1 个稳定版本
| 1.0.0 | 2024年1月30日 |
|---|
#70 在 缓存
761 每月下载量
350KB
916 行
ustr
快速,FFI 兼容的字符串国际化。
[!NOTE] 这是
ustr的分支,用ahash替换fxhash以实现一致的哈希。
一个 Ustr (Uique str) 是一个轻量级的句柄,表示全局字符串缓存中的静态、不可变条目,允许进行
-
极快的字符串赋值和比较。
-
高效存储。内存中只保留一个字符串副本,访问它只是一个指针间接。
-
快速哈希 — 预计算的哈希值与字符串一起存储。
-
快速 FFI — 字符串以终止的空字节存储,可以直接传递给 C 而无需执行
CString舞蹈。
缺点是永远不会释放任何字符串,因此如果您创建了很多很多字符串,可能会耗尽内存。另一方面,战争与和平 只有 3MB,所以这可能是可以的。
此 crate 基于 OpenImageIO 的 (OIIO) ustring,但它 不是 二进制兼容的(目前还不是)。底层的哈希图实现直接从 OIIO 端口。
用法
use ustr::{Ustr, ustr};
// Creation is quick and easy using either `Ustr::from` or the `ustr` short
// function and only one copy of any string is stored
let h1 = Ustr::from("hello");
let h2 = ustr("hello");
// Comparisons and copies are extremely cheap
let h3 = h1;
assert_eq!(h2, h3);
// You can pass straight to FFI
let len = unsafe {
libc::strlen(h1.as_char_ptr())
};
assert_eq!(len, 5);
// For best performance when using Ustr as key for a HashMap or HashSet,
// you'll want to use the precomputed hash. To make this easier, just use
// the UstrMap and UstrSet exports:
use ustr::UstrMap;
// Key type is always Ustr
let mut map: UstrMap<usize> = UstrMap::default();
map.insert(u1, 17);
assert_eq!(*map.get(&u1).unwrap(), 17);
通过启用 "serde" 功能,您可以使用 serde 序列化单个 Ustr 或整个缓存。
use ustr::{Ustr, ustr};
let u_ser = ustr("serialization is fun!");
let json = serde_json::to_string(&u_ser).unwrap();
let u_de : Ustr = serde_json::from_str(&json).unwrap();
assert_eq!(u_ser, u_de);
由于缓存是全局的,请使用 ustr::DeserializedCache 虚拟对象来驱动反序列化。
ustr("Send me to JSON and back");
let json = serde_json::to_string(ustr::cache()).unwrap();
// ... some time later ...
let _: ustr::DeserializedCache = serde_json::from_str(&json).unwrap();
assert_eq!(ustr::num_entries(), 1);
assert_eq!(ustr::string_cache_iter().collect::<Vec<_>>(), vec!["Send me to JSON and back"]);
C/C++ 调用
如果您正在编写一个使用 ustr 的库,并且希望用户能够从 C 创建 Ustr 并将其传递到您的 API,请将 ustr_extern.rs 添加到您的 crate 中,并使用 include/ustr.h 或 include/ustr.hpp 进行函数声明。
变更日志
自 0.10 以来更改
- 实际上将“序列化”功能的用法重命名为“serde”
自 0.9 以来更改
- 修复了会导致
Ustr在wasm32-unknown-unknown上无法工作的问题(由 bouk 贡献)
并感谢 virtualritz
