1个不稳定版本
| 0.0.2 | 2023年9月8日 |
|---|
#2508 in 算法
150KB
3K SLoC
![]()
注意 此项目处于Alpha阶段,未经充分测试。请自行承担风险,并在发现问题时务必提交问题。
Rusted Pipe
RustedPipe是一个用于开发多线程机器学习管道的实时处理库,用Rust编写。
这是什么?
该项目旨在简化推理管道的创建。此类系统处理来自1个或多个来源的数据流,并按顺序或并行执行多个处理步骤,具体取决于要实现的目标。这些处理步骤形成一个计算图,以高帧率运行。图中每个节点可能需要超过1个输入来完成其计算。此软件使得数据流和同步对开发者来说变得非常简单。
一个示例图可能是一个用于在视频流中读取车牌的管道,其可能看起来像以下图:
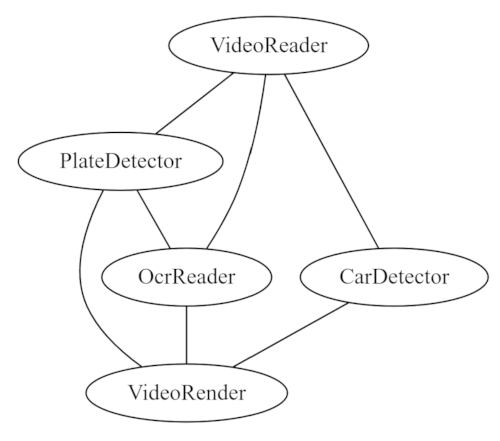 车牌检测器和OCR可以并行运行,因为它们独立处理数据,但它们的处理速度不同。我们也可以按顺序运行,但整体吞吐量会更慢。最终结果可能如下所示,具体取决于同步策略(下面将详细介绍)。
车牌检测器和OCR可以并行运行,因为它们独立处理数据,但它们的处理速度不同。我们也可以按顺序运行,但整体吞吐量会更慢。最终结果可能如下所示,具体取决于同步策略(下面将详细介绍)。 
Rusted pipe不是一个数据处理工具,也不解决其他并行性问题,如数据并行。对于这些,已经存在一些强大的工具,例如Rayon。实际上,Rayon可以在计算器内部使用。同样,这个工具也不是GStreamer的竞争对手。在示例中,您将看到如何将GStreamer与RustedPipe集成。
示例
在https://github.com/szandara/rusted_pipe_examples/tree/master/your_first_pipeline上查看最小示例。
在https://github.com/szandara/rusted_pipe_examples上查看更多管道示例。
同步
锈蚀管道提供了常见的同步策略,但同时也允许用户创建自己的策略。开箱即用的锈蚀管道提供了以下同步器
-
时间戳同步器:此同步器仅在数据的时间戳完全匹配时才匹配数据元组。它适用于离线计算和数据处理。它将尝试处理任何传入的数据。如果一个节点丢弃了数据包,可能会导致管道无限期地挂起。因此,缓冲区应该足够大,以考虑到慢速处理器。
-
实时同步器:此同步器更适合实时计算。它处理了慢速消费者丢弃数据包可能导致的潜在数据丢失。有三个主要变量可以控制用户的行为。
wait_all:只有当通道中的所有缓冲区都匹配时才输出数据元组。如果为false,处理器可能会调用只有部分读取通道数据的处理器。处理器应考虑数据不足的情况。tolerance_ns:匹配数据元组时的容忍纳秒数。0容忍度将仅匹配精确版本。
为了更好地解释同步的问题,让我们看一下上面的图。由于所有消费者都在不同的时间产生数据,确保以有意义的方式处理所有数据并不简单。
在这个例子中,有4个节点以不同的速度运行(在M1苹果CPU上)。这是一个人为糟糕的情况,因为消费者应该努力变得更快,以跟上实时。然而,它解释了数据是如何同步的。
- 一个以25 fps运行的视频制作人。
- 一个以2 fps运行的汽车深度学习模型。
- 一个以~1.2 fps运行的OCR tesseract模型。
- 一个结果渲染器,它收集视频图像和推理结果并生成输出。
| 时间戳同步器(离线) | 实时同步器(整体约1.2 FPS) |
|---|---|
 |
 |
可观察性
锈蚀管道与Prometheus度量指标和性能分析器集成。这两个工具都可以开启和关闭性能。默认情况下,度量指标在每个节点上开启。性能分析需要明确开启。
度量指标
默认情况下,RustedPipe在https://:9001/metrics提供度量指标,这可以通过配置图工具进行更改。
