1 个不稳定版本
| 0.1.0 | 2024年3月11日 |
|---|
#323 in 文件系统
65KB
888 代码行
topcat
topological concatenation of files
描述
topcat 是一个简单的工具,用于按拓扑顺序连接文件。当您有一组相互依赖的文件,并且希望按正确顺序连接它们时,它非常有用。
对于我的用例,这是 SQL 文件。
我喜欢将我的 SQL 文件视为相互依赖的函数和视图集合。我喜欢将它们保存在单独的文件中,并按正确顺序连接它们,以创建一个可以在我的数据库中运行的单一文件。
用法
假设您有一个包含以下文件的目录
sql
├── my_other_schema
│ ├── functions
│ │ ├── a.sql
│ │ ├── b.sql
│ │ └── c.sql
│ └── schema.sql
└── my_schema
├── functions
│ └── a.sql
└── schema.sql
文件内容如下
sql/my_schema/schema.sql:
-- name: my_schema
DROP SCHEMA IF EXISTS my_schema CASCADE;
CREATE SCHEMA IF NOT EXISTS my_schema;
sql/my_schema/functions/a.sql:
-- name: my_schema.a
-- dropped_by: my_schema
CREATE FUNCTION my_schema.a() RETURNS INT AS
$$
SELECT 1;
$$ LANGUAGE SQL IMMUTABLE
PARALLEL SAFE;
sql/my_schema/functions/b.sql:
-- name: my_schema.b
-- dropped_by: my_schema
-- requires: my_schema.a
CREATE FUNCTION my_schema.b() RETURNS INT AS
$$
SELECT my_schema.a() + 1
$$ LANGUAGE SQL;
sql/my_schema/functions/c.sql:
-- name: my_schema.c
-- dropped_by: my_schema
-- requires: my_schema.b
CREATE FUNCTION my_schema.c() RETURNS INT AS
$$
SELECT my_schema.b() + 1
$$ LANGUAGE SQL IMMUTABLE
PARALLEL SAFE;
sql/my_other_schema/schema.sql:
-- name: my_other_schema
DROP SCHEMA IF EXISTS my_schema CASCADE;
CREATE SCHEMA IF NOT EXISTS my_schema;
sql/my_other_schema/functions/a.sql:
-- name: my_other_schema.a
-- dropped_by: my_other_schema
-- requires: my_schema.b
CREATE FUNCTION my_other_schema.a() RETURNS INT AS
$$
SELECT my_schema.b() + 1
$$ LANGUAGE SQL IMMUTABLE
PARALLEL SAFE;
因此,依赖图如下: 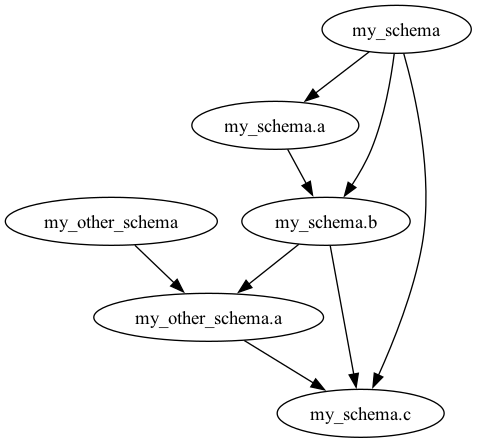
现在您可以运行 topcat 以按正确顺序连接文件
topcat -i tests/input/sql -o tests/output/sql/output.sql
output.sql 的内容将是
-- This file was generated by topcat. To regenerate run:
--
-- topcat -i tests/input/sql -o tests/output/sql/output.sql -v
------------------------------------------------------------------------------------------------------------------------
-- tests/input/sql/my_other_schema/schema.sql
-- name: my_schema
DROP SCHEMA IF EXISTS my_schema CASCADE;
CREATE SCHEMA IF NOT EXISTS my_schema;
------------------------------------------------------------------------------------------------------------------------
-- tests/input/sql/my_other_schema/functions/a.sql
-- name: my_schema.a
-- dropped_by: my_schema
CREATE FUNCTION my_schema.a() RETURNS INT AS
$$
SELECT 1;
$$ LANGUAGE SQL;
------------------------------------------------------------------------------------------------------------------------
-- tests/input/sql/my_other_schema/functions/b.sql
-- name: my_schema.b
-- dropped_by: my_schema
-- requires: my_schema.a
CREATE FUNCTION my_schema.b() RETURNS INT AS
$$
SELECT my_schema.a() + 1
$$ LANGUAGE SQL;
------------------------------------------------------------------------------------------------------------------------
-- tests/input/sql/my_schema/schema.sql
-- name: my_other_schema
DROP SCHEMA IF EXISTS my_other_schema CASCADE;
CREATE SCHEMA IF NOT EXISTS my_other_schema;
------------------------------------------------------------------------------------------------------------------------
-- tests/input/sql/my_schema/functions/a.sql
-- name: my_other_schema.a
-- dropped_by: my_other_schema
-- requires: my_schema.b
CREATE FUNCTION my_other_schema.a() RETURNS INT AS
$$
SELECT my_schema.b() + 1
$$ LANGUAGE SQL IMMUTABLE
PARALLEL SAFE;
------------------------------------------------------------------------------------------------------------------------
-- tests/input/sql/my_other_schema/functions/c.sql
-- name: my_schema.c
-- dropped_by: my_schema
-- requires: my_schema.b
-- requires: my_other_schema.a
CREATE FUNCTION my_schema.c() RETURNS INT AS
$$
SELECT my_schema.b() + my_other_schema.a() + 1
$$ LANGUAGE SQL;
依赖项
~8.5MB
~139K SLoC