9 个版本
| 0.1.8 | 2022 年 11 月 13 日 |
|---|---|
| 0.1.7 | 2022 年 11 月 5 日 |
| 0.1.1 | 2022 年 10 月 24 日 |
243 在 HTTP 服务器 中
每月 39 次下载
500KB
11K SLoC
☁ Puff ☁
Puff 是一个内置 Rust 异步运行时的 Python,支持 GraphQL、ASGI、WSGI、Postgres、PubSub、Redis、分布式任务和 HTTP2 客户端。
![]()
![]()
![]()
什么是 Puff?
Puff 是一个为 Python 提供所有功能的“深度堆栈”。它是将 Python 和 Rust 之间的障碍最小化以释放高级语言全部潜能的实验。使用标准 CPython 构建自己的运行时,并用 Rust 扩展它。想象一下,如果 GraphQL、Postgres、Redis 和 PubSub、分布式任务都是标准库的一部分。那就是 Puff。
以前将 Rust 集成到 Python 的方法是通过创建一个使用 rust 的 Python 包并将其从 Python 中导入。这种方法存在一些缺陷,因为 rust 包无法协作。Puff 为 Rust 提供了自己的层,因此您可以在 Rust 中构建一组协同工作的工具,而无需再次进入 Python。
高层次的概述是 Puff 为 Python
- 在 Rust 的 Tokio 上提供 Greenlets。
- 高性能 HTTP 服务器 - 将 Axum 与 Python WSGI 应用程序(Flask、Django 等)结合使用
- Rust / Python 在同一进程中本地化,无需套接字或序列化。
- 与 Rust 集成的 AsyncIO / uvloop / ASGI
- 易于使用的 GraphQL 服务
- 多节点 Pub/Sub
- Rust 级别 Redis 池
- Rust 级别 Postgres 池
- WebSocket
- HTTP 客户端
- 分布式、至少一次、优先级和计划任务队列
- 与 Psycopg2 半兼容(希望足够好,适用于大多数 Django)
- 一种安全方便的方式进入 rust 以获得最大性能
想法是Rust和Python彼此几乎完美互补,构建一个让它们交流的框架,将提高生产效率、可扩展性和性能。
| Python | Rust |
|---|---|
| ✅ 高级 | ✅ 低级 |
| ✅ 工具和包众多 | ✅ 工具和包众多 |
| ✅ 入门容易 | ✅ 入门容易 |
| 🟡 解释型(牺牲速度换取生产力) | 🟡 编译型(牺牲生产力换取速度) |
| ✅ 容易掌握 | ❌ 学习曲线陡峭 |
| ✅ 快速迭代原型 | ❌ 需要计划以确保正确性 |
| ✅ 搜索问题,复制粘贴,就能工作。 | ❌ 示例较少 |
| ❌ 弱类型系统 | ✅ 优秀的类型系统 |
| ❌ GIL阻止多线程 | ✅ 高性能 |
| ❌ 不够安全 | ✅ 安全 |
deepstack的禅宗在于认识到没有哪种语言是终极答案。通过使用Python进行快速开发,并用Rust优化找到的最关键路径,而不是追求完美,而是寻求进步。找到平衡。
快速入门
将Rust安装到您的平台上以编译Puff。
安装Rust
按照说明在您的平台上安装Cargo。
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
安装Puff
使用Cargo安装Puff。
cargo install puff-rs
Puff需要Python >= 3.10。Python的Poetry是可选的。
您的Puff项目需要找到Python项目。即使它们在同一文件夹中,也必须将它们添加到PYTHONPATH。
设置Puff项目的一种方法是
poetry new my_puff_proj_py
cd my_puff_proj_py
poetry add puff-py
现在从my_puff_proj_py中,您可以使用poetry run puff运行您的项目,以从Poetry中访问Cargo并将虚拟环境暴露给Puff。
Python项目不需要在Rust包内部。它只需要在PYTHONPATH或在虚拟env内部。如果您不想使用Poetry,运行Puff时将不得不设置虚拟环境。
Puff ♥ Python
Puff中的Python程序通过在Rust中构建一个Program并在其中注册Python函数来运行。
Python方法被初始化并在Puff运行时作为一个greenlet运行。
创建一个puff.toml
[[commands]]
function = "my_puff_proj_py.hello_world"
command_name = "hello_world"
Python
import puff
# Standard python functions run on Puff greenlets. You can only use special Puff async functions without pausing other greenlets.
