1 个不稳定版本
| 0.4.0 | 2024年4月17日 |
|---|
#227 在 嵌入式开发
70KB
1.5K SLoC
是 core::fmt 的一个小巧、快速且无恐慌的替代品
tfmt 的开发基础是 japaric 的 ufmt。所有主要思想和概念都来自那里。然而,作者明确指出,浮点数的表示和填充不是实现的重点。对于某些项目,这些点恰好很重要。
设计目标
- 针对小型嵌入式系统进行大小和速度优化
- 可在开发和运行时使用
Debug和Display - 在优化后的代码中,没有引发恐慌的分支
- 易于集成额外的数据类型
功能
- 包括以下数据类型的字符串转换和格式化选项
- u8, u16, u32, u64, u128, usize
- i8, i16, i32, i64, i128, isize
- bool, str, char
- f32, f64
- [
#[derive(uDebug)]][macro@derive] uDebug和uDisplay特性,如 core::fmt::Debug 和 core::fmt::Display- [uDisplayPadded] 特性用于格式化输出
- [uDisplayFormatted] 特性用于复杂格式化输出
- [uformat] 宏用于简单地生成字符串
限制
tfmt 的功能远少于 core::fmt。例如
- 没有命名参数
- 没有浮点数的指数表示
- 浮点数的数字范围有限(见
tests/float.rs) - 数组元素的最大数量为32个 [
#[derive(uDebug)]][macro@derive] - 元组的最大元素数量为12个 [
#[derive(uDebug)]][macro@derive] - 不支持联合 [
#[derive(uDebug)]][macro@derive]
示例
格式化标准Rust类型
use tfmt::uformat;
assert_eq!(
uformat!(100, "The answer to {} is {}", "everything", 42).unwrap().as_str(),
"The answer to everything is 42"
);
assert_eq!("4711", uformat!(100, "{}", 4711).unwrap().as_str());
assert_eq!("00004711", uformat!(100, "{:08}", 4711).unwrap().as_str());
assert_eq!(" -4711", uformat!(100, "{:8}", -4711).unwrap().as_str());
assert_eq!("-4711 ", uformat!(100, "{:<8}", -4711).unwrap().as_str());
assert_eq!(" 4711 ", uformat!(100, "{:^8}", 4711).unwrap().as_str());
assert_eq!("1ab4", uformat!(100, "{:x}", 0x1ab4).unwrap().as_str());
assert_eq!(" 1AB4", uformat!(100, "{:8X}", 0x1ab4).unwrap().as_str());
assert_eq!("0x1ab4", uformat!(100, "{:#x}", 0x1ab4).unwrap().as_str());
assert_eq!("00001ab4", uformat!(100, "{:08x}", 0x1ab4).unwrap().as_str());
assert_eq!("0x001ab4", uformat!(100, "{:#08x}", 0x1ab4).unwrap().as_str());
assert_eq!("0b010010", uformat!(100, "{:#08b}", 18).unwrap().as_str());
assert_eq!("0o011147", uformat!(100, "{:#08o}", 4711).unwrap().as_str());
assert_eq!("3.14", uformat!(100, "{:.2}", 3.14).unwrap().as_str());
assert_eq!(" 3.14", uformat!(100, "{:8.2}", 3.14).unwrap().as_str());
assert_eq!("3.14 ", uformat!(100, "{:<8.2}", 3.14).unwrap().as_str());
assert_eq!(" 3.14 ", uformat!(100, "{:^8.2}", 3.14).unwrap().as_str());
assert_eq!("00003.14", uformat!(100, "{:08.2}", 3.14).unwrap().as_str());
assert_eq!("hello", uformat!(100, "{}", "hello").unwrap().as_str());
assert_eq!(" true ", uformat!(100, "{:^8}", true).unwrap().as_str());
assert_eq!("c ", uformat!(100, "{:<8}", 'c').unwrap().as_str());
使用Derive uDebug
use tfmt::{uformat, derive::uDebug};
