1 个不稳定版本
| 0.7.2+serum.1 | 2021年1月15日 |
|---|
#23 in #borsh
75KB
1K SLoC

为什么还需要另一种序列化格式?Borsh是第一个优先考虑以下对安全性关键项目至关重要的特性的序列化器
- 一致且明确的二进制表示
- 一致性意味着对象与其二进制表示之间存在双射映射。没有两个二进制表示可以反序列化为同一个对象。这对于使用二进制表示来计算哈希的应用程序非常有用;
- Borsh附带一个完整规范,可用于其他语言的实现;
- 安全。Borsh实现使用安全的编码实践。在Rust中,Borsh几乎只使用安全的代码,只有一个例外是使用
unsafe以避免耗尽攻击; - 速度。在Rust中,Borsh通过放弃使用 Serde 来实现高性能,在某些情况下比 bincode 更快;这也减少了代码大小。
示例
use borsh::{BorshSerialize, BorshDeserialize};
#[derive(BorshSerialize, BorshDeserialize, PartialEq, Debug)]
struct A {
x: u64,
y: String,
}
#[test]
fn test_simple_struct() {
let a = A {
x: 3301,
y: "liber primus".to_string(),
};
let encoded_a = a.try_to_vec().unwrap();
let decoded_a = A::try_from_slice(&encoded_a).unwrap();
assert_eq!(a, decoded_a);
}
特性
放弃使用Serde使borsh具备一些当前尚不可用于serde兼容序列化器的功能。目前我们支持两个功能:borsh_init 和 borsh_skip(前者在Serde中不可用)。
borsh_init 允许在反序列化后自动运行初始化函数。这对于设计为严格不可变的对象来说非常方便。使用示例
#[derive(BorshSerialize, BorshDeserialize)]
#[borsh_init(init)]
struct Message {
message: String,
timestamp: u64,
public_key: CryptoKey,
signature: CryptoSignature
hash: CryptoHash
}
impl Message {
pub fn init(&mut self) {
self.hash = CryptoHash::new().write_string(self.message).write_u64(self.timestamp);
self.signature.verify(self.hash, self.public_key);
}
}
borsh_skip 允许跳过序列化/反序列化字段,假设它们实现了 Default 特性,类似于 #[serde(skip)]。
#[derive(BorshSerialize, BorshDeserialize)]
struct A {
x: u64,
#[borsh_skip]