def hello_world():
fn = "my_file.zip"
result_bytes = puff.read_file_bytes(fn) # Puff async function that runs in Tokio.
result_py_bytes = do_some_blocking_work(fn) # Python blocking that spawns a thread to prevent pausing the greenlet thread.
print(f"Hello from python!! Zip is {len(result_bytes)} bytes long from rust and {len(result_py_bytes)} bytes from Python.")
# 100% of python packages are compatible by wrapping them in blocking decorator.
@puff.blocking
def do_some_blocking_work(fn):
with open(fn, "rb") as f:
return f.read()
Puff ♥ Django
虽然它可以运行任何WSGI应用,但Puff特别青睐Django。Puff认为业务逻辑应该在更高的层实现,而Rust应该用作优化。Django是一个使用Puff作为高级框架的完美选择,因为它处理迁移、管理台等。Puff模仿psycopg2驱动程序和缓存,以便Django使用Puff数据库和Redis池。
用几行代码将您的同步Django项目转换成一个高度并发的Puff程序。Puff包装了管理命令,所以迁移等命令都按预期工作。简单地运行poetry run run_cargo django [command],而不是使用./manage.py [command]。例如,poetry run run_cargo django migrate。不要使用Django的开发服务器,而要使用Puff的poetry run run_cargo serve。
创建一个puff.toml
django = true
wsgi = "my_django_application.wsgi.application"
[[postgres]]
name = "default"
[[redis]]
name = "default"
在您的Django应用中使用Puff的每个地方。甚至可以创建使用Rust的Django管理命令!
有关更完整的Django示例,请参阅puff-py存储库。
Puff ♥ Graphql
Puff通过Python类定义暴露GraphQL的Mutations、Queries和Subscriptions。Puff GraphQL引擎的核心“杀手级特性”是它在“层基础”上工作,而不是在Node基础上。这允许GraphQL的每一步都能一次性收集查询所需的所有完整数据。这避免了传统上与GraphQL相关联的令人头疼的n+1和数据加载器开销。
GraphQL Python函数可以将纯SQL查询传递给Puff,Puff将渲染和转换查询,无需返回到Python。这允许Python GraphQL接口在很大程度上是I/O自由的,但在需要时仍然可以灵活地访问Puff资源。
from dataclasses import dataclass
from typing import Optional, Tuple, List, Any
from puff.pubsub import global_pubsub
pubsub = global_pubsub
CHANNEL = "my_puff_chat_channel"
@dataclass
class SomeInputObject:
some_count: int
some_string: str
@dataclass
class SomeObject:
field1: int
field2: str
@dataclass
class DbObject:
was_input: int
title: str
@classmethod
def child_sub_query(cls, context, /) -> Tuple[DbObject, str, List[Any], List[str], List[str]]:
# Extract column values from the previous layer to use in this one.
parent_values = [r[0] for r in context.parent_values(["field1"])]
sql_q = "SELECT a::int as was_input, $2 as title FROM unnest($1::int[]) a"
# returning a sql query along with 2 lists allow you to correlate and join the parent with the child.
return ..., sql_q, [parent_values, "from child"], ["field1"], ["was_input"]
@dataclass
class Query:
@classmethod
def hello_world(cls, parents, context, /, my_input: int) -> Tuple[List[DbObject], str, List[Any]]:
