3 个版本
| 0.0.12 | 2022 年 9 月 28 日 |
|---|---|
| 0.0.11 | 2022 年 9 月 28 日 |
| 0.0.1 | 2022 年 9 月 28 日 |
#683 在 并发
20KB
352 行
Atom
这是一个实验性实现,这意味着 API 可能会更改,也可能出现错误。
同步和可变智能指针类型 Atom<T> 及其 Weak<T> 变体的实验性 API。还包括相关的自旋锁类型 SpinLock。
与 Mutex<T> 不同,Atom<T> 不使用系统 futex,而是使用简单的自旋锁。在低竞争情况下(即锁仅保持短暂时间且竞争锁的线程很少)可能会有所优势。
用法
Atom<T> 模仿 Arc<Mutex<T>> 的行为,但 API 略有不同。我们不是使用锁卫,而是在闭包中直接访问内部 T。
let atom = Atom::new(5);
atom.lock(|x| *x += 5);
assert_eq!(atom.get(), 10);
我们可以访问内部值的部分并将其映射到新的值
let atom = Atom::new(vec![1, 2, 3]);
let sum: i32 = atom.map(|x| x.iter().sum());
assert_eq!(sum, 6);
或者修改并映射
let atom = Atom::new(vec![1, 2, 3]);
let three = atom.map_mut(|x| x.pop());
assert_eq!(three, Some(3));
assert_eq!(atom.get(), vec![1, 2]);
示例
use spinout::Atom;
fn main() {
let mut numbers = vec![];
for i in 1..43 {
numbers.push(i);
}
let numbers = Atom::new(numbers);
let t1_numbers = numbers.clone();
let t2_numbers = numbers.clone();
let results = Atom::new(vec![]);
let t1_results = results.clone();
