1 个不稳定版本
| 新 0.1.0 | 2024年8月23日 |
|---|
#1 在 #bitcask 中
79KB
1.5K SLoC
rustcask
rustcask 是一个使用 Rust 实现的快速高效键值存储引擎。它基于 Bitcask, "一个用于快速键/值数据的日志结构哈希表"。
我在学习 Rust、探索不同的键值存储架构以及创建这个项目的过程中非常享受,因此我很乐意分享它。我鼓励您查看它,尤其是如果您有 Rust 的经验。我很乐意听到您的反馈!
在开发这个项目的过程中,我从博客文章 "使用 Rust 构建一个超快的键值存储" 中获得了许多灵感。
设计
Bitcask
rustcask 非常接近于 Bitcask 的设计。一个 rustcask 目录由数据文件组成。在任何时候,只有一个活动数据文件。写入被追加到该数据文件中,一旦达到一定大小,该文件将被关闭并标记为只读。
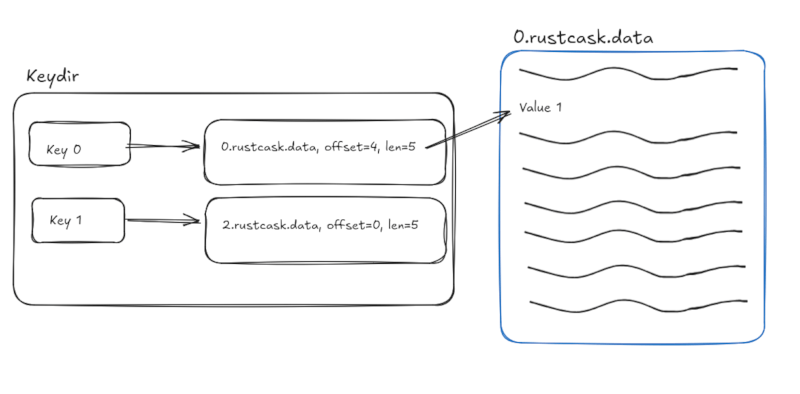
一个内存中的数据结构(见 keydir.rs)将每个键映射到对应数据文件中最最近写入的值的偏移量。这意味着读取只需要进行一次磁盘查找。
在重启时,rustcask 将遍历 rustcask 目录中的数据文件来重建 keydir。
通过顺序写入磁盘,Bitcask 和 rustcask 能够实现高写入吞吐量。然而,这种追加策略意味着过时的(被覆盖的)值会积累在数据文件中。这就是为什么 Bitcask 和 rustcask 提供了一个 merge 函数,该函数压缩数据文件并删除过时的键。在生产环境中,在不影响键值存储性能的情况下管理后台数据文件压缩是一个复杂的问题。
序列化格式
我决定使用 bincode crate,而不是 Bitcask 论文中描述的序列化格式。Bincode 是一个紧凑的序列化格式,它是专门为 Rust 序列化生态系统构建的。它非常容易使用。
并发
一个 RustCask 实例是线程安全的,并且可以被多个线程并发使用。
由于每个线程都有自己的 data_file_readers 集合,因此读取可以并发执行。但是,写入是串行的 - 所有线程共享同一个 active_data_file_writer。
错误处理
我受到了这篇文章的启发,Rust中的模块化错误,创建了针对每个API操作的独特错误类型:SetError、GetError、OpenError和RemoveError。
设置、获取、打开和删除是该应用的“失败单元”。每个操作可能因不同的原因而失败,并且应该有唯一的错误消息。因此,为每个操作定义独特的错误类型是有意义的。
另一种选择是有一个库级别的错误类型,如RustCaskError。库级别的错误类型很好,因为它们简化了代码。然而,它们迫使客户端处理可能与其调用的方法无关的错误。
其他设计决策
- 在Rustcask目录中为每个数据文件保持一个打开的文件句柄。这有助于避免昂贵的系统调用以打开文件。最终,我们将打开的文件句柄存储在LRU缓存中,这样就不会触及系统的打开文件限制。
- 不要使用内存映射I/O。相反,我使用
BufReader和BufWriter缓冲标准I/O调用。这是编写代码的最简单方法,我没有理由相信内存映射I/O会更有效率。将来可能值得测试,但我的猜测是结果将取决于工作负载。
Rustcask与Log-Structured Merge-Trees (LSM-trees)如LevelDB的比较
Rustcask相对于基于LSM-tree的存储引擎(如LevelDB)有哪些优势?