# Return a Raw query for Puff to execute in Postgres.
# The ellipsis is a placeholder allowing the Python type system to know which Field type it should transform into.
return ..., "SELECT $1::int as was_input, \'hi from pg\'::TEXT as title", [my_input]
@classmethod
def hello_world_object(cls, parents, context, /, my_input: List[SomeInputObject]) -> Tuple[List[SomeObject], List[SomeObject]]:
objs = [SomeObject(field1=0, field2="Python object")]
if my_input:
for inp in my_input:
objs.append(SomeObject(field1=inp.some_count, field2=inp.some_string))
# Return some normal Python objects.
return ..., objs
@classmethod
def new_connection_id(cls, context, /) -> str:
# Get a new connection identifier for pubsub.
return pubsub.new_connection_id()
@dataclass
class Mutation:
@classmethod
def send_message_to_channel(cls, context, /, connection_id: str, message: str) -> bool:
print(context.auth_token) # Authoritzation bearer token passed in the context
return pubsub.publish_as(connection_id, CHANNEL, message)
@dataclass
class MessageObject:
message_text: str
from_connection_id: str
num_processed: int
@dataclass
class Subscription:
@classmethod
def read_messages_from_channel(cls, context, /, connection_id: Optional[str] = None) -> Iterable[MessageObject]:
if connection_id is not None:
conn = pubsub.connection_with_id(connection_id)
else:
conn = pubsub.connection()
conn.subscribe(CHANNEL)
num_processed = 0
while msg := conn.receive():
from_connection_id = msg.from_connection_id
# Filter out messages from yourself.
if connection_id != from_connection_id:
yield MessageObject(message_text=msg.text, from_connection_id=from_connection_id, num_processed=num_processed)
num_processed += 1
@dataclass
class Schema:
query: Query
mutation: Mutation
subscription: Subscription
Rust
django = true
pytest = true
[[postgres]]
enable = true
[[redis]]
enable = true
[[pubsub]]
enable = true
[[graphql]]
schema = "my_python_gql_app.Schema"
url = "/graphql/"
subscriptions_url = "/subscriptions/"
playground_url = "/playground/"
[[commands]]
function = "my_puff_proj_py.hello_world"
command_name = "hello_world"
生成的GraphQL模式如下
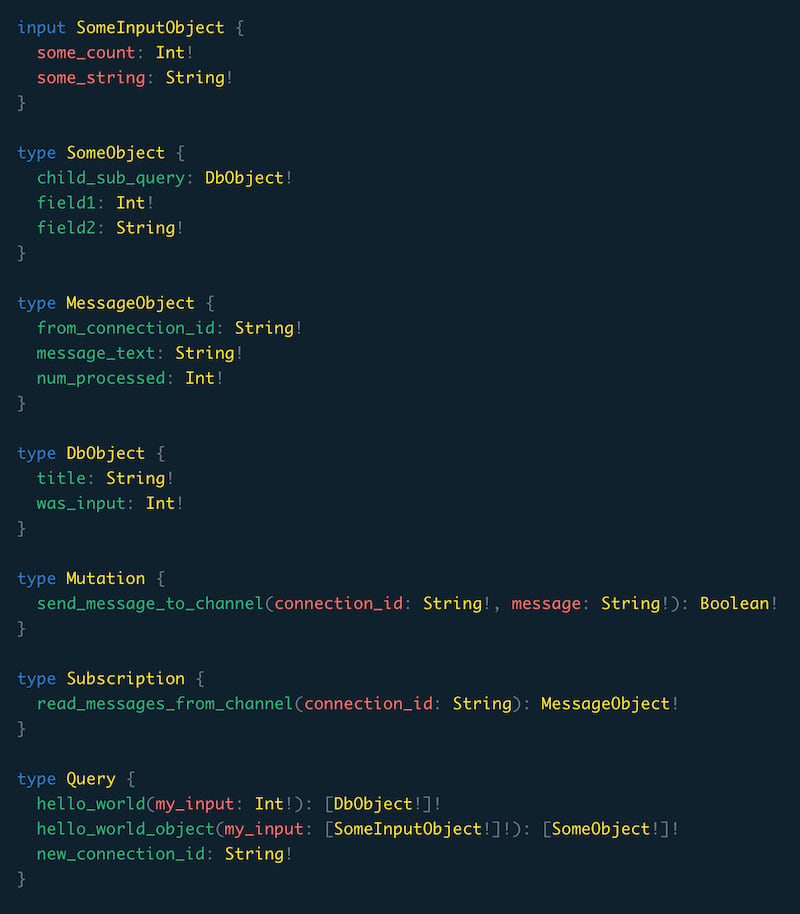
除了使其更容易编写最快的查询之外,基于层的架构还允许Puff充分利用多线程异步Rust运行时,并独立解决分支。这为您提供了即插即用的性能优势。
Puff ♥ Pytest
通过将PytestCommand添加到您的程序中,与pytest轻松集成以测试您的GraphQL和Puff应用程序。只需像往常一样编写测试,只需用puff pytest运行它们即可。
pytest = true
from hello_world_py_app import __version__
from puff.graphql import global_graphql
