8 个重大版本
| 0.10.0 | 2020年7月18日 |
|---|---|
| 0.8.0 | 2020年6月1日 |
| 0.7.0 | 2020年3月30日 |
| 0.2.0 | 2019年12月31日 |
#14 in #buffers
在 tree-buf 中使用
29KB
553 行
什么是 Tree-Buf?
Tree-Buf 是为现实世界数据构建的数据导向、数据驱动的序列化器。
- 优于 GZip 压缩,比其他未压缩格式更快
- 自描述文件,无需模式即可读取
- 灵活的格式支持 Rust 风格的枚举等更多功能
基准测试
Tree-Buf 与 GraphQL 的 MessagePack
此测试比较了包含 1000 个实体和多个不同类型的字段的复杂 GraphQL 响应的序列化。
| 字节大小 | 往返 CPU 时间 | |
|---|---|---|
| Message Pack | 242558 | 1303µs |
| Tree-Buf | 13545 | 608µs |
与 Message Pack 相比,Tree-Buf 的压缩大小小于 1/17,但读取和写入的时间少于 1/2。
实体看起来像这样
{
"createdAt": "1582140851",
"nft": {
"bids": [{
"bidder": "0x8a9d9b361dca26afecaf9d64f6b6e335e1b7df8a",
"blockNumber": "9521798",
"status": "open"
}],
"searchIsLand": false,
"searchIsWearableAccessory": false,
"wearable": {
"bodyShapes": ["BaseFemale"],
"category": "feet",
"collection": "halloween_2019",
"name": "Bee Suit Shoes",
"owner": { "mana": "0" },
"rarity": "epic",
"representationId": "bee_suit_feet"
}
},
"price": "200000000000000000000",
"status": "cancelled"
},
Tree-Buf 与 GeoJson
此测试比较了包含每个国家多边形和多边形几何形状的 Feature Collection 的 GeoJson 文件的序列化。
| 字节大小 | 往返 CPU 时间 | |
|---|---|---|
| GeoJson | 24090863 | 407ms |
| Tree-Buf | 6865300 | 39ms |
| Tree-Buf 1m | 2268041 | 41ms |
在此测试中,Tree-Buf 的速度比 GeoJson 快 10 倍,同时生成的文件大小是 GeoJson 的 2/7。
还有一个关于 "Tree-Buf 1m" 的条目。在这里,已指定编译时选项,允许 Tree-Buf 使用有损浮点压缩技术。代码:tree_buf::experimental::encode_with_options(data, &encode_options! { options::LossyFloatTolerance(-12) })。12 位二进制精度优于经纬度点的 1 米精度。这导致文件大小仅为 GeoJson 的 1/10,同时不牺牲速度。
我们可以尝试的另一件事是使用修改过的模式选择性地加载数据的一部分。如果我们指示Tree-Buf只从文件中加载国家名称和其他属性,而不加载它们的几何形状,这需要240µs - 比以GeoJson形式加载数据快1500多倍,因为Tree-Buf不需要解析不需要加载的字段,而Json需要解析这些数据才能跳过。
Tree-Buf与CSV和Tableau Hyper在统计方面的比较
BOSS(棒球开源软件)正在使用Tree-Buf存储棒球统计数据。这些是WIP的初步结果。
| 大小 | |
|---|---|
| CSV | 4577MiB |
| Tableau Hyper | 665MiB |
| Tree-Buf | 219MiB |
在这种情况下,Tree-Buf的大小比CSV小1/20。
警告!
Tree-Buf处于早期开发阶段,格式正在迅速变化。在生产中使用Tree-Buf可能不是一个好主意。如果您确实这样做,请确保进行大量测试,并准备好在格式的每个主要版本上进行数据迁移。我对您使用Tree-Buf的糟糕选择不承担责任。
开始使用Tree-Buf
虽然Tree-Buf格式与语言无关,但它目前仅适用于Rust。
步骤1:将最新版本的Tree-Buf添加到您的cargo.toml
[dependencies]
tree-buf = "0.8.0"
步骤2:在您的结构体上推导Encode和/或Decode。
use tree_buf::prelude::*;
#[derive(Encode, Decode, PartialEq)]
pub struct Data {
pub id: u32,
pub vertices: Vec<(f64, f64, f64)>,
pub extra: Option<String>,
}
步骤3:在您的数据上调用encode和/或decode。
pub fn round_trip() {
// Make some data
let data = Data {
id: 1,
vertices: vec! [
(10., 10., 10.),
(20., 20., 20.)
