6 个版本
| 0.1.5 | 2024 年 3 月 3 日 |
|---|---|
| 0.1.4 | 2023 年 7 月 17 日 |
#6 in #database-table
63KB
1.5K SLoC
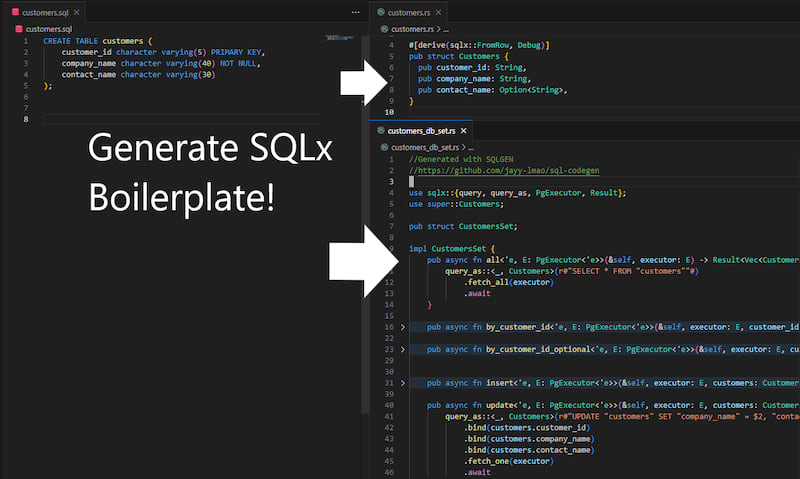
SQL-Gen - 扩展 SQLX 的 PostgreSQL 数据库操作生成的 Rust CLI 工具
欢迎提交 PR 和问题!尽管目前仍处于早期开发阶段,但希望对某些用户有所帮助!
SQL-Gen 是一个用 Rust 编写的命令行工具,它帮助您根据现有的 PostgreSQL 数据库模式生成 Rust 结构体、查询和 SQL 迁移。它利用 sqlx 和 clap 库,为您使用 PostgreSQL 数据库提供用户友好且高效的体验。
本项目受到 rsdbgen (GitHub: brianhv/rsdbgen) 的启发,我们感谢他们对 Rust 数据库工具生态系统的贡献。最初这个项目打算扩展 rsdbgen,但在某个变更点它似乎发生了分歧。
使用场景
- 通过 Postgres 测试容器生成 PostgreSQL 数据库表或迁移的 Rust 结构体和查询
- 根据结构体与数据库或迁移的差异生成 SQL 迁移
- 处理生成代码中的可空/可选字段。
- 可选
--force标志以覆盖现有文件。 - 使用环境变量而不是 clap 标志(可选)。
安装
要使用 SQL-Gen,请确保您的系统上已安装 Rust 和 Cargo。您可以通过访问 https://rust-lang.net.cn/ 上的说明进行安装。
安装 Rust 和 Cargo 后,您可以通过运行以下命令构建 SQL-Gen:
cargo install sql-gen
或针对最新的 GitHub 版本
cargo install --git https://github.com/jayy-lmao/sql-gen --branch main
使用方法
sql-gen [SUBCOMMAND] [OPTIONS]
子命令
generate - 为您的数据库中的表生成结构体和查询
https://github.com/jayy-lmao/sql-gen/assets/32926722/55f3391f-47e1-42dd-b24e-6903f96971d5
migrate - 根据结构体的差异生成与数据库表匹配的 SQL 迁移
https://github.com/jayy-lmao/sql-gen/assets/32926722/ea3b9739-be8f-43e5-b48d-83d130ffd1c5
选项
-
generate子命令选项-o, --models <SQLGEN_MODEL_OUTPUT_FOLDER>- 设置生成的结构体的输出文件夹(必需)-d, --database <DATABASE_URL>- 设置数据库连接URL(必需)。可以设置为docker来启动一个testcontainer实例以应用迁移。-c, --context <SQLGEN_CONTEXT_NAME>- 调用函数的上下文名称。默认为数据库名称-f, --force- 覆盖该文件夹中同名现有文件-m, --migrations <SQLGEN_MIGRATION_INPUT>- 设置迁移的输入文件夹(仅在数据库使用docker时)
-
migrate子命令选项-o, --models <SQLGEN_MODEL_FOLDER>- 设置包含现有结构体文件的文件夹(必需)-m, --migrations <SQLGEN_MIGRATION_OUTPUT>- 设置迁移的输出文件夹(必需)-d, --database <DATABASE_URL>- 设置数据库连接URL(必需)。可以设置为docker来启动一个testcontainer实例以应用迁移。
示例 .env 文件
在项目根目录中创建一个 .env 文件,包含以下内容
DATABASE_URL=postgres://username:password@localhost/mydatabase
SQLGEN_MODEL_OUTPUT_FOLDER=./src/models/
SQLGEN_MODEL_FOLDER=./src/models/
SQLGEN_MIGRATION_OUTPUT=./migrations
SQLGEN_MIGRATION_INPUT=./migrations
确保将值替换为实际的数据库连接URL和期望的生成的结构体和迁移文件夹路径。
生成结构体和查询
要为PostgreSQL数据库生成Rust结构体和查询,使用 generate 命令
sql-gen generate --output db --database <DATABASE_URL>
将 <DATABASE_URL> 替换为您的PostgreSQL数据库的URL。生成的代码将保存在 db 文件夹中。
示例
假设我们有一个以下输入数据库模式
CREATE TABLE customer (
id SERIAL PRIMARY KEY,
created_at TIMESTAMPTZ DEFAULT NOW()
email VARCHAR(255) UNIQUE,
);
运行SQLGen的 generate 命令
