5次发布
| 0.1.2 | 2023年8月21日 |
|---|---|
| 0.1.1 | 2023年8月21日 |
| 0.1.0 | 2023年7月7日 |
| 0.0.2-alpha | 2023年6月8日 |
| 0.0.1-alpha | 2023年5月18日 |
#649 in 算法
用于 osm-io
140KB
1.5K SLoC
![]()
text-file-sort
此crate实现了一个针对由行或行记录组成的文本文件的排序算法。例如CSV或TSV。
由行或行记录组成的数据库文件,即由分隔符分隔的字段组成的行,可以使用此crate进行排序。此类文件的示例包括 pg_dump, CSV 和 GTFS 数据文件。编写此模块的动机是在将数据转换为PBF格式之前,按每个表的键排序包含数十亿行的OpenStreetMap数据库的pg_dump文件。
此实现可用于对非常大的文件进行排序,利用多个CPU核心,并提供内存使用控制。
问题
欢迎并感谢提交问题。请提交至 https://github.com/navigatorsguild/text-file-sort/issues
基准测试
基准测试 由 benchmark-rs 生成
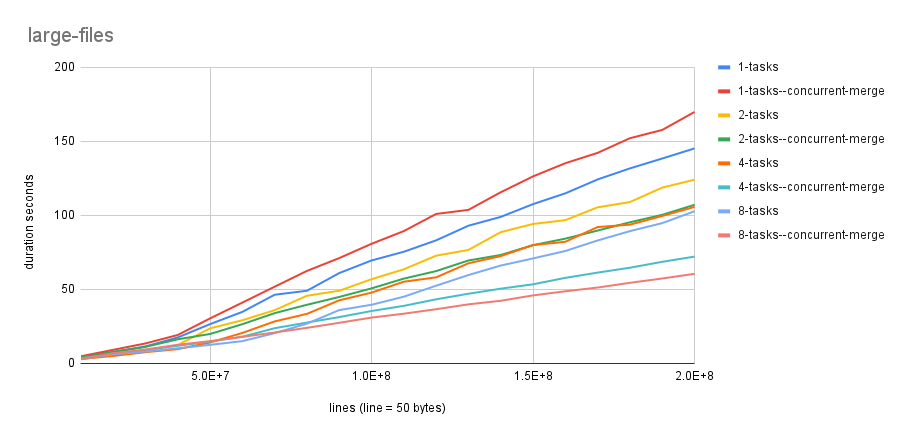
示例
use std::path::PathBuf;
use text_file_sort::sort::Sort;
// optimized for use with Jemalloc
use tikv_jemallocator::Jemalloc;
#[global_allocator]
static GLOBAL: Jemalloc = Jemalloc;
// parallel record sort
fn sort_records(input: PathBuf, output: PathBuf, tmp: PathBuf) -> Result<(), anyhow::Error> {
let mut text_file_sort = Sort::new(vec![input.clone()], output.clone());
// set number of CPU cores the sort will attempt to use. When given the number that exceeds
// the number of available CPU cores the work will be split among available cores with
// somewhat degraded performance. The default is to use all available cores.
text_file_sort.with_tasks(2);
// set the directory for intermediate results. The default is the system temp dir -
// std::env::temp_dir(), however, for large files it is recommended to provide a dedicated
// directory for intermediate files, preferably on the same file system as the output result.
text_file_sort.with_tmp_dir(tmp);
text_file_sort.sort()
}
许可证:MIT OR Apache-2.0
依赖
~5–15MB
~182K SLoC