5 个不稳定版本
| 新版本 0.3.0 | 2024 年 8 月 23 日 |
|---|---|
| 0.2.0 | 2024 年 1 月 30 日 |
| 0.1.2 | 2024 年 1 月 27 日 |
| 0.1.1 | 2024 年 1 月 7 日 |
| 0.1.0 | 2024 年 1 月 6 日 |
338 在 调试 中
每月 4,020 次下载
140KB
900 行
tracing-durations-export
![]()
![]()
一个跟踪层,用于确定哪些任务正在并行运行,哪些被 cpu 阻塞,主要用于 cli 应用程序。
从开始到结束的每个范围都是一个蓝色条带。异步范围可以是活动的或产生并等待(跟踪文档中的详细信息),只有在范围活动的情况下,我们才在它上方绘制一个橙色部分。同步范围始终是活动的,因此它们的蓝色和橙色区域相同。颜色越深,同一名称的范围同时活动越多。
下面的示例图是通过 cached_network.rs 生成的,有四个部分。第一部分显示顺序发送网络请求并解析响应,第二部分显示相同的逻辑但使用 buffer_unordered 并行化。您可以看到请求是如何并行的,以及解析何时开始。第三和第四部分是一个更复杂的示例,我们首先检查缓存然后再发出网络请求。

在浏览器中打开 svg,将鼠标悬停在部分上以获取详细的时间和字段信息。
多车道选项提供了一种更详细的视图,显示每个单独的范围
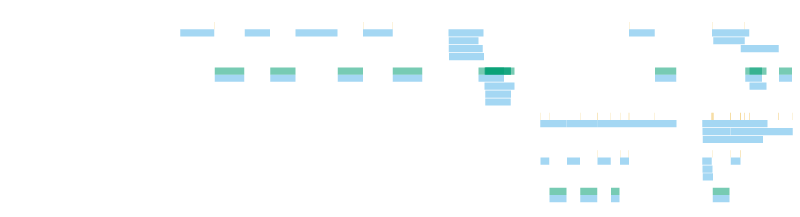
这些图与CPU分析器(如perf或sample)互补,并查看原始跨度持续时间。它们不会给你精确的按行工作分解,而是告诉你CPU在哪里阻止或延迟其他工作,以及CPU在空闲等待更多并行性时的情况。
使用方法
use std::fs::File;
use std::io::BufWriter;
use tracing_durations_export::DurationLayer;
use tracing_subscriber::layer::SubscriberExt;
use tracing_subscriber::{registry::Registry, fmt};
fn setup_global_subscriber() -> DurationsLayerDropGuard {
let fmt_layer = fmt::Layer::default();
let (duration_layer, guard) = DurationsLayerBuilder::default()
.durations_file("traces.ndjson")
// Available with the `plot` feature
// .plot_file("traces.svg")
.build()
.unwrap();
let subscriber = tracing_subscriber::registry()
.with(fmt_layer)
.with(duration_layer)
.init();
guard
}
// your code here ...
您可以使用plot功能并在构建器上设置.plot_file(),或者运行您的应用程序后,运行
cargo run --bin plot --features plot --features cli -- traces.ndjson
并打开traces.svg。
对于README开头处的图表
TRACING_DURATION_EXPORT=examples/cached_network.ndjson cargo run --example cached_network
cargo run --bin plot --features plot --features cli -- examples/cached_network.ndjson
cargo run --bin plot --features plot --features cli -- --multi-lane examples/cached_network.ndjson --output examples/cached_network_multi_lane.svg
输出文件traces.ndjson将类似于以下内容,其中每个活动跨度所在的区域是一行。
[...]
{"id":6,"name":"read_cache","start":{"secs":0,"nanos":122457871},"end":{"secs":0,"nanos":122463135},"parents":[5],"fields":{"id":"2"}}
{"id":5,"name":"cached_network_request","start":{"secs":0,"nanos":122433854},"end":{"secs":0,"nanos":122499689},"parents":[],"fields":{"id":"2","api":"https://example.net/cached"}}
{"id":9007474132647937,"name":"parse_cache","start":{"secs":0,"nanos":122625724},"end":{"secs":0,"nanos":125791908},"parents":[],"fields":{}}
{"id":5,"name":"cached_network_request","start":{"secs":0,"nanos":125973025},"end":{"secs":0,"nanos":126007737},"parents":[],"fields":{"id":"2","api":"https://example.net/cached"}}
{"id":5,"name":"cached_network_request","start":{"secs":0,"nanos":126061739},"end":{"secs":0,"nanos":126066912},"parents":[],"fields":{"id":"2","api":"https://example.net/cached"}}
{"id":2251799813685254,"name":"read_cache","start":{"secs":0,"nanos":126157156},"end":{"secs":0,"nanos":126193547},"parents":[2251799813685253],"fields":{"id":"3"}}
{"id":2251799813685253,"name":"cached_network_request","start":{"secs":0,"nanos":126144140},"end":{"secs":0,"nanos":126213181},"parents":[],"fields":{"api":"https://example.net/cached","id":"3"}}
{"id":27021597764222977,"name":"make_network_request","start":{"secs":0,"nanos":128343009},"end":{"secs":0,"nanos":128383121},"parents":[13510798882111491],"fields":{"api":"https://example.net/cached","id":"0"}}```
[...]