],
extra: String::from("Fast"),
};
// Encode to Vec<u8>
let bytes = encode(&data);
// Decode from &[u8]
let copy = decode(&bytes).unwrap();
// Success!
assert_eq!(©, &data);
}
完成!您已经掌握了Tree-Buf的使用。
其他技巧
分析数据大小
Tree-Buf使您能够轻松地了解数据是如何被压缩的,以及您可以进行哪些优化。例如,在GraphQL基准测试中,我们可以运行
let sizes = tree_buf::experimental::stats::size_breakdown(&tb_bytes);
println!("{}", sizes.unwrap());
它将打印
Largest by path:
32000
data.orders.[1000].id.[32]
Object.Object.Array.Object.Array Fixed.U8 Fixed
5000
data.orders.[1000].createdAt
Object.Object.Array.Object.Prefix Varint
5000
data.orders.[1000].price
Object.Object.Array.Object.Prefix Varint
2836
data.orders.[1000].nft.wearable.representationId.values
Object.Object.Array.Object.Object.Object.Dictionary.UTF-8
2452
data.orders.[1000].nft.wearable.name.values
Object.Object.Array.Object.Object.Object.Dictionary.UTF-8
952
data.orders.[1000].nft.wearable.representationId.indices
Object.Object.Array.Object.Object.Object.Dictionary.Simple16
948
data.orders.[1000].nft.wearable.name.indices
Object.Object.Array.Object.Object.Object.Dictionary.Simple16
420
data.orders.[1000].nft.wearable.category.discriminants
Object.Object.Array.Object.Object.Object.Enum.Simple16
356
data.orders.[1000].nft.wearable.collection.indices
Object.Object.Array.Object.Object.Object.Dictionary.Simple16
288
data.orders.[1000].nft.wearable.rarity.discriminants
Object.Object.Array.Object.Object.Object.Enum.Simple16
268
data.orders.[1000].status.discriminants
Object.Object.Array.Object.Enum.Simple16
236
data.orders.[1000].nft.wearable.bodyShapes.values.discriminants
Object.Object.Array.Object.Object.Object.Array.Enum.Packed Boolean
120
data.orders.[1000].nft.wearable.bodyShapes.len.runs
Object.Object.Array.Object.Object.Object.Array.RLE.Simple16
85
data.orders.[1000].nft.wearable.collection.values
Object.Object.Array.Object.Object.Object.Dictionary.UTF-8
60
data.orders.[1000].nft.wearable.bodyShapes.len.values
Object.Object.Array.Object.Object.Object.Array.RLE.Simple16
2
data.orders.[1000].nft.wearable.owner.mana.runs
Object.Object.Array.Object.Object.Object.Object.Bool RLE.Prefix Varint
Largest by type:
1x 32000 @ U8 Fixed
3x 10002 @ Prefix Varint
3x 5373 @ UTF-8
8x 3412 @ Simple16
1x 236 @ Packed Boolean
Other: 400
Total: 51423
易语言互操作
Tree-Buf具有规范字段名称。这意味着您可以说再见Rust中的#[serde(rename = "")],C#中的[JsonProperty("")]和JavaScript中的lint警告。这些在Tree-Buf中是等效的架构。
// C#
class Klass {
public double FieldName;
}
// TypeScript
class Klass {
fieldName: number
}
// Rust
struct Klass {
field_name: f64
}
Tree-Buf内部
Tree-Buf是如何实现现实世界数据的快速压缩和序列化的?
- 将文档组织成树/分支数据模型,将相关数据聚集在一起。
- 使用最先进的压缩技术,该技术仅适用于原始数据类型的类型化向量。
- 分摊自描述架构的成本。
具体来说,跟踪一个使用现实世界数据的示例会有所帮助。我们将查看数据,了解它如何映射到Tree-Buf数据模型,然后查看Tree-Buf如何对结果模型的每个部分进行压缩。
假设我们想要存储围棋循环赛的全部比赛记录。为了跟上,您不需要了解游戏。只需知道它是在一个19x19的网格上玩的,玩家轮流在棋盘的交叉点上放置黑白棋子。它看起来像这样

以下是这些记录游戏的简化架构。
struct Tournament {
games: Vec<Game>,
champion: String,
}
struct Game {
player_white: String,
player_black: String,
moves: Vec<Move>,
result: Result,
}
struct Move {
time_seconds: u32,
coordinate: (u8, u8),
}
enum Result {
Score(f32),
Resignation(String),
}
以下是该架构中的示例数据,以JSON格式给出...