y: f32,
}
基准测试
我们对区块链项目最关心的对象进行了以下基准测试:区块、区块头、交易、账户。我们从nearprotocol区块链中获取了对象结构。我们使用了Criterion来构建以下图表。
基准测试在Google Cloud n1-standard-2 (2 vCPUs, 7.5 GB memory)上运行。
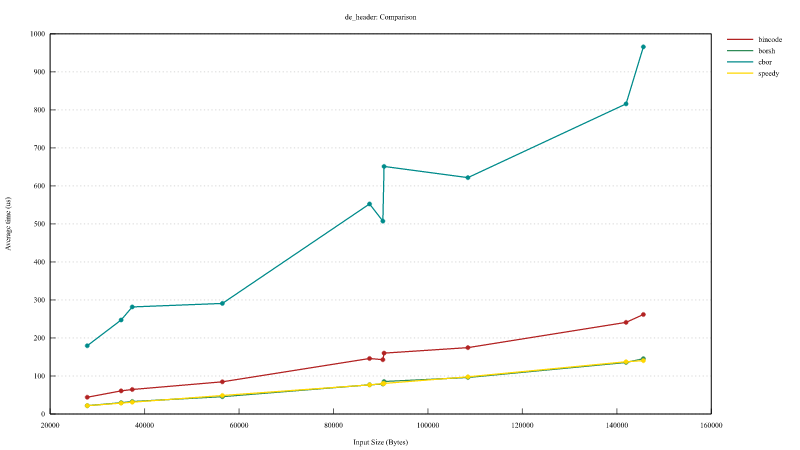
区块头序列化速度与区块头字节大小(大小仅大致对应序列化复杂性,导致图表不光滑)的关系
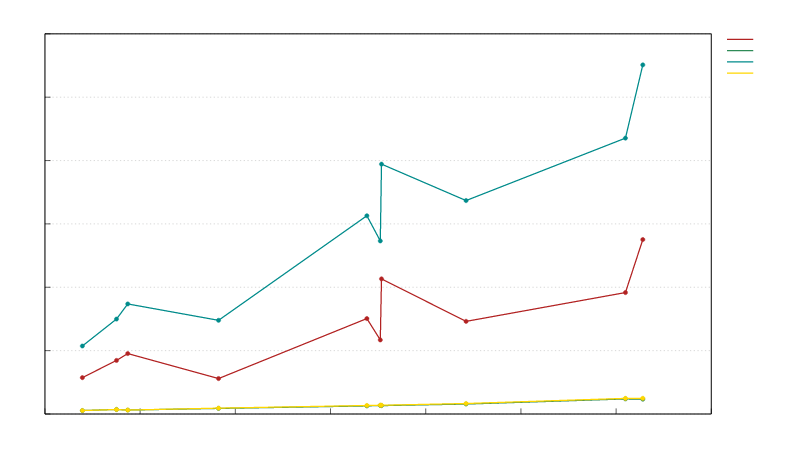
区块头反序列化速度与区块头字节大小的关系
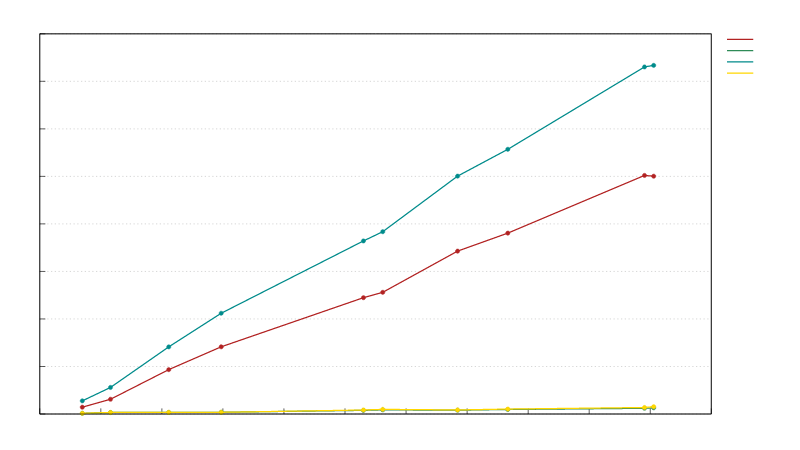
区块序列化速度与区块字节大小的关系
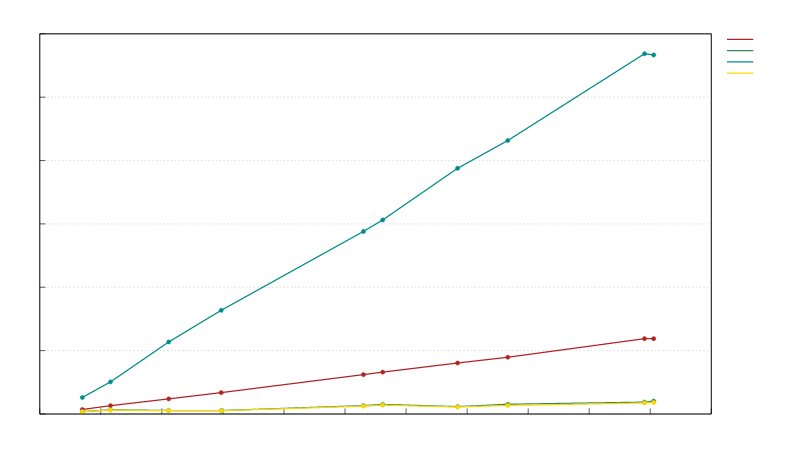
区块反序列化速度与区块字节大小的关系
请在此处查看完整报告here。
规格说明
简而言之,Borsh是一种非自描述的二进制序列化格式。它被设计成将任何对象序列化为一组规范和确定的字节。
一般原则
- 整数采用小端序;
- 动态容器的大小(例如vector、string)在值之前写入,作为
u32; - 所有无序容器(如hashmap、hashset)按字典顺序按键(在解决冲突的情况下按值)排序;
- 结构体按结构体中的字段顺序序列化;
- 枚举使用
u8对枚举序号进行序列化,然后存储枚举值中的数据(如果存在)。
正式规范
| 非正式类型 | Rust EBNF * | 伪代码 |
| 整数 | integer_type: ["u8" | "u16" | "u32" | "u64" | "u128" | "i8" | "i16" | "i32" | "i64" | "i128" ] | little_endian(x) |
| 浮点数 | float_type: ["f32" | "f64" ] | err_if_nan(x) little_endian(x as integer_type) |
| 单位 | unit_type: "()" | 我们不写入任何内容 |
| 固定大小数组 | array_type: '[' ident ';' literal ']' | for el in x repr(el as ident) |
| 动态大小数组 | vec_type: "Vec<" ident '>" | repr(len() as u32) for el in x repr(el as ident) |
| 结构体 | struct_type: "struct" ident fields | repr(fields) |
| 字段 | fields: [named_fields | unnamed_fields] | |
| 命名字段 | named_fields: '{' ident_field0 ':' ident_type0 ',' ident_field1 ':' ident_type1 ',' ... '}' | repr(ident_field0 as ident_type0) repr(ident_field1 as ident_type1) ... |