请注意,0是第一个跨度的时间,而不是进程的开始。
案例研究
这是一个来自依赖关系解析器uv的例子。我们猜测适合用户约束的版本,然后必须获取这些版本的元数据以检查这些版本是否兼容。在这个特定案例中,我们必须为两个名为boto3和botocoro的包尝试很多版本。以前,尝试会顺序发生
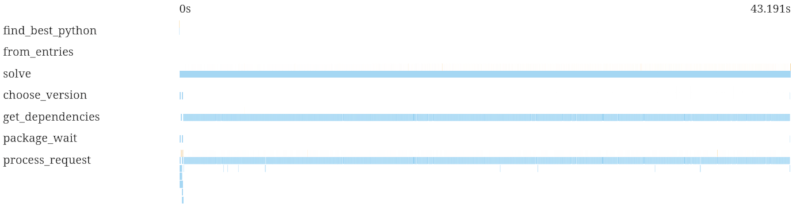
我们可以通过猜测来优化这一点:我们猜测可能适合哪些版本,以及如果那不起作用,我们将尝试下一个什么版本,并并行获取(拉取请求)
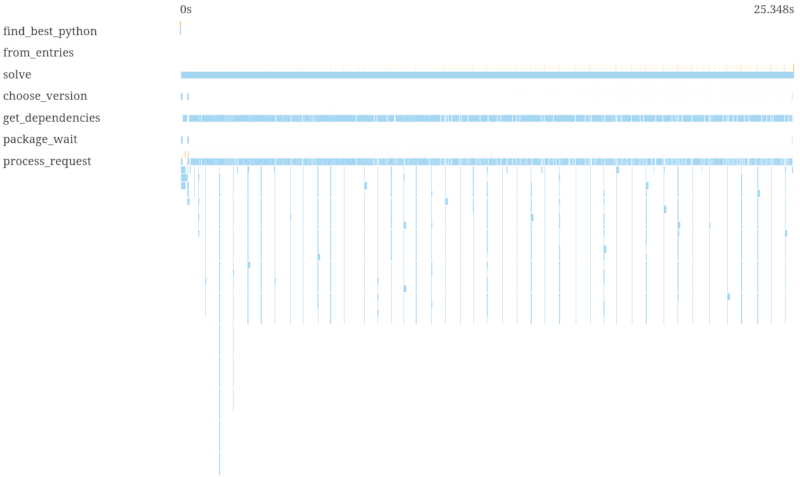
这更快,但您可以看到我们有一些并行阶段,其中包含顺序区域。在浏览器中悬停在svg版本中的跨度上,我们可以看到我们只是在并行预取boto3,而没有预取botocore。通过一个预取两者的修复
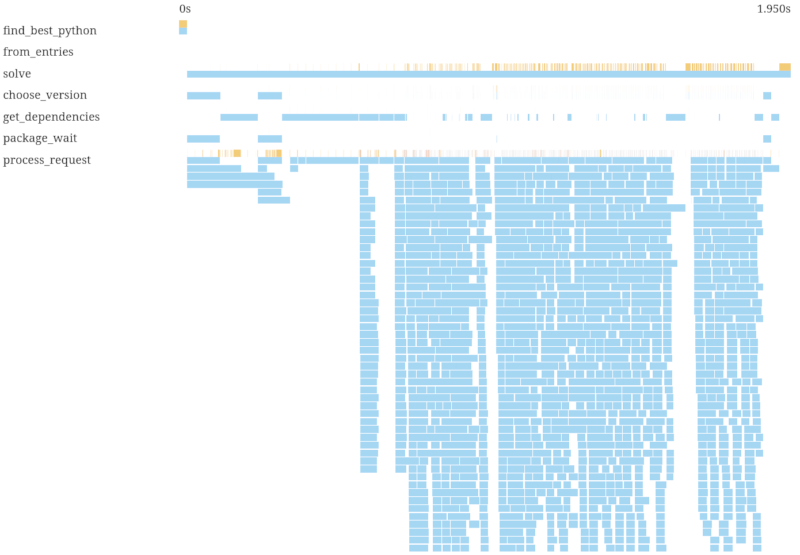
现在我们只需要2秒而不是43秒,所以初始部分扩展了,但您主要可以看到我们现在高度并行。
另一个案例研究是这个拉取请求,其中我们用一个异步通道替换了一个同步通道,释放了并行性。您也可以看到spawn_blocking的影响。
依赖项
~1.9–3.5MB
~61K SLoC