将您构造的Prometheus URL传递以更改端口。
let metrics = Metrics::builder().with_prometheus(&default_prometheus_address());
let mut graph = Graph::new(metrics);
默认度量指标包括
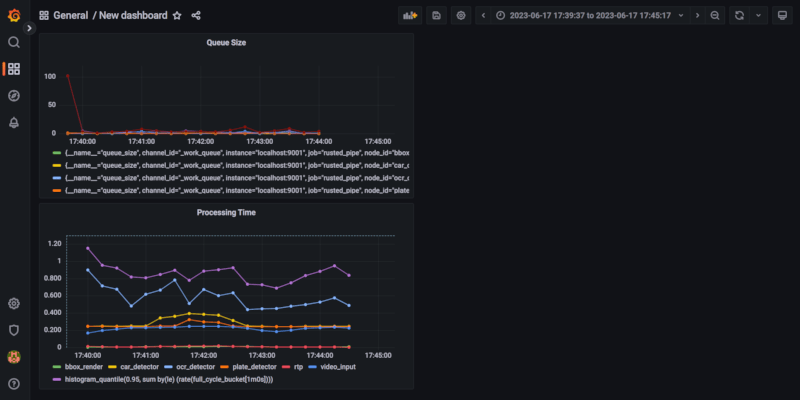
- 队列大小:每个节点队列中元素的数量,有助于监控您的管道行为。增长的队列通常是一个图设置不佳的症状。
- 处理时间:提供端到端处理时间以及每个节点的处理时间。有助于了解您应在何处优化队列。
为了消费这些度量指标,您需要运行Prometheus并具有Grafana之类的可视化工具。最终结果如下。请遵循许多在线指南之一来配置Grafana和Prometheus。
性能分析器
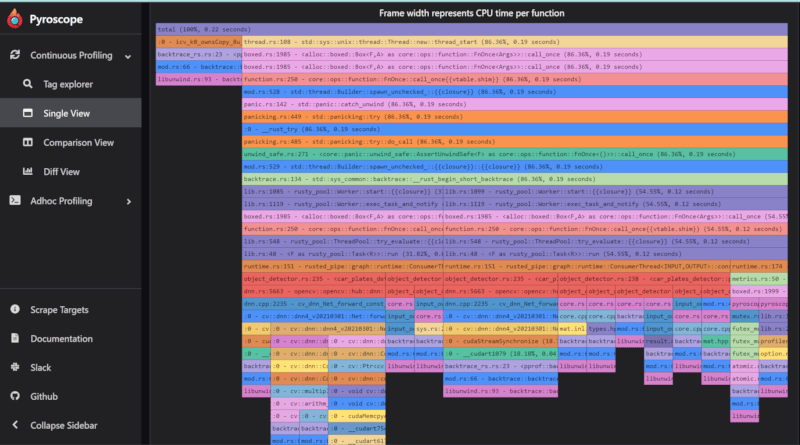
默认情况下,Rusted Pipe附带一个Pyroscope性能分析器,这与Prometheus不同,它设置为推送模式。如果激活,Pyroscope将每10秒向Pyroscope服务器发送度量指标。要创建此端点,请在其系统中或远程安装Pyroscope并配置图以向那里发送度量指标。
请注意,激活性能分析器将为您的计算添加一定的开销,并且仅应用于开发。
在下面的代码片段中,我们启动一个带有性能分析器激活的图。
let metrics = Metrics::builder().with_pyroscope(&default_pyroscope_address());
let mut graph = Graph::new(metrics);
每个节点将创建一个带有其ID的标签,并有助于分析节点计算时间。
动机
机器人学家经常使用类似ROS的工具来创建节点,这些节点像服务一样处理数据,以并行处理数据并将数据移动到计算图中的下一个节点。然而,此类消息交换存在序列化问题,这已被以不同的方式解决。
存在更多框架,使用内存缓冲区解决相同的问题。其中两个臭名昭著的框架是GStreamer和Mediapipe(更多在替代方案中)。RustedPipe在现有系统之上进行了改进
- 严格的类型检查(管道在编译时失败)。
- Rust内存管理会使共享无效数据变得困难。
- 具有节点之间简化的时间同步。
- 100%用Rust编写。
替代方案
Mediapipe启发了这项工作的大部分,然而,这个库试图克服它的一些局限性。
- 缺乏严格的类型检查。Mediapipe计算器接口是
Process(CalculatorContext* cc),其中计算器是您计算图的节点处理。数据被转换为期望的类型,但在编译时没有进行检查。 - Mediapipe专注于算法分布。大部分代码绑定到他们的计算器和算法上,除非您在Bazel生态系统中工作,否则很难将Mediapipe与您自己的计算器集成或扩展。
- Mediapipe没有Rust支持,也没有像Rust那样的编译器帮助来管理数据交换。通过传递引用,人们很容易搞乱内存访问。
GStreamer不是RustedPipe的直接竞争对手,但它经常被提到作为替代方案。有些人已经在Gstreamer之上构建了类似工具(例如DeepStream或https://nnstreamer.ai/)。虽然这些库很强大,但它们存在可用性问题
- 节点接口遵循与Mediapipe相同的模式,但没有类型。
- 总的来说,为GStreamer创建自己的处理单元是复杂的,学习曲线很高。GStreamer管道编译相对难以理解,依赖于操作系统库来存在。
- 虽然GStreamer最近推动了Rust支持,但可用性没有改变。
关键概念
贡献
- 克隆包
- 为您的MR分支
- 运行测试
- 向存储库发送拉取请求。
依赖关系
~19–36MB
~622K SLoC