sql-gen generate --output db --database postgresql://postgres:password@localhost/mydatabase
这将生成以下Rust结构体和查询(基于主键、外键和唯一字段)
// in db/customer.rs
#[derive(sqlx::FromRow, Debug)]
struct Customer {
pub id: i32,
pub created_at: Option<chrono::DateTime<chrono::Utc>>,
pub email: Option<String>,
}
// in db/customer_db_set.rs
use sqlx::{query, query_as, PgExecutor, Result};
use super::Customer;
pub struct CustomerSet;
impl CustomerSet {
pub async fn all<'e, E: PgExecutor<'e>>(&self, executor: E) -> Result<Vec<Customer>> {
query_as::<_, Customer>(r#"SELECT * FROM "customer""#)
.fetch_all(executor)
.await
}
pub async fn by_id<'e, E: PgExecutor<'e>>(&self, executor: E, id: i64) -> Result<Customer> {
query_as::<_, Customer>(r#"SELECT * FROM "customer" WHERE "id" = $1"#)
.bind(id)
.fetch_one(executor)
.await
}
pub async fn by_id_optional<'e, E: PgExecutor<'e>>(&self, executor: E, id: i64) -> Result<Option<Customer>> {
query_as::<_, Customer>(r#"SELECT * FROM "customer" WHERE "id" = $1"#)
.bind(id)
.fetch_optional(executor)
.await
}
// Doesn't exist in this example, but foreign keys will functions like this, assuming customer has a fk field called category
// pub async fn all_by_categories_id<'e, E: PgExecutor<'e>>(executor: E, categories_id: i64) -> Result<Vec<Customer>> {
// query_as::<_, Customer>(r#"SELECT * FROM "customer" WHERE category = $1"#)
// .bind(categories_id)
// .fetch_all(executor)
// .await
// }
pub async fn by_email<'e, E: PgExecutor<'e>>(&self, executor: E, email: String) -> Result<Customer> {
query_as::<_, Customer>(r#"SELECT * FROM "customer" WHERE "email" = $1"#)
.bind(email)
.fetch_one(executor)
.await
}
pub async fn many_by_email_list<'e, E: PgExecutor<'e>>(&self, executor: E, email_list: Vec<String>) -> Result<Vec<Customer>> {
query_as::<_, Customer>(r#"SELECT * FROM "customer" WHERE "email" = ANY($1)"#)
.bind(email_list)
.fetch_all(executor)
.await
}
pub async fn by_email_optional<'e, E: PgExecutor<'e>>(&self, executor: E, email: String) -> Result<Option<Customer>> {
query_as::<_, Customer>(r#"SELECT * FROM "customer" WHERE "email" = $1"#)
.bind(email)
.fetch_optional(executor)
.await
}
pub async fn insert<'e, E: PgExecutor<'e>>(&self, executor: E, products: Customer) -> Result<Customer> {
query_as::<_, Customer>(r#"INSERT INTO "customer" ("id", "created_at", "email", "category") VALUES ($1, $2, $3, $4) RETURNING *;"#)