- Rustcask的设计比LevelDB这样的LSM-tree存储引擎要简单得多。因此,它是一个易于维护的代码库。
- Rustcask的读放大比LevelDB小。例如,如WiscKey论文中所述,LevelDB有很高的读放大,因为您可能需要读取多达14个SSTable文件才能找到所需的数据。在Rustcask中,我们将在内存中存储整个keydir,这意味着读取只需要单次寻道。
LSM-tree如LevelDB相对于Rustcask的优势
- Rustcask将整个键集存储在内存中。如果您的键集无法放入内存,那么LevelDB是一个更好的替代品,因为它在内存中存储了键集的稀疏索引。
- LevelDB支持高效的范围查询,因为它将值以排序顺序写入磁盘。
- LevelDB在管理后台压缩过程中可能更有效率。
使用方法
有关使用示例,请参阅集成测试或性能测试。您还可以使用以下命令查看cargo文档:cargo doc --open。
以下是一个简单的设置-获取示例
let mut store = RustCask::builder().open(rustcask_dir).unwrap();
let key = "leader-node".as_bytes().to_vec();
let value = "instance-a".as_bytes().to_vec();
store.set(key.clone(), value).unwrap();
store.get(&key)
同步模式
默认情况下,Rustcask的写入不会立即刷新到磁盘。这提高了性能,因为操作系统可以将写入批量到磁盘。但是,您可以通过启用同步模式强制Rustcask立即将所有写入刷新到磁盘。
let store = RustCask::builder()
.set_sync_mode(true)
.open(temp_dir.path())
.unwrap();
日志记录
Rustcask链接到log crate,并使用提供的宏来记录有用的信息。为了使这些日志消息输出到某处,消费者应提供自己的日志记录实现。
合并
在进行频繁的关键更新时,rustcask目录中的数据文件会持续增长,因为旧值不会被更新或就地删除。
merge函数将活动键值写入一组新的数据文件,并清理旧数据文件。通过删除过时值,这减少了rustcask目录内容的尺寸。
性能测试
您可以在benches目录下找到性能测试。
我发现,对于写密集型的工作负载,我能够实现非常接近硬盘最大写入带宽的写入带宽
在我的本地台式机上,我有一个支持高达560 MB/s的顺序写入吞吐量的硬盘。
bench_writes工作负载表明Rustcask能够实现高达503 MB/s的写入吞吐量。
Timer precision: 17 ns
readwrite fastest │ slowest │ median │ mean │ samples │ iters
├─ bench_writes 18.12 µs │ 75.35 µs │ 20.3 µs │ 22.72 µs │ 100 │ 100
│ 503.2 MB/s │ 121 MB/s │ 449.2 MB/s │ 401.2 MB/s
读取工作负载也表现出色,因为它们只需要单个磁盘寻道,而操作系统的缓存层会消除许多磁盘访问。
接下来是什么?
提示文件
我从未实现过Bitcask论文中描述的提示文件。没有提示文件,在现有的rustcask目录上启动一个生产规模数据库将花费很长时间。然而,我从未真正打算将其用于生产环境,这就是为什么我将其省略了。
性能指标
为了使Rustcask准备就绪用于生产,它需要输出性能指标。例如,压缩期间节省的字节数,给定文件中死亡键与活动键的数量等。
轻量级形式化方法
我最近阅读了亚马逊的这篇论文,使用轻量级形式化方法验证Amazon S3中的键值存储节点。
作者们讨论了他们如何使用轻量级形式化方法来验证S3背后的键值存储引擎ShardStore。ShardStore比Rustcask复杂得多,但我仍然认为这篇论文中有一些有趣的见解可以应用在这里。
例如,我想编写一个测试框架,执行基于属性的测试(第4.1节),以检查Rustcask与简单的基于HashMap的模型之间的兼容性。
依赖关系
~6–9MB
~154K SLoC