4 个版本
| 0.1.4 | 2024 年 1 月 1 日 |
|---|---|
| 0.1.2 | 2024 年 1 月 1 日 |
| 0.1.1 | 2024 年 1 月 1 日 |
| 0.1.0 | 2023 年 12 月 30 日 |
#480 在 解析器实现
58KB
930 行
SteelDB
这是一个研究仓库。这主要是个人使用。使用 Rust 从零开始构建数据库。为什么不呢? :)
源代码: https://github.com/paolorechia/steeldb/
当前版本文档:最新版
*数据库: https://docs.rs/steeldb/latest/steeldb *解析器: https://docs.rs/steeldb-parser/latest/steeldb_parser/
架构
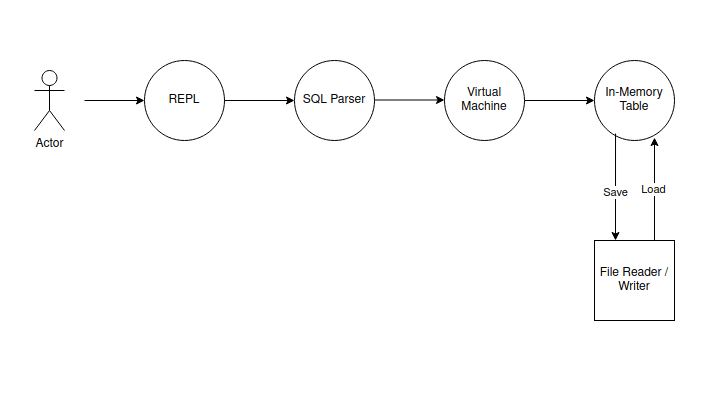
如何使用此版本
应该很简单
cargo add steeldb
cargo run
这将启动一个交互式命令行界面
------------------------------------------------
| |
| SteelDB |
| version: 0.1.0 |
| |
------------------------------------------------
Type 'exit;' to leave this shell
Current supported commands: [select]
>>
目前只实现了 select 语句,它用于选择之前构建的表的列。例如
>> select name, annual_salary;
|---------------------------------|
| name | annual_salary |
|---------------------------------|
| John Man | 60000 |
| Lenon | 200000 |
| Mary | 3012000 |
|---------------------------------|
>>
命令应该始终用 ; 结尾。
如果你简单地尝试上面的命令,你将看到
>> select name;
"Os { code: 2, kind: NotFound, message: \"No such file or directory\" }"
<------------------ COMMAND FAILED ------------------>
"TableNotFound"
<---------------------------------------------------->
>>
这是因为表必须预先创建。你可以使用 cargo test 创建一个,并将其复制,或者将其复制粘贴到文件 .steeldb/data/test_table.columnar 中。
TABLE COLUMNAR FORMAT HEADER
Field name: final_grade; Type: f32; Number of elements: 3
4.0
3.2
5
Field name: name; Type: String; Number of elements: 3
John Man
Lenon
Mary
Field name: annual_salary; Type: i32; Number of elements: 3
60000
200000
3012000
列式格式
如你所见,表格式非常简单且冗长。它以 ASCII 格式存储数据。它并不打算高效,将来可能会被替换。
更多信息
有用链接
- https://cstack.github.io/db_tutorial/parts/part1.html
- https://www.sqlite.org/arch.html
- https://build-your-own.org/database/
路线图
这不是一个具有约束力的路线图。
我们需要什么从头开始构建一个像 SQLite 一样的数据库?