.bind(products.id)
.bind(products.created_at)
.bind(products.email)
.fetch_one(executor)
.await
}
pub async fn update<'e, E: PgExecutor<'e>>(&self, executor: E, products: Customer) -> Result<Customer> {
query_as::<_, Customer>(r#"UPDATE "customer" SET "created_at" = $2, "email" = $3 WHERE "id" = 1 RETURNING *;"#)
.bind(products.id)
.bind(products.created_at)
.bind(products.email)
.fetch_one(executor)
.await
}
pub async fn delete<'e, E: PgExecutor<'e>>(&self, executor: E) -> Result<()> {
query(r#"DELETE FROM "customer" WHERE "id" = 1"#)
.execute(executor)
.await
.map(|_| ())
}
}
// in db/mod.rs
pub mod customer;
pub use customer::Customer;
pub mod customer_db_set;
pub use customer_db_set::CustomerSet;
pub struct PostgresContext;
impl PostgresContext {
pub fn customer(&self) -> CustomerSet { CustomerSet }
}
上下文名称将默认为数据库名称,或可以使用 '--context' 标志进行设置。这些查询可能需要修改或更改,但可以作为良好的起点。您应该能够运行类似以下命令
let customers = PostgresContext.customer().all(&pool).await?;
建议将客户查询等添加到类似 db/customer_custom_queries.rs 的位置,以便它们不会被codgen覆盖。如果您 impl CustomerSet 并添加应扩展它的函数,则应扩展它。
生成迁移
要基于结构体的更改生成SQL迁移,请使用 migrate generate 命令
sql-gen migrate generate --database <DATABASE_URL> --include <FOLDER_PATH> --output migrations
将 <DATABASE_URL> 替换为您的 PostgreSQL 数据库的 URL,将 <FOLDER_PATH> 替换为包含生成的结构体的文件夹(例如前一个示例中的 db),将 migrations 替换为 SQL 迁移的输出文件夹。
示例
使用 migrate generate 命令运行 SQLGen
sql-gen migrate generate --database postgresql://postgres:password@localhost/mydatabase --include db --output migrations
这将执行先前的数据库生成预览,将其与 db 文件夹中现有的结构体进行比较,并为检测到的任何更改生成 SQL 迁移。迁移将保存在 migrations 文件夹中。
示例迁移
假设对 Customer 结构体进行了更改,添加了一个新字段
pub struct Customer {
pub id: i32,
pub created_at: Option<chrono::DateTime<chrono::Utc>>,
pub email: Option<String>,
pub address: Option<String>, // New field
}
运行 SQL-Gen 的 migrate generate 命令将生成以下迁移
-- Migration generated for struct: Customer
ALTER TABLE customer ADD COLUMN address TEXT;
要获取可用命令和选项的完整列表,可以使用 --help 标志
sql-gen --help
路线图
SQL-Gen 正在积极开发中,并计划进行未来增强。以下是路线图上的一些项目
类型
- 数组/向量
- 枚举
- 复合类型
- 十进制数
其他
- 使用屈折 crate(例如,如果你的表名为 customers,你可能希望结构体仍为 Customer)正确地单复数化
- 自定义生成的 derive 的方法
- 更清晰的输入类型,允许省略默认字段
- 测试
- 输出 linting(rustfmt 与 derive 宏配合使用很棘手)
- 支持注释和注解
- 支持在结构体和查询生成中生成更多数据类型
- 与其他数据库系统(MySQL、SQLite 等)集成
- 高级迁移场景(重命名列、表级别更改等)
- 生成迁移代码的 dry run 模式,不写入文件
非常感谢您的贡献和反馈!如果您遇到任何问题或有所建议
依赖项
~60MB
~1M SLoC