let t2_results = results.clone();
let t1 = std::thread::spawn(move || {
while let Some(x) = t1_numbers.map_mut(|x| x.pop()) {
if x % 2 == 0 {
t1_results.lock(|v| v.push(x));
}
}
});
let t2 = std::thread::spawn(move || {
while let Some(x) = t2_numbers.map_mut(|x| x.pop()) {
if x % 2 == 0 {
t2_results.lock(|v| v.push(x));
}
}
});
t1.join().unwrap();
t2.join().unwrap();
let mut results = results.get();
results.sort();
let expected = [
2, 4, 6, 8, 10, 12, 14, 16,
18, 20, 22, 24, 26, 28, 30,
32, 34, 36, 38, 40, 42
];
assert_eq!(results, expected);
}
基准测试
我们在 AMD Ryzen 3 3100 4 核处理器上使用 Criterion 统计基准测试工具运行了这些测试。
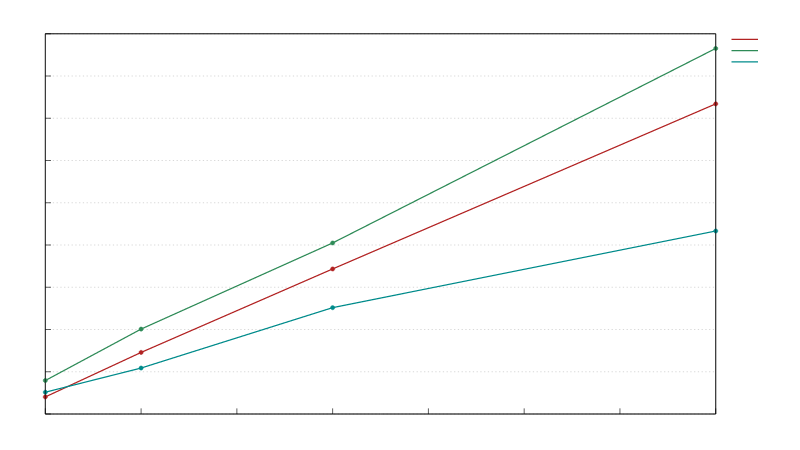
有四个不同的测试,模拟了一个具有少量线程和低竞争的现实世界场景。
在 Balanced Read and Write 和 Read Heavy Read and Write 中,我们对一个小的向量进行排序,并从(反转的)向量中读取最大值。
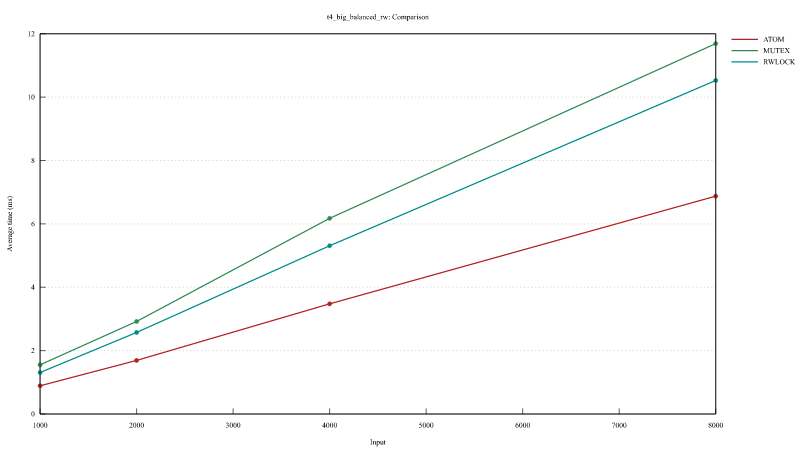
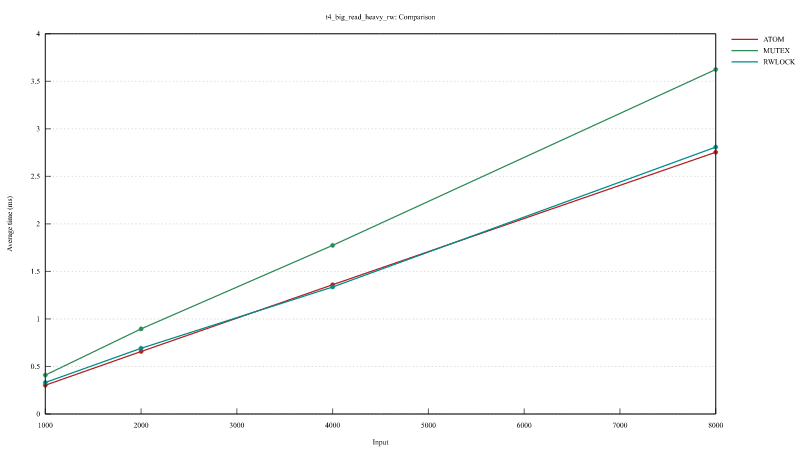
在 Write Only 测试中,我们对一个小向量进行排序和反转。
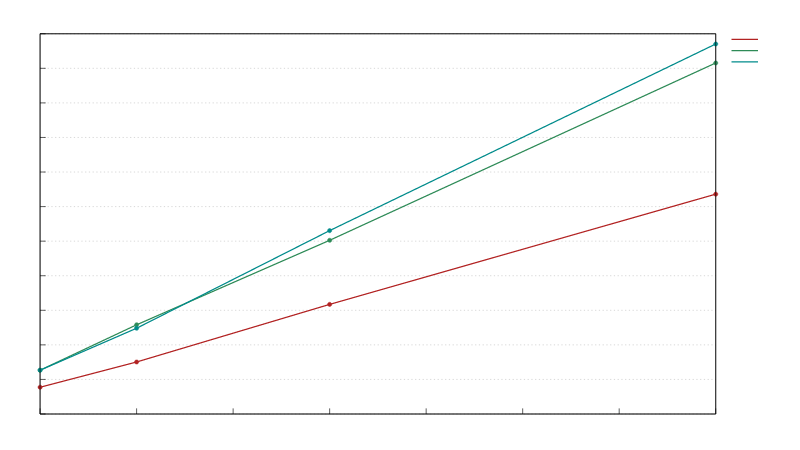
在 Read Only 测试中,我们在向量中查找一个值。