-
Ustr::get_cache()已更名为cache() -
所有依赖都已更新到最新版本
-
所有功能都已移除(有很好的默认值),除了
serialization -
serialization功能已被更名为serde -
ustr现在使用 Rust 2021
自 0.8 以来变更
-
添加
existing_ustr函数(由 macprog-guy 贡献)此功能的想法是只允许在
Ustr已存在的情况下创建它。这在使用不可信用户输入(例如从 Web 服务器或 API)创建Ustr时特别有用。在这种情况下,通过在每次调用中提供不同的值,我们消耗越来越多的内存,最终耗尽(DoS)。 -
添加
Ord实现(由 zigazeljko 贡献) -
内联了一些简单函数(由 g-plane 贡献)
-
修复测试,改为锁定而不是依赖于
RUST_TEST_THREADS=1(由 kornelski 贡献) -
修复测试,以正确处理启用时的情况(由 kornelski 贡献)
-
在分配器中添加了对潜在分配失败的检查(由 kornelski 贡献)
-
添加
FromStr实现(由 martinmr 贡献) -
添加
rustfmt.toml到仓库
自 0.7 以来的变更
-
更新依赖
parking_lot和ahash的版本已更新。 -
使用
NonNull进行空间优化内部指针现在是
NonNull,以利用Option等中的布局优化。 -
添加
as_cstr()方法添加
as_cstr(&self) -> std::ffi::CStr以便于与依赖CStr的 API 进行接口交互。
自 0.6 以来的变更
-
为 Ustr 继承 Ord
因此,现在可以按字典顺序对
Vec中的Ustr进行排序。
自 0.5 以来的变更
-
为
&str添加From<Ustr>此
impl使将Ustr传递给期望Into<&str>的方法的函数变得更加容易。
自 0.4 以来的变更
-
添加了对 32 位系统的支持
移除了对 64 位系统的限制,并修复了与指针数学相关的错误。感谢 agaussman 提出 此问题。
-
重新启用 Miri 漏洞检查
感谢 RalfJung 指出 Miri 现在忽略来自静态的 "泄露"。
-
PartialOrd现在是字典序 -
感谢macprog-guy为我们实现了通过将操作委托给
&str的PartialOrd。这将比之前的派生实现要慢,因为之前的实现只是进行了指针比较,但要好得多。
自0.3以来的变更
-
将Miri添加到CI测试中
Miri对代码中的不安全部分进行sanity-check,以防止某些类型的UB。
-
将默认哈希器切换为ahash
Ahash是一个快速的非加密纯Rust哈希器。纯Rust非常重要,以便能够运行Miri,ahash也是我能找到的最快的。可以通过启用
--features=hashcity来获取旧的fasthash/cityhash。
自0.2以来的变更
-
支持Serde
当启用
--features=serialization时,Ustr现在可以使用Serde进行序列化。如果您真的想的话,全局字符串缓存也可以序列化。 -
将默认同步切换为
parking_lot::Mutex由于自旋锁最近受到了一些批评,因此字符串缓存现在使用
parking_lot::Mutex作为默认的同步原语。spin::Mutex仍然可以通过--features=spinlock功能门提供,如果您真的想获得额外的5%速度。 -
清理了
unsafe更好地记录了不安全块的守恒条件,并用checked_add()和类似函数替换了一些盲目的添加,以避免潜在的(但极不可能的)溢出。
-
与
string-cache的比较string-cache提供了一种可以在编译时以及运行时创建的全局缓存。缓存中的动态字符串似乎被引用计数,所以当它们不再使用时将释放,而
Ustr永远不会被删除。创建一个
string_cache::DefaultAtom比创建一个Ustr要慢得多,尤其是在多线程环境中。另一方面,如果您可以在编译时将所有Atom放入二进制文件中,这就不会是问题。 -
与
string-interner的比较string-interner提供了单独的
Interner对象来工作,而不是全局缓存,这可能更加灵活。它比string-cache创建得更快,但仍然比Ustr慢得多。
速度
Ustr的创建速度比string-interner或string-cache要快得多。创建100,000个循环复制的~20,000个路径字符串
/cgi-bin/images/admin
/modules/templates/cache
/libraries/themes/wp-includes
... etc.
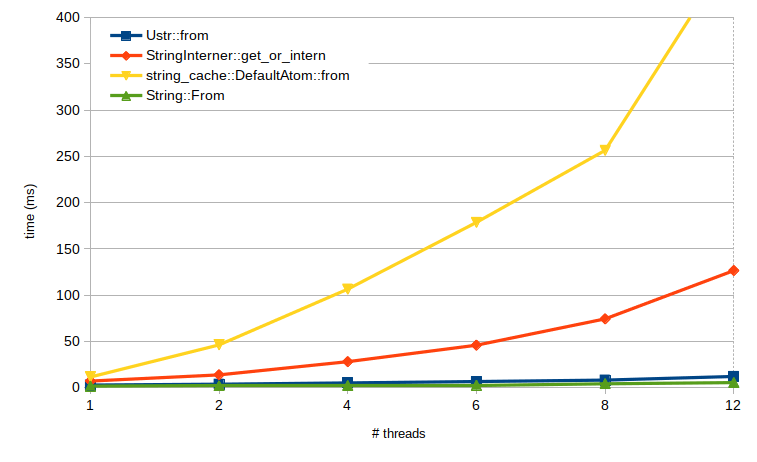
为什么?
