5个稳定版本
| 1.1.1 | 2024年2月1日 |
|---|---|
| 1.1.0 | 2023年10月23日 |
| 1.0.2 | 2023年10月19日 |
#2 in #distributed-id
每月25次下载
420KB
340 行
❄ spaceflake.rs ❄
![]()
![]()
![]()
一个轻松创建唯一ID的分布式生成器;受Twitter的Snowflake启发。关于此项目的博客文章可在此处找到。
什么是Snowflake?
除了是雪花晶体之外,Snowflake还是分布式计算中使用的唯一标识符的一种形式。它具有特定的部分,二进制长度为64位。我简单地将我的Snowflake类型命名为Spaceflake,因为它不包含Twitter Snowflake的相同部分,并且用于Project Absence和我的其他项目。
结构
Spaceflake的结构如下: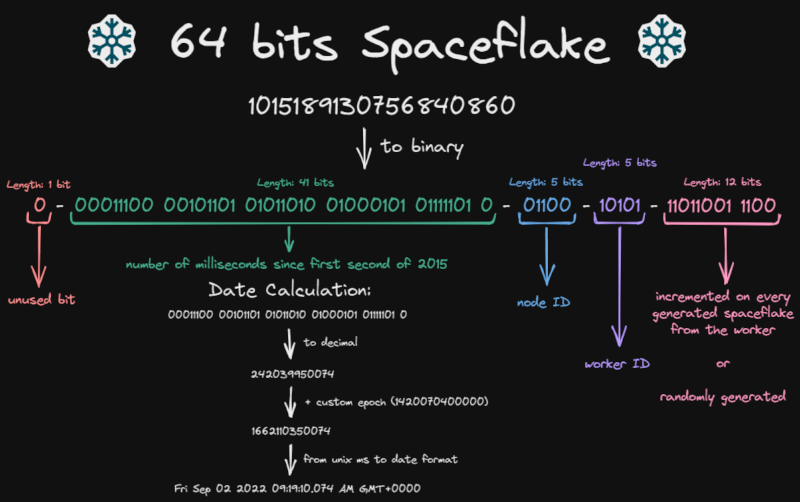
Spaceflake网络
Spaceflake网络是一个非常基本的概念,其中包含多个**独立节点**,每个节点本身又包含多个工作进程。这些工作进程是生成Spaceflake的进程。
理想情况下,Spaceflake网络代表您的整个应用程序或公司。每个节点代表公司内的单个服务器或应用程序,每个工作进程代表可以生成特定用途Spaceflake的单个进程。这样,您可以通过查看其节点ID和工作进程ID轻松识别Spaceflake的生成位置。
最终,您可以根据自己的意愿使用它们,只需确保使用这些节点和工作进程来识别Spaceflake即可。
示例网络
以下是一个示例网络的结构: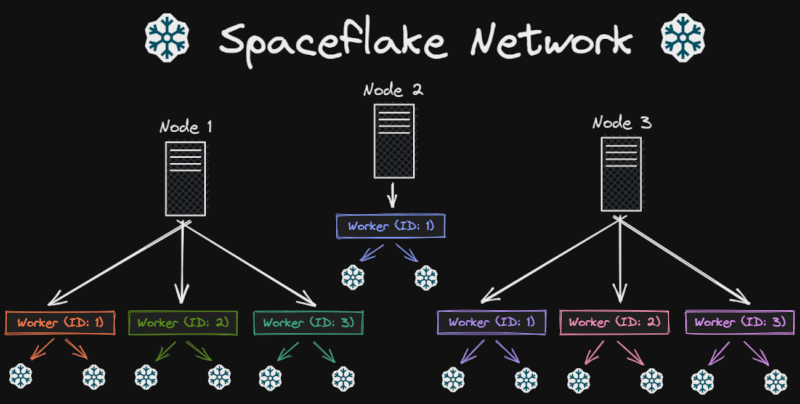 我们可以将**节点1**视为您的应用程序的API/后端。**工作进程(ID:1**)将负责为用户ID生成Spaceflake。**工作进程(ID:2**)将负责为博客文章ID生成Spaceflake。
我们可以将**节点1**视为您的应用程序的API/后端。**工作进程(ID:1**)将负责为用户ID生成Spaceflake。**工作进程(ID:2**)将负责为博客文章ID生成Spaceflake。
节点 2 可能负责您组件的日志,生成的日志 ID 将由该节点的 Worker (ID: 1) 生成。
一些统计数据
- Spaceflake 网络可以容纳最多 31 个节点 和每个节点 31 个工作进程。因此,在一个生成 Spaceflakes 的单一网络中,您最多可以有 961 个工作进程。
- 单个工作进程可以每毫秒生成最多 4095 个 Spaceflakes。
- 具有 31 个工作进程 的单个节点可以每毫秒生成最多 126,945 个 Spaceflakes。
- 具有 31 个节点 和每个节点 31 个工作进程 的单个网络可以每毫秒生成最多 3,935,295 个 Spaceflakes。
示例
使用库的一个非常基本的例子是不使用节点和工作进程对象来使用生成器,尽管这不是推荐的做法,使用节点和工作进程会更好。
fn main() {
let mut node = spaceflake::Node::new(1);
let mut worker = node.new_worker();
let sf = worker.generate();
match sf {
Ok(mut value) => {
println!("Generated Spaceflake: {:#?}", value.decompose())
}
Err(error) => {
println!("Error: {}", error)
}
}
}
其他一些示例
- 批量生成:一次性生成多个 Spaceflakes。
- 使用节点和工作进程生成:通过创建节点和工作进程对象来生成 Spaceflake。
