2个稳定版本
| 1.0.1 | 2024年7月19日 |
|---|---|
| 0.1.0 |
|
#633 in 编码
每月下载量357
在ussr-nbt中使用
315KB
545 行
simd_cesu8 


这是一个非常快、SIMD加速的CESU-8和修改后的UTF-8编码和解码库。
功能
- 极快的CESU-8和修改后的UTF-8编码和解码。
- 仅在绝对必要时分配内存。无零分配。
- 支持CESU-8和MUTF-8的损失性解码。
- 支持CESU-8和MUTF-8的严格解码。
- 编码时比已知替代方案快25倍以上。
- 解码时比已知替代方案快14倍以上。
- 支持x86和x86-64上的AVX 2和SSE 4.2实现。
- 支持ARM64 (aarch64) SIMD。
- 支持WASM (wasm32) SIMD。
- 部分支持PowerPC (powerpc) SIMD。
- 在字而非字节级别回退到实现。
- 支持no-std。
使用方法
将此添加到您的Cargo.toml文件
[dependencies.simd_cesu8]
version = "1"
features = ["nightly"]
强烈建议使用nightly功能,因为它启用了库最快的实现。如果您不想使用nightly,可以移除该功能,库仍然可以工作,但速度会慢一些。
文档
文档可以在docs.rs上找到。
为了快速访问某些函数,我强烈建议在文档页面左上角点击“所有项目”按钮。
MSRV
最低支持的Rust版本是1.79.0。
基准测试
这些基准测试是在AMD Ryzen 9 7950X3D上使用WSL2和Rust 1.81.0-nightly运行的。每个操作都使用正好等于16,380字节的输入进行测量。数据集使用相同的种子随机生成,每个操作包含1,000个值,这些值作为输入无限重复。基准测试使用criterion库运行。表格是通过critcmp创建的。基准测试的源代码可以在benches目录中找到。在收集cesu8基准测试的数据时,任何对simd_cesu8的调用都被替换为cesu8等效函数。收集的数据也可以在benches目录中找到。
我们将simd_cesu8与cesu8库进行比较,因为它是在Rust中CESU-8和MUTF-8编码和解码中最受欢迎的库。然而,我最初开始这个项目是因为cesu8库中存在一些小的语义错误,我想自己修复。
编码
为了理解基准测试,首先熟悉用于基准测试编码操作的数据库集是一个好主意
ascii_non_null_strings是只包含ASCII字符且没有空字节的16,380字节长的字符串。ascii_null_alternating_strings是只包含ASCII字符和空字节交替的16,380字节长的字符串,其中每个奇数字节是非空的,每个偶数字节是空的。interspersed_strings是每个20字节包含以下模式的16,380字节长的字符串- 一个非空ASCII字符(1字节)
- 一个2字节UTF-8字符
- 一个3字节UTF-8字符
- 一个4字节UTF-8字符
- 一个空字节
- 一个2字节UTF-8字符
- 一个3字节UTF-8字符
- 一个4字节UTF-8字符