#[derive(uDebug)]
struct S1Struct {
f: f32,
b: bool,
sub: S2Struct,
}
#[derive(uDebug)]
struct S2Struct {
tup: (i16, f32),
end: [u16; 2],
}
let s2 = S2Struct { tup: (-4711, 3.14), end: [1, 2] };
let s1 = S1Struct { f: 1.0, b: true, sub: s2 };
let s = uformat!(200, "{:#?}", &s1).unwrap();
assert_eq!(
s.as_str(),
"S1Struct {
f: 1.000,
b: true,
sub: S2Struct {
tup: (
-4711,
3.140,
),
end: [
1,
2,
],
},
}");
let s = uformat!(200, "{:?}", &s1).unwrap();
assert_eq!(
s.as_str(),
"S1Struct { f: 1.000, b: true, sub: S2Struct { tup: (-4711, 3.140), end: [1, 2] } }"
);
格式化您自己的结构
use tfmt::{uformat, uDisplayPadded, uWrite, Formatter, Padding};
struct EmailAddress {
fname: &'static str,
lname: &'static str,
email: &'static str,
}
impl uDisplayPadded for EmailAddress{
fn fmt_padded<W>(
&self,
fmt: &mut Formatter<'_, W>,
padding: Padding,
pad_char: char,
) -> Result<(), W::Error>
where
W: uWrite + ?Sized
{
let s = uformat!(128, "{}.{} <{}>", self.fname, self.lname, self.email).unwrap();
fmt.write_padded(s.as_str(), pad_char, padding)
}
}
let email = EmailAddress { fname: "Graydon", lname: "Hoare", email: "graydon@pobox.com"};
let s = uformat!(100, "'{:_^50}'", email).unwrap();
assert_eq!(
s.as_str(),
"'________Graydon.Hoare <graydon@pobox.com>_________'"
);
技术说明
性能
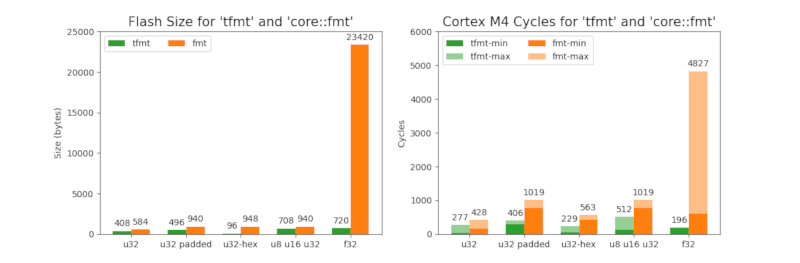
通常,微基准测试的使用是有问题的。然而,趋势可以非常清楚地识别。以下表格显示了使用几个示例将tfmt与core::fmt进行比较。tfmt明显小于core::fmt,并且也快得多。另一个区别是tfmt不包含panic分支。这对于嵌入式系统来说可能是一个重要的区别。core::fmt与浮点数相关的高内存需求是惊人的。所需周期的大幅波动也很令人惊讶。
生成数据和可视化的源代码可以在tests/size目录中找到。
| 名称 | 仓库 | 大小 | Cycles_min | Cycles_max |
|---|---|---|---|---|
| u32 | tfmt | 408 | 34 | 277 |
| u32 | fmt | 584 | 166 | 428 |
| u32 padded | tfmt | 496 | 284 | 406 |
| u32 padded | fmt | 940 | 770 | 1019 |
| u32-hex | tfmt | 128 | 125 | 237 |
| u32-hex | fmt | 948 | 422 | 563 |
| u8 u16 u32 | tfmt | 708 | 118 | 512 |
| u8 u16 u32 | fmt | 940 | 770 | 1019 |
| f32 | tfmt | 720 | 189 | 196 |
| f32 | fmt | 23420 | 1049 | 4799 |
表格的内容如下所示
使用unsafe
代码中多处使用unsafe。已经仔细考虑了这是否必要和安全。以下情况下使用unsafe是有用的
- 如果保证稍后写入的缓冲区不进行初始化,则可以节省一些周期。在简单的情况下,编译器会看到这一点并省略初始化本身。然而,在更复杂的结构中,它无法做到这一点(src/float.rs)。
- 为了避免panic分支,通常使用指针访问数组。或者上下文确保这可行,或者进行检查。
- 将字节缓冲区转换为str而不检查UTF8兼容性。这是安全的,因为缓冲区之前是用定义的UTF8兼容字符写入的。
所有位置都已相应注释。
许可证
所有源代码(包括代码片段)都根据您的选择之一进行许可
-
Apache许可证2.0版本(LICENSE-APACHE或https://apache.ac.cn/licenses/LICENSE-2.0)
。
贡献
除非您明确声明,否则根据Apache-2.0许可证定义的任何有意提交以包含在您的工作中的贡献,应按上述方式许可,不附加任何额外的条款或条件。
依赖关系
~2MB
~46K SLoC