{
"champion": "Lee Changho",
"games": [
{
"white": "Honinbo Shusai",
"black": "Go Seigen",
"moves": [
{
"time_seconds": 4,
"coordinate": [16, 2],
},
{
"time_seconds": 9,
"coordinate": [2, 3],
},
"Followed by 246 more moves from the first game",
],
"result": 1.5,
},
"Followed by 119 more games from the tournament",
]
}
Tree-Buf数据模型
Tree-Buf将每个从根到架构的路径视为树的一个分支。
以下是我们架构的分解图示
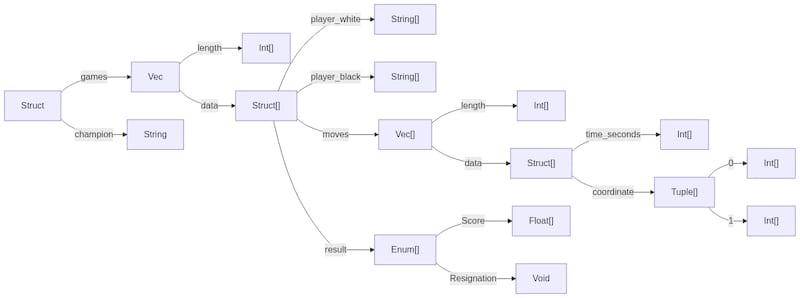
每个分支存储了通过该路径在架构中可访问的所有数据,按照在文档中出现的顺序。
例如,存在一个位于 ->games->data->moves->data->time_seconds 的 Int[] 分支。这个分支是一个 [],因为它存储了整个比赛中所有游戏的所有移动的时间样本。例如:[4, 9, ... 246 更多第一场比赛的时间样本,... 第二场比赛到最后一场比赛的时间样本]。
同样,所有游戏通过路径 ->games->data->moves->data->coordinate->0 的 x 坐标是连续存储的:[16, 2, ... 等等]
压缩 Tree-Buf 模型
现实世界的数据表现出模式。如果你的数据没有表现出某种模式,那么它可能不是很有趣。
Tree-Buf 数据模型将相关数据聚类在一起,以便利用高度优化的压缩库中的数据模式。
例如,time_seconds 字段中的值不是随机的。它们是单调递增的,通常以固定的速率,因为游戏往往会以一定的节奏进行,偶尔会减速。Tree-Buf 中的整数压缩可以利用这一点。通过利用,例如,差分编码 + Simple16,值通常可以用不到一个字节来表示。
围棋中的坐标也不是随机的。围棋中的一步很可能位于与上一步相同的象限,或者甚至紧邻上一步。同样,利用,例如,差分编码 + Simple16 可以将同一象限内的一系列相邻移动压缩到约每个坐标分量 2-3 位。在这里,Tree-Buf 数据模型将 x 和 y 坐标拆分到单独的分支中是至关重要的,因为这些值独立于彼此聚类。交错 x 和 y 坐标会使整数压缩库看起来更加随机。
甚至玩家的名字也不是随机的。因为16名玩家之间的循环赛需要120场比赛,所以玩家的名字高度冗余。在这里,我们也可以跟踪最近写入的哪些字符串,并引用给定列表中的先前字符串。在其他格式中,玩家的名字可能在最终序列化的文档中相隔很远,这使得gzip等通用压缩难以找到这些模式。
将这些添加到枚举、元组、可空和少数其他技巧的第一类支持中,可以带来显著的成果。
所有这些压缩在 Tree-Buf 中都是在幕后发生的,无需开发者进行任何工作,也不需要修改架构。
与其他格式的压缩结果比较
让我们将这些结果与另一种流行的二进制格式Protobuf 3进行比较,以了解这种许多小胜利的累积所造成的影响。目前,我们只考虑移动向量,因为这是数据中最大的部分。Protobuf中的每个移动都是一个消息。Protobuf中的每个消息都是长度定界的,需要1个字节。在游戏时钟开始的第2分钟7秒后,每个time_seconds需要2个字节用于LEB128编码的值和1个字节用于字段id - 3个字节。对于坐标字段,我们可以作弊并使用紧凑数组来实现。这并不完全符合数据模型,但会比嵌入消息需要的字节更少。紧凑数组需要1个字节用于字段id,1个字节用于长度前缀,以及两个值各需要1个字节。把这些加起来,每个移动需要7个字节,即56位。
根据游戏的不同,Tree-Buf平均可能只需要每个移动17位。坐标变化大约需要4.5位,时间变化(最多2分钟7秒)大约需要8位或更少。也就是说,与Tree-Buf相比,移动列表在Protobuf 3中需要大约3.3倍的空间(17位 * 3.3 = 56位)。
与JSON相比呢?每个移动17位可以得到... "t - 并不是 "time_seconds":。完整的、压缩的移动需要336位,是Tree-Buf的19倍。
特别感谢
JetBrains非常慷慨,允许这个项目免费使用它们的所有工具。我在使用带有Rust插件的CLion进行Tree-Buf开发,但也享受使用他们其他工具,如dotMemory,在其他项目上的使用。请在这里查看:JetBrains.com
依赖关系
~1.5MB
~38K SLoC