- 使用设置生成:使用特定设置生成 Spaceflakes (不推荐,考虑使用节点和工作进程)
安装
如果您想将此库用于您的一个项目,您可以使用与任何其他 Rust 库相同的方式安装它
cargo add spaceflake
⚠️ 声明
Spaceflakes 是大数
📜 TL;DR:如果您在 API 中使用 Spaceflakes,请将其作为 字符串 返回,而不是数字。
由于 Spaceflakes 是大数,因此如果您使用它们在返回 JSON 的 API 中,您很可能需要将 Spaceflake 作为字符串返回,否则您会丢失一些精度,并且会改变 Spaceflake 的值,很可能是序列的值。示例
{
"id": 144328692659220480
// ID actually generated in Rust: 144328692659220481
}
在上面的示例中,这两个数字之间的差异并不大,尽管这起着很大的作用。差异并不总是相同的,因此您不能相减。例如,JavaScript 无法区分这两个数字
console.log(144328692659220480 == 144328692659220481) // true
您可以在 Rust 代码中将 Spaceflake 作为字符串获取,并在需要时将其转换为 u64 数据类型
基于时间的“随机”序列
📜 TL;DR:序列并非真正随机,它是基于时间的;并且如果您在相同毫秒内生成大量 Spaceflakes,则两个 Spaceflakes 结果相同的可能性很高。强烈推荐使用 节点和工作进程。
当在很短的时间内生成大量 Spaceflakes 而不使用工作进程时,可能会生成相同的 ID 两次。考虑使您的程序暂停 1 毫秒或测试在生成之间
use spaceflake::Spaceflake;
use std::collections::HashMap;
use std::thread;
use std::time::Duration;
fn main() {
let mut spaceflakes = HashMap::<u64, Spaceflake>::new();
let settings = spaceflake::GeneratorSettings::default();
for _ in 0..1000 {
let sf = spaceflake::generate(settings);
match sf {
Ok(value) => {
if spaceflakes.get(&value.id).is_some() {
panic!("Got the same Spaceflake ID twice")
}
spaceflakes.insert(value.id, value);
}
Err(error) => {
println!("Error: {}", error)
}
}
// When using random there is a chance that the sequence will be twice the same due to Rust's speed, hence using a worker is better. We wait a millisecond to make sure it's different.
thread::sleep(Duration::from_millis(1))
}
}
在这种情况下,建议使用工作进程,因为它们不使用随机值作为序列号,而是使用递增值。另一个选项是使用 批量生成器 一次性创建大量 唯一 的 Spaceflakes。
作为最后的手段,您可以使用以下方法使用更好的随机数生成器来替换序列
settings.sequence =... // Replace with your number generator
许可证
此库由 Krypton 用 💜 制作,并受 MIT 许可证的约束。