18个稳定版本 (4个主要版本)
使用旧的Rust 2015
| 4.1.0 | 2021年1月16日 |
|---|---|
| 4.0.1 | 2020年6月27日 |
| 4.0.0 | 2020年1月31日 |
| 3.0.7 | 2020年1月28日 |
| 0.2.0 | 2016年11月20日 |
#51 in 算法
1,507,960 每月下载量
在 1,507 个crate(106个直接使用) 中使用
44KB
689 行
SeaHash:一个速度惊人的散列函数。
SeaHash是一个散列函数,其性能优于(大约提高3-20%)xxHash和MetroHash。此外,SeaHash具有数学上可证明的统计保证。
实际应用

lib.rs:
SeaHash:一个速度极快、可移植的散列函数,具有经过验证的统计保证。
SeaHash是一个散列函数,其性能优于(大约提高3-20%)xxHash和MetroHash。此外,SeaHash具有数学上可证明的统计保证。
SeaHash是一个可移植的散列函数,这意味着输出不依赖于宿主架构,也不对字节序或类似内容做出假设。这种稳定的布局允许它在磁盘/永久存储(例如校验和)中使用。
设计、优势和特性
- 高质量:它击败了大多数其他通用散列函数,因为它在状态更新之间提供了完整的雪崩效应。
- 性能:SeaHash击败了我所知道的每个高质量的(在smhasher中评分为10/10)散列函数。
- 可证明的质量保证:与大多数其他非加密散列函数不同,SeaHash可以被证明满足雪崩标准和BIC。
- 可并行化:由多个独立的状态组成,以利用ILP和/或软件线程。
- 批量读取:每次读取8或4个字节。
- 稳定和可移植:不依赖于目标架构,并生成一个稳定的值,仅在主要版本升级时更改。
- 键控:设计为不泄露种子/密钥。请注意,它尚未经过密码分析,因此当需要安全性时,键控版本不应被依赖。
- 可硬件加速:SeaHash被设计得可以由ASIC以极高的性能实现。
一个警告!
这不是一个加密函数,绝对不应该用作加密函数。如果您需要一个好的加密散列函数,请使用SHA-3(Keccak)或BLAKE2。
它不安全,也不是为了安全而设计的。它的目标是生成高质量伪随机输出,碰撞少,同时速度快。
基准测试
在普通硬件上,它预计在2.5 GHz CPU上以大约5.9-6.7 GB/S的速度运行。在并行处理非常大的缓冲区时,可以进一步看到改进。
| 功能 | 质量 | 每字节周期数(越低越好) | 作者 |
|---|---|---|---|
| SeaHash | 优秀 | 0.24 | Ticki |
| xxHash | 优秀 | 0.31 | Collet |
| MetroHash | 优秀 | 0.35 | Rogers |
| Murmur | 优秀 | 0.64 | Appleby |
| Rabin | 中等 | 1.51 | Rabin |
| CityHash | 优秀 | 1.62 | Pike, Alakuijala |
| LoseLose | 糟糕 | 2.01 | Kernighan, Ritchie |
| FNV | 差 | 3.12 | Fowler, Noll, Vo |
| SipHash | 伪随机 | 3.21 | Aumasson, Bernstein |
| CRC | 好 | 3.91 | Peterson |
| DJB2 | 差 | 4.13 | Bernstein |
理想架构
SeaHash是为目前最常用的架构设计和优化的
- 小端
- 64位
- 64或更多字节缓存行
- 4或更多指令流水线
- 4或更多64位寄存器
不满足上述要求的东西将表现更差,最多低30-40%。请注意,这意味着它仍然比CityHash(约1 GB/S)、MurmurHash(约2.6 GB/S)、FNV(约0.5 GB/S)等要快。
实现性能
就像任何好的通用哈希函数一样,SeaHash一次读取8个字节,有效地将运行时间减少了约5个数量级。
其次,SeaHash通过充分利用指令级并行性来实现性能。具体来说,它在每一轮中获取4个整数,并独立地扩散它们。这产生了四个不同的状态,最终将它们组合起来。
统计保证
SeaHash附带有关输出统计性质的某些已证明的保证
- 选择一些n-字节序列s。与s发生碰撞的n-字节序列的数量与s的选择无关(所有等价类大小相等)。
- 如果您翻转输入中的任何位,则输出中任何位被翻转的概率为0.5。
- 均匀分布字节的序列的哈希值本身也是均匀分布的。
第一个保证可以通过演绎得出,通过证明扩散函数是双射的(反转XOR并找到质数的同余逆元)。
第二个保证需要更复杂的计算:构建一个概率矩阵,将其设置为一定值(1),然后通过相应的操作应用变换。证明有点长,但相对简单。
第三个保证需要证明哈希值是一个树,使得
- 叶子表示输入值。
- 单子节点简化为子节点的扩散。
- 多个子节点简化为子节点的总和。
然后简单地表明这些简化将均匀分布变量转换为均匀分布变量。
内部工作原理
从技术角度讲,SeaHash遵循交替4状态长度填充的Merkle-Damgård构造,带有XOR扩散压缩函数(点击放大)
[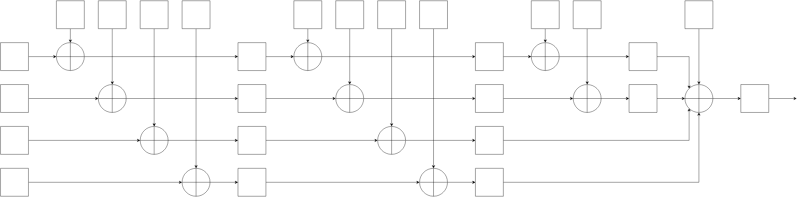 ] (http://ticki.github.io/img/seahash_construction_diagram.svg)
] (http://ticki.github.io/img/seahash_construction_diagram.svg)
它从4个初始状态开始,然后在这些状态之间交替(增量,4上回绕)并与相应的块进行XOR。当一个状态已被访问时,应用扩散函数(f)。
在处理完所有块之后,将所有状态XOR到写入的字节数。然后将总和传递给扩散函数,它生成最终的哈希值。
扩散函数如下所示。
x ← px
x ← x ⊕ ((x ≫ 32) ≫ (x ≫ 60))
x ← px
拥有四个完全隔离的状态(请注意,没有混合轮,因此它们是完全独立的)的优势是可以实现快速并行处理。例如,如果我要对1TB数据进行哈希处理,我可以启动四个线程,它们可以在最后一轮之前独立运行,无需进行任何通信或同步。
如果扩散函数(f)是密码学安全的,它将轻松通过密码分析。这看起来可能并不重要,因为它显然不是密码学安全的,但它告诉我们一些关于内部语义的信息。特别是,任何具有足够统计质量的扩散函数都将在这项构建中成为一个好的哈希函数。
阅读博客文章获取更多详细信息。
ASIC版本
SeaHash被特别设计,使其可以以ASIC的形式高效实现,同时只使用非常少的晶体管。
规格说明
请参阅参考模块。
致谢
除了我自己(@ticki)之外,还有一些其他的人帮助创建了它。Joshua Landau建议使用Melissa E. O'Neill创建的PCG系列扩散函数。Sokolov Yura在SeaHash中发现了多个错误。