的问题。
所有类型的贡献都受到欢迎并且非常有帮助 🙌 请参阅贡献指南以获取更多信息。
许可证
Cube Client采用MIT许可证。
Cube Backend采用Apache 2.0许可证。

依赖关系
~39–76MB
~1.5M SLoC