gql = global_graphql
def test_version():
assert __version__ == '0.1.0'
def test_gql():
QUERY = """
query {
hello_world(my_input: 3) {
title
was_input
}
}
"""
result = gql.query(QUERY, {})
assert 'data' in result
assert 'errors' not in result
assert result['data']["hello_world"][0]["title"] == "hi from pg"
assert result['data']["hello_world"][0]["was_input"] == 3
Puff ♥ AsyncIO
Puff具有ASGI和asyncio的内置集成。您首先需要配置RuntimeConfig以使用它。当启动事件循环时,Puff将自动使用uvloop(如果已安装)。
asgiref.sync.async_to_sync和asgiref.sync.sync_to_async都已被修补,因此您可以轻松地从异步调用puff greenlets或从puff greenlets调用异步。
from fastapi import FastAPI
from puff import global_state, wrap_async
state = global_state
app = FastAPI()
@app.get("/fast-api")
async def read_root():
result = await wrap_async(lambda r: state.hello_from_rust_async(r, "hello from asyncio"))
return {"Hello": "World", "from": "Fast API", "rust_value": result}
puff.toml
asyncio = true
asgi = "my_python_app.app"
Puff ♥ Django + GraphQL
Puff GraphQL与Django无缝集成。将Django查询集转换为SQL,将所有计算卸载到Rust。或者用borrow_db_context装饰,并让Django能够访问GraphQL连接,允许您在复杂的查找中回退到Django的稳健性。
from dataclasses import dataclass
from puff import graphql
from polls.models import Question, Choice
from django.utils import timezone
from puff.contrib.django import query_and_params
@dataclass
class ChoiceObject:
id: int
question_id: int
choice_text: str
votes: int
@dataclass
class QuestionObject:
id: int
pub_date: str
question_text: str
@classmethod
def choices(cls, context, /) -> Tuple[List[ChoiceObject], str, List[Any], List[str], List[str]]:
# Extract column values from the previous layer to use in this one.
parent_values = [r[0] for r in context.parent_values(["id"])]
# Convert a Django queryset to sql and params to pass off to Puff. This function does 0 IO in Python.
qs = Choice.objects.filter(question_id__in=parent_values)
sql_q, params = query_and_params(qs)
return ..., sql_q, params, ["id"], ["question_id"]
@dataclass
class Query:
@classmethod
def questions(cls, context, /) -> Tuple[List[QuestionObject], str, List[Any]]:
# Convert a Django queryset to sql and params to pass off to Puff. This function does 0 IO in Python.
qs = Question.objects.all()
sql_q, params = query_and_params(qs)
return ..., sql_q, params
@classmethod
@graphql.borrow_db_context # Decorate with borrow_db_context to use same DB connection in Django as the rest of GQL
def question_objs(cls, context, /) -> Tuple[List[QuestionObject], List[Any]]:
# You can also compute the python values with Django and hand them off to Puff.
# This version of the same `questions` field, is slower since Django is constructing the objects.
objs = list(Question.objects.all())
return ..., objs
@dataclass
class Mutation:
@classmethod
@graphql.borrow_db_context # Decorate with borrow_db_context to use same DB connection in Django as the rest of GQL
def create_question(cls, context, /, question_text: str) -> QuestionObject:
question = Question.objects.create(question_text=question_text, pub_date=timezone.now())
return question
@dataclass
class Subscription:
pass
@dataclass
class Schema:
query: Query
mutation: Mutation
subscription: Subscription
Puff ♥ 分布式任务
有时您需要在将来执行一个函数,或者您需要执行它,但现在并不关心结果。例如,您可能有一个webhook或要发送的电子邮件。
Puff提供了作为标准库一部分的分布式队列抽象。它由Redis驱动,具有将任务跨节点以优先级、延迟和重试的方式分布的能力。提交到队列中的作业可以持久化(如果Redis配置为持久化到磁盘,则附加),因此您可以关闭并重新启动服务器,而无需担心丢失队列中的函数。
分布式队列在每个Puff实例的后台运行。要有一个工作实例,请使用WaitForever命令。您的HTTP服务器还可以处理分发、处理和运行后台任务,这对于小型项目很有用,并且通过使用wait_forever添加更多处理能力,可以很好地扩展。
任务是一个Python函数,它接受一个JSONable的有效负载,您关心执行,但不关心确切的时间和地点。JSONable类型是简单的Python结构(字典、列表、字符串等),可以序列化为JSON。队列将监视任务,并在timeout_ms内未得到结果时重试它们。请注意,如果您没有正确配置超时,您可能会有多个相同的任务在运行,因此如果您发送HTTP请求或其他可能需要一段时间才能响应的任务,请正确配置超时。任务应返回一个JSONable的结果,该结果将保留keep_results_for_ms秒。
请只将顶层函数传递给schedule_function,这些函数可以导入(没有lambda或闭包)。此函数应在所有Puff实例上可访问。
通过使用 scheduled_time_unix_ms 来实现优先级。工作者将所有任务按此值排序,并执行到当前时间为止的第一个任务。因此,如果您调度 scheduled_time_unix_ms=1,则该函数将在第一个可用时执行。使用 scheduled_time_unix_ms=1,scheduled_time_unix_ms=2。 scheduled_time_unix_ms=3 等等,为不同类型的高优先级任务。请注意,如果您不够快地处理这些高优先级任务,可能会导致其他任务饿死。默认情况下,Puff 使用当前 Unix 时间调度新任务以实现“公平”并提供“先进先出”的顺序感。您还可以将此值设置为将来的 Unix 时间戳以延迟任务执行。
您可以运行任意数量的任务(使用 set_task_queue_concurrent_tasks),但是通过增加此值,在监控和查找新任务方面会有一定的开销。默认值为 num_cpu x 4
请参阅 使用 Puff 构建RPC 中的其他设计模式。
from puff.task_queue import global_task_queue
task_queue = global_task_queue
def run_main():
all_tasks = []
for x in range(100):
# Schedule some tasks on any coroutine thread of any Puff instance connected through Redis.
task1 = task_queue.schedule_function(my_awesome_task, {"type": "coroutine", "x": [x]}, timeout_ms=100, keep_results_for_ms=5 * 1000)
# Override `scheduled_time_unix_ms` so that async tasks execute with priority over the coroutine tasks.
# Notice that since all of these tasks have the same priority, they may be executed out of the order they were scheduled.
task2 = task_queue.schedule_function(my_awesome_task_async, {"type": "async", "x": [x]}, scheduled_time_unix_ms=1)
# These tasks will keep their order since their priorities as defined by `scheduled_time_unix_ms` match the order scheduled.