在特定类型的某些应用中,通常使用字符串作为标识符,但并不真正对它们进行任何处理。引用来自OIIO的ustring文档
与标准字符串相比,Ustr有几个优点
-
每个单独的
Ustr都非常小——事实上,我们保证Ustr的大小和内存布局与普通*u8相同。 -
存储非常节省,因为在整个程序的生命周期中,每个唯一的字符序列只有一个分配的副本。
-
从一个
Ustr到另一个的赋值仅仅是指针的复制;没有分配,没有字符复制,没有引用计数。 -
等性测试(字符串是否包含相同的字符)是一个单一操作,即指针的比较。
-
内存分配仅在从原始字符构造新的
Ustr时发生,且是第一次 —— 后续相同的字符串构造只需要在规范字符串集中找到它,但不需要分配新的存储。销毁一个Ustr是微不足道的,因为没有解分配,因为规范版本仍然在集中。因此,用户代码的错误也不会导致内存泄漏。但也有一些问题。规范字符串永远不会从表中释放。因此,从某种意义上说,所有字符串都“泄漏”,但它们只为程序遇到的每个唯一字符串泄漏一个副本。创建一个
Ustr比在单线程上使用String::from()更慢,如果尝试在多线程的紧密循环中创建许多Ustr,由于全局缓存的锁竞争,性能会更差。
总的来说,Ustr 是一个真正优秀的字符串表示
-
如果你倾向于有(相对)少量唯一的字符串,但有这些字符串的许多副本;
-
如果你倾向于反复创建相同的字符串,并且在整个程序生命周期中,单个唯一字符序列只被使用一次的情况相对较少; — 如果你最常见的字符串操作是赋值和等性测试,并且你希望它们尽可能快;
-
如果你进行相对较少的字符串逐字符组装、字符串连接或其他“字符串操作”(除了等性测试)。
Ustr 不是那么好
-
如果你的程序在整个生命周期中每个字符序列的副本非常少;
-
如果你的程序在其生命周期中倾向于生成大量的唯一字符串,每个字符串只使用很短的时间,然后被丢弃,以后再也不会用到;
-
如果你不需要做很多字符串赋值或等性测试,但有很多更复杂的字符串操作。
安全和兼容性
此包包含大量不安全但使用已检查且文档齐全。它也是 CI 流程的一部分,通过 Miri 运行。
我在 64 位系统上经常使用它,它也在 32 位系统上通过了 Miri,但 32 位不是定期检查。如果你想在 32 位上使用它,请确保运行 Miri 并在发现问题后打开和提交问题。
许可
BSD+ 许可证
版权所有 © 2019—2020 Anders Langlands
重新分发和使用源代码和二进制代码,无论是否修改,只要满足以下条件
-
源代码的重新分发必须保留上述版权声明、本条件和以下免责声明。
-
二进制形式的重新分发必须在文档和/或其他提供的材料中重新生产上述版权声明、本条件和以下免责声明。
根据本许可证的条款和条件,每个版权所有者和贡献者特此授予本许可证下获得权利的人一个永久的、全球的、非排他的、免费、无需付费、不可撤销的(但未满足本许可证的条件除外)专利许可,以制造、制造、使用、提出销售、销售、进口和以其他方式转让本软件,该许可仅适用于以下专利权要求,已由该版权所有者或贡献者获得或以后获得,并可由该版权所有者或贡献者许可,因以下原因而必然侵犯:
(a)他们的贡献(版权所有者的许可版权和非版权性添加的贡献者,以源代码或二进制代码形式);或
(b)将贡献与版权所有者或贡献者添加到其中的作品结合,如果,在添加贡献时,这种结合必然侵犯版权。专利许可不适用于包括贡献的任何其他组合。
除非本许可中明确声明,否则不授予任何版权所有者或贡献者的权利或许可,无论是明示的、暗示的、禁止的或其他方式。
免责声明
本软件由版权所有者和贡献者提供“现状”且不提供任何明示或暗示的保证,包括但不限于对适销性和特定用途的适用性的暗示保证。在任何情况下,版权所有者或贡献者均不对任何直接、间接、偶然、特殊、示范性或后果性的损害(包括但不限于替代货物或服务的采购;使用、数据或利润的损失;或业务中断)承担责任,无论损害是否由使用本软件引起,无论基于合同、严格责任或侵权(包括疏忽或任何其他)理论,即使被告知此类损害的可能性。
包含从OpenImageIO移植的代码,BSD 3条款许可证。
包含Max Woolf的Big List of Naughty Strings的副本,MIT许可证。
包含来自SecLists的一些字符串,MIT许可证。
依赖项
~0.5–5.5MB
~17K SLoC