6 个版本
| 0.2.0 | 2023年2月19日 |
|---|---|
| 0.1.3 | 2023年1月21日 |
| 0.0.0-pre-release0.0 | 2023年1月16日 |
#988 in 并发
88KB
412 行
此 Crates 提供了一个顺序锁定环形缓冲区。它允许快速的非阻塞写入器的 SPMC-队列,其中所有消费者都读取所有消息。
使用方法
从队列中消费有两种方式。如果线程通过共享引用共享一个 ReadGuard,它们将相互窃取队列项,这样就没有两个线程会读取相同的消息。当克隆 ReadGuard 时,新 ReadGuard 的读取进度将不再影响另一个。如果两个线程各自使用一个单独的 ReadGuard,它们将能够读取相同的消息。
use sling::*;
let buffer = RingBuffer::<_, 256>::new();
let mut writer = buffer.try_lock().unwrap();
let mut reader = buffer.reader();
std::thread::scope(|s| {
let reader = &reader;
for t in 0..8 {
s.spawn(move || {
for _ in 0..100 {
if let Some(val) = reader.pop_front() {
println!("t: {}, val: {:?}", t, val);
};
}
});
}
for i in 0..100 {
writer.push_back([i, i, i]);
}
});
重要!
还需要注意的是,如果慢速读取者没有足够快地消费消息,它们将被写入者超过。如果缓冲区大小不足,这种情况可能会相当频繁。建议根据具体情况测试应用程序,并找到最适合您用例的缓冲区大小。
