3 个不稳定版本
使用旧的 Rust 2015
| 0.2.1 | 2021 年 2 月 9 日 |
|---|---|
| 0.2.0 | 2021 年 2 月 9 日 |
| 0.1.0 | 2016 年 12 月 31 日 |
#1275 在 数据库接口
1MB
806 行
UniParc XML 解析器
![]()
![]()
简介
将来自 UniProt 网站 下载的 UniParc XML 文件 (uniparc_all.xml.gz) 解析成可以加载到关系型数据库的 CSV 文件。
用法
可以将未压缩的 XML 数据通过管道输入到 uniparc_xml_parser 中,以
$ curl -sS ftp://ftp.uniprot.org/pub/databases/uniprot/current_release/uniparc/uniparc_all.xml.gz \
| zcat \
| uniparc_xml_parser
输出是一组 CSV (或更具体地说,TSV) 文件
$ ls
-rw-r--r-- 1 user group 174G Feb 9 13:52 xref.tsv
-rw-r--r-- 1 user group 149G Feb 9 13:52 domain.tsv
-rw-r--r-- 1 user group 138G Feb 9 13:52 uniparc.tsv
-rw-r--r-- 1 user group 107G Feb 9 13:52 protein_name.tsv
-rw-r--r-- 1 user group 99G Feb 9 13:52 ncbi_taxonomy_id.tsv
-rw-r--r-- 1 user group 74G Feb 9 20:13 uniparc.parquet
-rw-r--r-- 1 user group 64G Feb 9 13:52 gene_name.tsv
-rw-r--r-- 1 user group 39G Feb 9 13:52 component.tsv
-rw-r--r-- 1 user group 32G Feb 9 13:52 proteome_id.tsv
-rw-r--r-- 1 user group 15G Feb 9 13:52 ncbi_gi.tsv
-rw-r--r-- 1 user group 21M Feb 9 13:52 pdb_chain.tsv
-rw-r--r-- 1 user group 12M Feb 9 13:52 uniprot_kb_accession.tsv
-rw-r--r-- 1 user group 656K Feb 9 04:04 uniprot_kb_accession.parquet
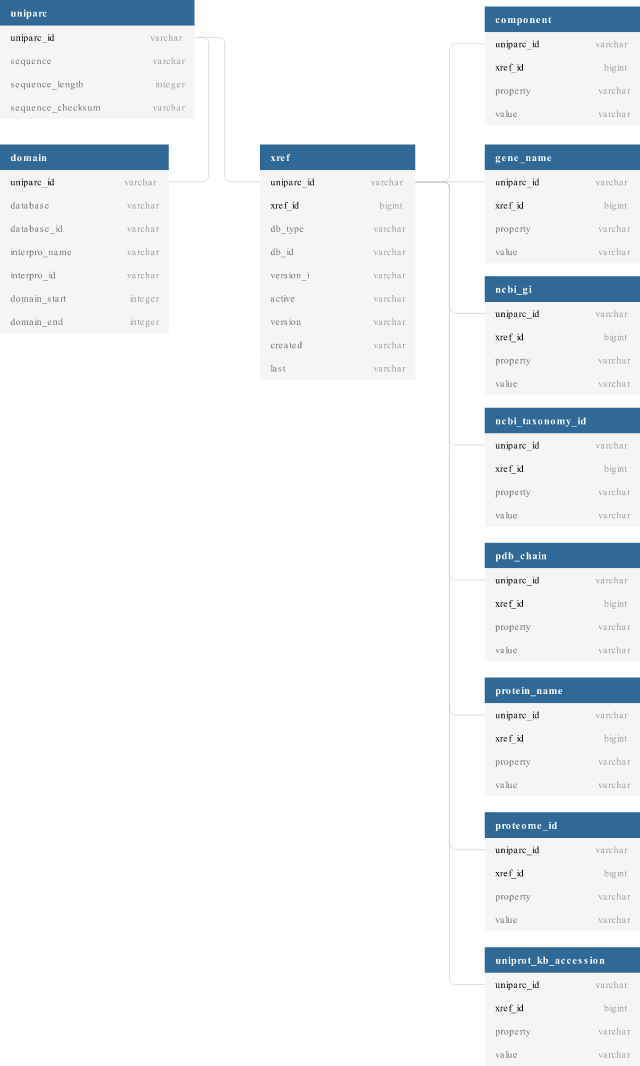
表架构
生成的 CSV 文件符合以下架构
安装
二进制文件
Linux 二进制文件可在以下网址获取: https://gitlab.com/ostrokach/uniparc_xml_parser/-/packages。
Cargo
使用 cargo 编译和安装 uniparc_xml_parser 以适用于您的目标平台
cargo install uniparc_xml_parser
Conda
使用 conda 安装预编译的二进制文件
conda install -c ostrokach-forge uniparc_xml_parser
输出文件
Parquet
包含处理数据的 Parquet 文件可在以下 URL 获取,并且每月更新一次: http://uniparc.data.proteinsolver.org/。
Google BigQuery
也可以直接使用 Google BigQuery 查询数据: https://console.cloud.google.com/bigquery?project=ostrokach-data&p=ostrokach-data&page=dataset&d=uniparc。
基准测试
解析 10,000 个 XML 条目大约需要 30 秒(该过程主要受 I/O 限制)
$ time bash -c "zcat uniparc_top_10k.xml.gz | uniparc_xml_parser >/dev/null"
real 0m33.925s
user 0m36.800s
sys 0m1.892s
实际的 uniparc_all.xml.gz 文件大约有 373,914,570 个元素。
路线图
- 在整个过程中始终保持字节。
常见问题解答 (FAQ)
为什么不将 uniparc_all.xml.gz 分割成多个小文件并并行处理它们呢?
- 分割文件需要读取整个文件。如果我们无论如何都要读取整个文件,为什么不边读边解析它呢?
- 拥有一个解析
uniparc_all.xml.gz的单一过程,使得创建增量唯一索引列(例如xref.xref_id)更加容易。
常用查询 (FUQ)
待办事项
依赖项
~9.5MB
~240K SLoC