5个版本 (3个破坏性更新)
| 0.4.0 | 2023年6月13日 |
|---|---|
| 0.3.0 | 2021年1月2日 |
| 0.2.1 | 2020年12月28日 |
| 0.1.1 | 2020年12月27日 |
#734 in 编码
每月下载量2,165
用于 naumi
305KB
7K SLoC
varint-simd
![]()
![]()
varint-simd是一个快速SIMD加速的可变长度整数和LEB128编码和解码库,用Rust编写。它结合了大量的无分支设计和编译时专门化,在普通硬件上实现每秒数GB的吞吐量编码和解码单个整数。还提供了一个解码多个相邻可变长度整数的接口,以实现更高的吞吐量,在单个线程上达到每秒超过十亿个8位整数的解码。
此库目前针对至少x86_64处理器,支持SSSE3(Intel Core/AMD Bulldozer或更新的处理器),可选地对支持POPCNT、LZCNT、BMI2和/或AVX2的处理器进行优化。它旨在用于Protocol Buffers(protobuf)、Apache Avro和类似的序列化格式实现,但可能还有许多其他应用。
使用
重要:请确保Rust编译器有合适的target-cpu设置。以下是一个示例,在.cargo/config中提供,但您可能需要编辑该文件以指定编译的二进制文件支持的最低CPU版本。如果没有正确设置,项目将无法编译。
如果target-cpu设置为native,则应启用native-optimizations功能,例如示例中所示。这将在适合您特定CPU的情况下启用一些额外的优化。以下了解更多信息。
use varint_simd::{encode, decode, encode_zigzag, decode_zigzag};
fn main() {
let num: u32 = 300;
let encoded = encode::<u32>(num); // turbofish for demonstration purposes, usually not necessary
// encoded now contains a tuple
// (
// [0xAC, 0x02, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], // encoded in a 128-bit vector
// 2 // the number of bytes encoded
// )
let decoded = decode::<u32>(&encoded.0).unwrap();
// decoded now contains another tuple:
// (
// 300, // the decoded number
// 2 // the number of bytes read from the slice
// )
assert_eq!(decoded.0, num);
// Signed integers can be encoded/decoded with convenience functions encode_zigzag and decode_zigzag
let num: i32 = -20;
let encoded = encode_zigzag::<i32>(num);
let decoded = decode_zigzag::<i32>(&encoded.0).unwrap();
assert_eq!(decoded.0, num);
}
传递给编码/解码函数的类型参数会极大地影响性能 - 对于较短的整数,代码会采用较短的路径,如果您将大量的小整数解码为 u64,可能会表现出比较差的性能。
安全性
这个crate使用了很多不安全代码。请谨慎使用,尽管我不期望会有重大问题。
还有一个可选的“不安全”接口,可以绕过溢出和边界检查。当您知道输入数据不会导致未定义行为,并且调用代码可以容忍截断的数字时,可以使用此功能。
基准测试
下面的基准测试反映了解码和编码一系列随机整数的性能,这些整数的大小受每个整数大小限制。所有基准测试都是在本地优化下运行的。有关更多详细信息,请参阅这些基准测试的源代码。
Intel Core i7-8850H "Coffee Lake" (2018 15" MacBook Pro)
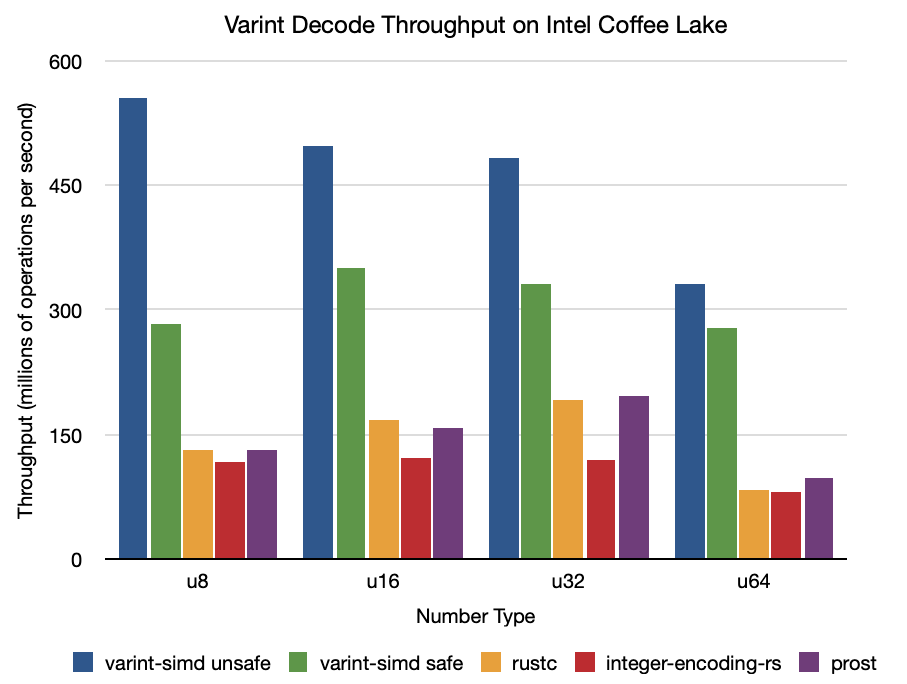
解码
所有数字都以每秒百万个整数表示。
| varint-simd 不安全 | varint-simd 安全 | rustc | integer-encoding-rs | prost | |
|---|---|---|---|---|---|
u8 |
554.81 | 283.26 | 131.71 | 116.59 | 131.42 |
u16 |