- 一个交互式命令行界面 shell
- 一个标记器
- 一个解析器
- 一个代码生成器
- 一个解释生成的代码的虚拟机
- B+ 树
- 页面调度器
- 操作系统接口
对于第一迭代:基本结构 (v0.1.0)
我们可以在第一迭代中简化一些组件,因此我们首先有一个工作的端到端系统。然后我们可以调整单个组件以具有更多功能。
以下是我们可以在第一迭代中进行的简化
- 仅支持SQL语法的子集,例如,只支持insert和select操作。
- 第一轮迭代中不实现B+树。相反,使用向量或结构体的列表。
- 第一轮迭代中不处理分页器。
- 将数据库持久化到单个文件中。
- 使用单个静态定义的表。
第一轮迭代的路线图可能看起来像这样
- 一个REPL shell [x]
- 一个标记器 [x]
- 一个解析器 [x]
- 添加对SELECT子句的支持 [x]
- 一个代码生成器 [x]
- 一个解释生成的代码的虚拟机 [x]
- 一个表结构,在HashMap的向量中存储数据 [x]
- 一个用于测试的硬编码表 [x]
- 适当的错误传播 [x]
- 在REPL中打印表格的格式化输出 [x]
- 序列化/反序列化方法,以从文件中写入/读取数据 [x]
- 清理 [x]
- 在读取方法中正确处理选择列 [x]
- 测试一切是否按预期工作 [x]
- 标记v1.0 [x]
第二轮迭代:使其可用(v0.2.0)
- 为项目添加适当的文档 []
- 添加REPL之外的另一个API来查询数据库 []
- 这可以是传统的TCP或HTTP服务器。它应该尽可能简单,只需接收一个SQL命令的字符串
- 使REPL支持两种后端:独立进程或网络服务器
- 向服务器添加适当的日志策略 []
- 添加配置文件 []
- 添加创建表命令 []
- 添加删除表命令 []
- 添加修改表命令 []
- 支持多表查询(添加FROM子句支持) []
- 支持过滤器(添加基本的WHERE子句支持) []
- 为项目添加适当的文档 []
- 更新Cargo.toml
第三轮迭代:使其可扩展(v0.3.0)
- 处理并发:需要研究使用方法 []
- 实现B+或类似算法。
- 理想情况下,保持对当前列存储的支持 []
- 支持内存和持久化
- 添加缓存(或分页) []
- 支持事务 []
第四轮迭代:使其有用(v0.4.0)
- 实现内连接 []
- 实现左/右连接 []
- 实现外连接 []
- 实现嵌套操作,包括WHERE IN (SELECT) []
- 实现聚合 []
第五轮迭代:使其有时间感知(v0.5.0)
- 实现高级SQL功能
- 窗口 []
- HAVING []
- 添加日期和时间戳类型 []
- 实现更多SQL函数 []
第六轮迭代:使其完整(v0.6.0)
- SQL标准中缺少的任何重要内容
第七轮迭代:使其兼容(v0.7.0)
- 在Rust中实现Spark.SQL API
第八轮迭代:使其吸引人(v0.8.0)
- 构建Rust SDK以使用它
第九轮迭代:使其复杂(v0.9.0)
- 为Rust SDK构建Python绑定
第十轮迭代:占位符(v1.0.0)
如果我们达到这一点,我们实际上有一个令人印象深刻的系统 :)
知识库
我们如何在Rust中构建这些组件中的每一个?
REPL Shell
这可能是最简单的组件。我们只需要实现一个CLI shell,该shell读取输入行,直到出现命令结束符号(例如 ';')。然后它将解析的字符串转发到我们系统的下一层,并返回结果。
标记器和解析器
可以使用https://github.com/lalrpop/lalrpop生成它们。教程:http://lalrpop.github.io/lalrpop/tutorial/001_adding_lalrpop.html
代码生成器
它应该以某种方式集成到解析器中。一旦第一个解析器构建完成,这将更清楚(如果可能,避免过多的耦合)。
虚拟机
最简单的方法可能是将其实现为一个栈,这样它可以处理嵌套命令。对于每个解析的命令,我们将它推入栈中,然后虚拟机弹出并执行它。这假设我们以深度优先的方式解析命令,例如,最内层的命令总是首先解析,其结果可供下一个命令执行。只要语法正确定义,使用自动生成的词法分析器/解析器(如lalrpop)应该可以自然地实现这一点。
然而,为了简化,我们应从不支持嵌套命令开始。我们仍然可以保留栈,并为其未来的扩展做好准备。
B+ 树
B+ 树是广为人知的算法,在多个地方有所描述,例如:[B+ 树](https://en.wikipedia.org/wiki/B%2B_tree)。这部分内容将推迟到较晚再讨论!目标是首先开发出一个支持并发且可能暴露(HTTP)API以查询数据的系统/产品。这意味着事务等功能可能需要首先实现。
依赖项
~2.6–5MB
~82K SLoC