null_strings是只包含空字节的16,380字节长的字符串。utf8_clamped_width_2_strings是只包含2字节UTF-8字符的16,380字节长的字符串。utf8_clamped_width_3_strings是只包含3字节UTF-8字符的16,380字节长的字符串。utf8_clamped_width_4_strings是只包含4字节UTF-8字符的16,380字节长的字符串。
simd_cesu8::encode
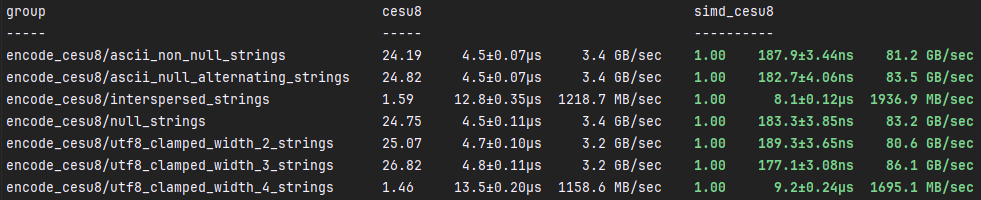
simd_cesu8::encode在最佳条件下比cesu8::to_cesu8快约2500%。在次优条件下,simd_cesu8::encode比cesu8::to_cesu8快约50%。除了SIMD之外,加速的主要原因是因为simd_cesu8不会快速检查是否只有ASCII字符,而是检查4字节字符的开始。这比传统的ASCII热路径有显著的加速。其他加速是通过累积的、微小的优化实现的,这些优化加起来可以显著提高速度。
simd_cesu8::mutf8::encode
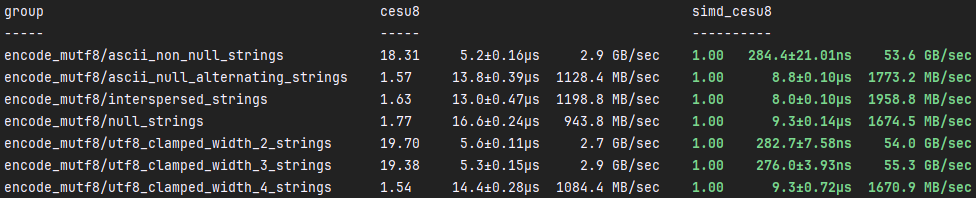
与simd_cesu8::encode类似,simd_cesu8::mutf8::encode在最佳条件下比cesu8::to_java_cesu8快约1800%。在不最佳条件下,simd_cesu8::mutf8::encode比cesu8::to_java_cesu8快约50%。速度提升的原因相同,但在这里,我们不仅使用SIMD检查4字节字符的开始,还检查任何空字节。其他速度提升来自于累积的、微小的优化,这些优化加在一起可以显著提高速度。
解码
要理解基准测试,首先熟悉用于基准测试解码操作的测试数据集是个好主意
ascii_non_null_bytes是一个包含仅ASCII字符且没有空字节的UTF-8字符串集,长度恰好为16,380字节。ascii_null_alternating_bytes是一个包含仅ASCII字符和空字节交替的UTF-8字符串集,长度恰好为16,380字节,其中每个奇数字节是非空字节,每个偶数字节是空字节。interspersed_bytes是一个包含每20字节具有以下模式的UTF-8字符串集,长度恰好为16,380字节- 一个非空ASCII字符(1字节)
- 一个2字节UTF-8字符
- 一个3字节UTF-8字符
- 一个4字节UTF-8字符
- 一个空字节
- 一个2字节UTF-8字符
- 一个3字节UTF-8字符
- 一个4字节UTF-8字符
interspersed_cesu8_bytes是一个包含每12字节具有以下模式的CESU-8字符串集,长度恰好为16,380字节- 一个ASCII字符(1字节)
- 一个2字节UTF-8字符
- 一个3字节UTF-8字符
- 一个4字节UTF-8字符,编码为代理对(6字节)
interspersed_mutf8_bytes是一个包含每26字节具有以下模式的MUTF-8字符串集,长度恰好为16,380字节- 一个非空ASCII字符(1字节)
- 一个非空ASCII字符(1字节)
- 一个2字节UTF-8字符
- 一个3字节UTF-8字符