493.96 | 349.74 | 168.09 | 121.35 | 157.68 |
u32 |
482.95 | 332.11 | 191.37 | 120.16 | 196.05 |
u64 |
330.86 | 277.65 | 82.315 | 80.328 | 97.585 |
| varint-simd 2x | varint-simd 4x | varint-simd 8x | |
|---|---|---|---|
u8 |
658.52 | 644.36 | 896.32 |
u16 |
547.39 | 540.93 | |
u32 |
688.11 |
编码
| varint-simd | rustc | integer-encoding-rs | prost | |
|---|---|---|---|---|
u8 |
383.01 | 214.05 | 126.66 | 93.617 |
u16 |
341.25 | 181.18 | 126.79 | 85.014 |
u32 |
360.87 | 157.95 | 125.00 | 77.402 |
u64 |
303.72 | 72.660 | 78.153 | 46.456 |
AMD Ryzen 5 2600X @ 4.125 GHz "Zen+"
解码
| varint-simd 不安全 | varint-simd 安全 | rustc | integer-encoding-rs | prost | |
|---|---|---|---|---|---|
u8 |
537.51 | 304.85 | 152.35 | 138.54 | 124.44 |
u16 |
403.39 | 300.68 | 170.31 | 156.06 | 147.83 |
u32 |
293.88 | 235.92 | 160.48 | 159.13 | 150.05 |
u64 |
229.28 | 193.28 | 75.822 | 85.010 | 83.407 |
| varint-simd 2x | varint-simd 4x | varint-simd 8x | |
|---|---|---|---|
u8 |
943.75 | 808.45 | 1,106.50 |
u16 |
721.01 | 632.03 | |
u32 |
459.77 |
编码
| varint-simd | rustc | integer-encoding-rs | prost | |
|---|---|---|---|---|
u8 |
362.97 | 211.07 | 142.16 | 98.237 |
u16 |
334.10 | 172.09 | 140.78 | 96.480 |
u32 |
288.19 | 101.56 | 126.27 | 82.210 |
u64 |
207.89 | 52.515 | 79.375 | 48.088 |
待办事项
- 同时编码多个值
- 使用 AVX2(目前相当慢)更快地解码两个
u64值 - 改进“安全”接口的性能
- 并行 ZigZag 解码/编码
- 支持 ARM NEON
- 回退标量实现
- 进一步优化(我非常确信我还有一些性能没有发挥出来)
欢迎贡献。😊
关于 native-optimizations 功能
此功能标志启用了一个构建脚本,该脚本检测当前CPU,并在CPU支持高效运行这些指令时启用PDEP/PEXT优化。仅在将target-cpu选项设置为native时启用。
这是必要的,因为AMD Zen、Zen+和Zen 2处理器在微代码中实现这些指令,这意味着它们的运行速度比在硬件中实现要慢得多。此外,Rust不允许基于target-cpu选项的条件编译,因此需要手动指定此功能。
库crate 不应该默认启用此功能。应提供单独的功能标志以在crate中启用此功能。
以往的工作
- 丹尼尔·莱米尔,内森·库尔茨,克里斯托夫·鲁普 - Stream VByte:更快的字节导向整数压缩,信息处理快报130,2018:https://arxiv.org/abs/1709.08990
- 杰夫·普莱桑斯,内森·库尔茨,丹尼尔·莱米尔 - 向量化 VByte 解码,国际网络算法研讨会,2015:https://arxiv.org/abs/1503.07387
许可证
根据您的选择,受以下任一许可证的约束
- Apache License,版本 2.0 (LICENSE-APACHE 或 https://apache.ac.cn/licenses/LICENSE-2.0)
- MIT许可证 (LICENSE-MIT 或 https://open-source.org.cn/licenses/MIT)
。
贡献
除非您明确表示,否则根据Apache-2.0许可证定义,您提交的任何有意包含在作品中的贡献,都应按上述方式双授权,不附加任何额外条款或条件。
无运行时依赖
~195KB