基准测试
与 Crossbeam-Channel 的 mpmc 队列 和 lockfree 的 spmc 队列 的 Ping 速度比较。
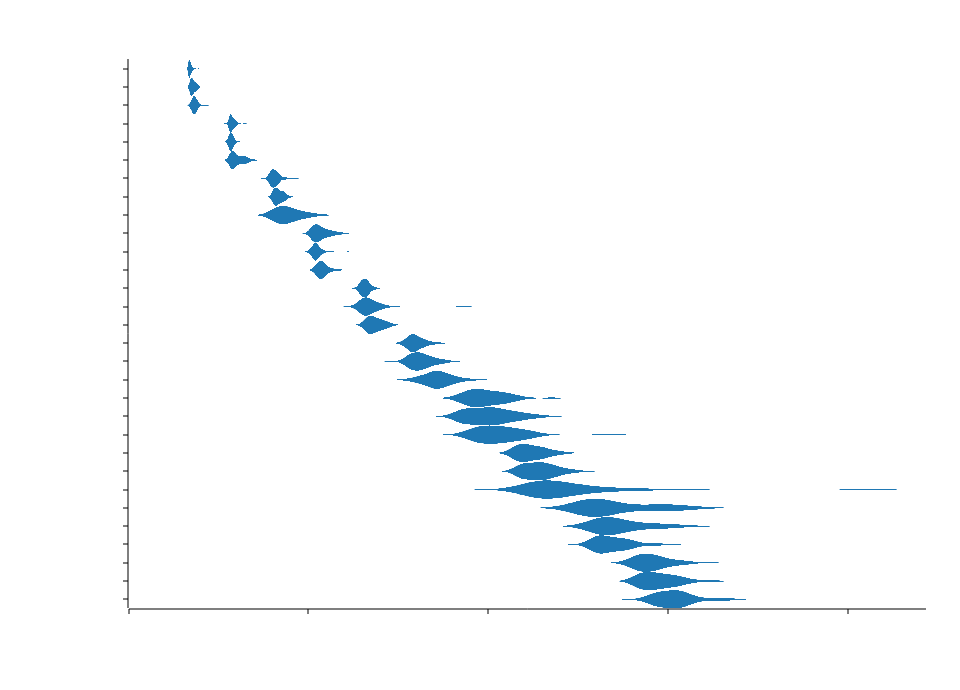
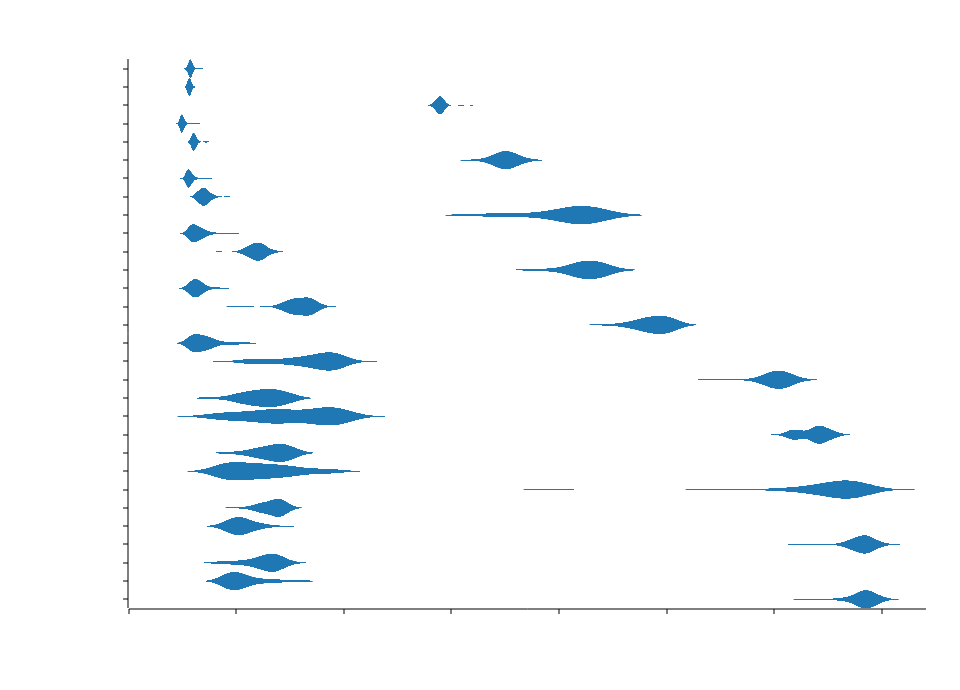 免责声明:这些基准测试是在个人计算机上进行的,可能不代表在其他计算机上的相对性能。
免责声明:这些基准测试是在个人计算机上进行的,可能不代表在其他计算机上的相对性能。
基准测试系统的规格
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i7-10700K CPU @ 3.80GHz
CPU family: 6
Model: 165
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 5
CPU(s) scaling MHz: 68%
CPU max MHz: 5100.0000
CPU min MHz: 800.0000
BogoMIPS: 7602.45
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 256 KiB (8 instances)
L1i: 256 KiB (8 instances)
L2: 2 MiB (8 instances)
L3: 16 MiB (1 instance)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
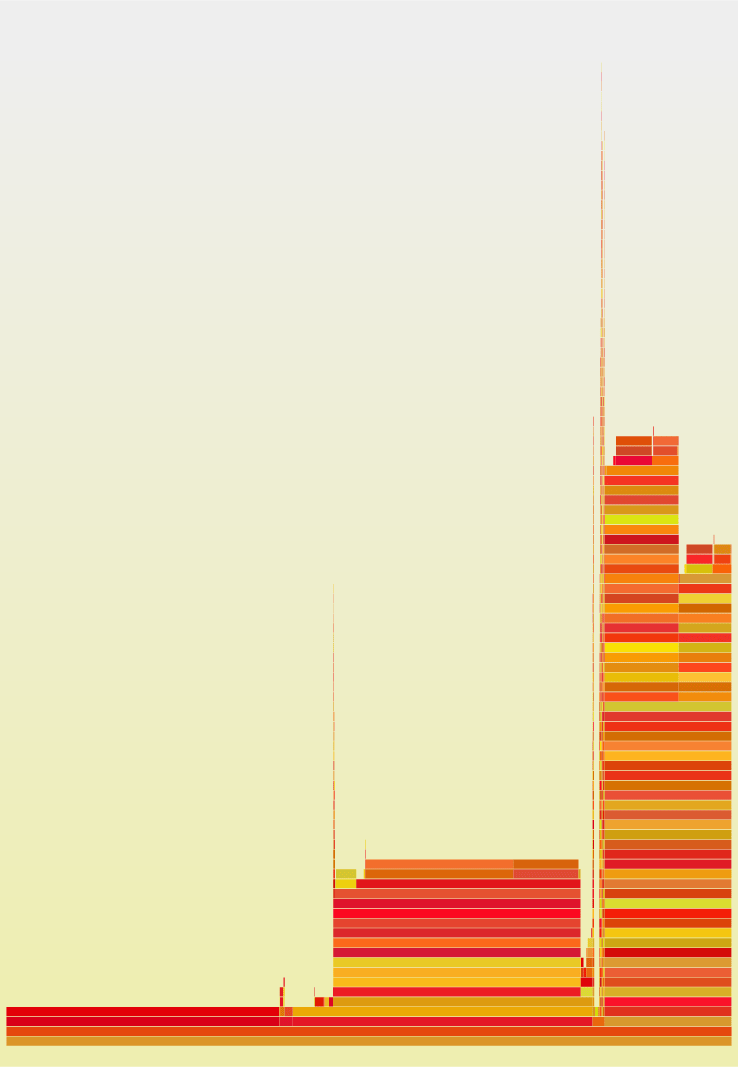
火焰图
依赖项
~0–26MB
~330K SLoC