- 一个4字节UTF-8字符,编码为代理对(6字节)
- 一个作为2字节序列编码的空字节
- 一个2字节UTF-8字符
- 一个3字节UTF-8字符
- 一个4字节UTF-8字符,编码为代理对(6字节)
mutf8_null_bytes是一个包含仅作为2字节序列编码的空字节的MUTF-8字符串集,长度恰好为16,380字节。null_bytes是一个包含仅空字节的UTF-8字符串集,长度恰好为16,380字节。surrogate_pairs_bytes是一个包含仅6字节代理对的CESU-8字符串集,长度恰好为16,380字节。utf8_clamped_width_2_bytes是一个包含仅2字节UTF-8字符的UTF-8字符串集,长度恰好为16,380字节。utf8_clamped_width_3_bytes是一个包含仅3字节UTF-8字符的UTF-8字符串集,长度恰好为16,380字节。utf8_clamped_width_4_bytes是一个包含仅4字节UTF-8字符的UTF-8字符串集,长度恰好为16,380字节。
simd_cesu8::解码
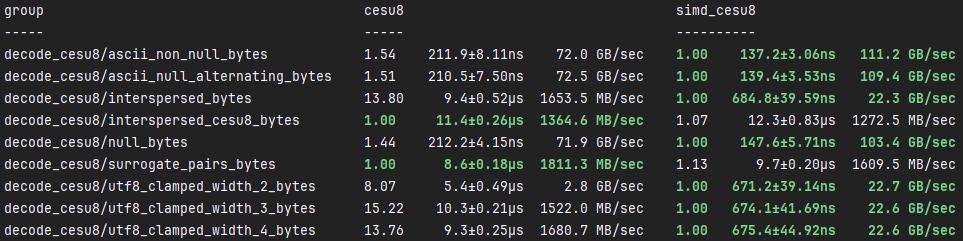
在最佳条件下,simd_cesu8::decode可以比cesu8::to_cesu8快约1400%。然而,当解码代理对时,simd_cesu8::decode比cesu8::to_cesu8慢。主要原因在于simd_cesu8支持有损解码,但该内部机制似乎引入了相当多的开销。simd_cesu8在所有方面都比cesu8快,前提是启用了LTO。然而,我没有在启用LTO的情况下运行基准测试,因为这看起来有点不诚实,因为LTO不应该是一个库快速运行的必要条件。
simd_cesu8::mutf8::解码
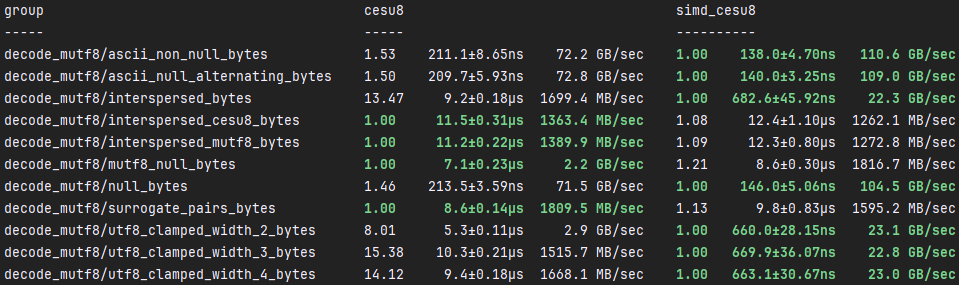
与simd_cesu8::decode类似,simd_cesu8::mutf8::decode的速度比cesu8::to_java_cesu8快约%1,400。但是,潜在的陷阱也是相同的,因为在解码代理对时,simd_cesu8::mutf8::decode的速度比cesu8::to_java_cesu8慢。另一个需要注意的问题是,在解码空字节时,我们比cesu8稍慢。同样的道理也适用于这里,因为开销更高。
感谢
cesu8库的作者。这是一个真正优秀的库,它帮助我在几年前学习了一些更复杂的Rust概念。- 感谢
simdutf8的作者,因为这是对库中借用路径的最大改进之一。 - 感谢
simdnbt的作者,他们启发了我们使用portable_simd。
许可证
在以下任一许可证下授权:
- Apache License, Version 2.0 (LICENSE-APACHE或https://apache.ac.cn/licenses/LICENSE-2.0)
- MIT许可证 (LICENSE-MIT或https://open-source.org.cn/licenses/MIT)
由您选择。
贡献
除非您明确声明,否则根据Apache-2.0许可证定义,您有意提交的任何贡献,都应按照上述方式双许可,没有任何附加条款或条件。