| 未命名字段 | unnamed_fields: '(' ident_type0 ',' ident_type1 ',' ... ')' | repr(x.0 as type0) repr(x.1 as type1) ... |
| 枚举 | enum: 'enum' ident '{' variant0 ',' variant1 ',' ... '}' variant: ident [ fields ] ? |
假设X是枚举所采取的变体的数量。 repr(X as u8) repr(x.X as fieldsX) |
| HashMap | hashmap: "HashMap<" ident0, ident1 ">" | repr(x.len() as u32) for (k, v) in x.sorted_by_key() { repr(k as ident0) repr(v as ident1) } |
| HashSet | hashset: "HashSet<" ident ">" | repr(x.len() as u32) for el in x.sorted() { repr(el as ident) } |
| Option | option_type: "Option<" ident '>" | if x.is_some() { repr(1 as u8) repr(x.unwrap() as ident) } else { repr(0 as u8) } |
| 字符串 | string_type: "String" | encoded = utf8_encoding(x) as Vec<u8> repr(encoded.len() as u32) repr(encoded as Vec<u8>) |
注意
- 一些Rust语法的部分尚未正式化,例如枚举和变体。我们从前端的
syn类型中反向推导出Rust语法的EBNF形式; - 我们需要扩展EBNF的重复部分,而不是将它们定义为
[ ident_field ':' ident_type ',' ] *,而是定义为ident_field0 ':' ident_type0 ',' ident_field1 ':' ident_type1 ',' ...,这样我们就可以在伪代码中引用单个元素; - 我们使用
repr()函数来表示我们将给定元素的表示写入一个假想的缓冲区。
发布
在你将更改合并到主分支并更新所有三个crate的版本后,就是正式发布新版本的时候了。
确保borsh、borsh-derive和borsh-derive-internal都具有新的crate版本。然后导航到每个文件夹,并按顺序运行(
cd ../borsh-derive-internal; cargo publish
cd ../borsh-derive; cargo publish
cd ../borsh; cargo publish
确保你在主分支上,然后对代码进行标记并推送标记
git tag -a v9.9.9 -m "My superawesome change."
git push origin v9.9.9
依赖项
~2MB
~43K SLoC