task3 = task_queue.schedule_function(my_awesome_task_async, {"type": "async-ordered", "x": [x]}, scheduled_time_unix_ms=x)
print(f"Put tasks {task1}, {task2}, {task3} in queue")
all_tasks.append(task1)
all_tasks.append(task2)
all_tasks.append(task3)
for task in all_tasks:
result = task_queue.wait_for_task_result(task, 100, 1000)
print(f"{task} returned {result}")
def my_awesome_task(payload):
print(f"In task {payload}")
return payload["x"][0]
async def my_awesome_task_async(payload):
print(f"In async task {payload}")
return payload["x"][0]
puff.toml
asyncio = true
[[task_queue]]
enable = true
Puff ♥ HTTP
Puff 内置了一个基于 reqwests 的异步 HTTP 客户端,它可以处理 HTTP2(由 Puff WSGI/ASGI 集成提供)并重用连接。它使用 Rust 超快速地编码和解码 JSON。
from puff.http import global_http_client
http_client = global_http_client
async def do_http_request():
this_response = await http_client.post("https://:7777/", json={"my_data": ["some", "json_data"]})
return await this_response.json()
def do_http_request_greenlet():
"""greenlets can use the same async functions. Puff will automatically handle awaiting and context switching."""
this_response = http_client.post("https://:7777/", json={"my_data": ["some", "json_data"]})
return this_response.json()
您可以通过 RuntimeConfig 设置 HTTP 客户端选项。如果您的程序只与其他 Puff 实例或 HTTP2 服务通信,则仅启用 HTTP2 是有意义的。您还可以通过此方法配置用户代理以及许多其他 HTTP 选项。
asyncio = true
[[http_client]]
http2_prior_knowledge = true
连接到一切...
Puff 支持多个服务池。
[[postgres]]
name = "default"
[[postgres]]
name = "readonly"
[[postgres]]
name = "audit"
[[redis]]
name = "default"
[[redis]]
name = "other"
[[http_client]]
name = "default"
[[http_client]]
name = "internal"
http2_prior_knowledge = true
[[pubsub]]
name = "default"
[[pubsub]]
name = "otherpubsub"
[[graphql]]
schema = "my_python_gql_app.Schema"
url = "/graphql/"
subscriptions_url = "/subscriptions/"
playground_url = "/playground/"
database = "readonly"
[[graphql]]
name = "audit"
schema = "my_python_gql_app.AuditSchema"
url = "/audit/graphql/"
subscriptions_url = "/audit/subscriptions/"
playground_url = "/audit/playground/"
database = "audit"
产生具有以下选项的程序
Options:
--default-postgres-url <DEFAULT_POSTGRES_URL>
Postgres pool configuration for 'default'. [env: PUFF_DEFAULT_POSTGRES_URL=] [default: postgres://postgres:password@localhost:5432/postgres]
--audit-postgres-url <AUDIT_POSTGRES_URL>
Postgres pool configuration for 'audit'. [env: PUFF_AUDIT_POSTGRES_URL=] [default: postgres://postgres:password@localhost:5432/postgres]
--readonly-postgres-url <READONLY_POSTGRES_URL>
Postgres pool configuration for 'readonly'. [env: PUFF_READONLY_POSTGRES_URL=] [default: postgres://postgres:password@localhost:5432/postgres]
--default-redis-url <DEFAULT_REDIS_URL>
Redis pool configuration for 'default'. [env: PUFF_DEFAULT_REDIS_URL=] [default: redis://:6379]
--other-redis-url <OTHER_REDIS_URL>
Redis pool configuration for 'other'. [env: PUFF_OTHER_REDIS_URL=] [default: redis://:6379]
--default-pubsub-url <DEFAULT_PUBSUB_URL>
PubSub configuration for 'default'. [env: PUFF_DEFAULT_PUBSUB_URL=] [default: redis://:6379]
--otherpubsub-pubsub-url <OTHERPUBSUB_PUBSUB_URL>
PubSub configuration for 'otherpubsub'. [env: PUFF_OTHERPUBSUB_PUBSUB_URL=] [default: redis://:6379]
深度堆栈
Puff 设计得如此之好,以至于您可以将其作为库来构建自己的版本。如果您的项目需要,这允许进行令人难以置信的性能优化。
架构
Puff 由多线程的 Tokio 运行时和一个单线程组成,该线程在 Greenlets 上运行所有 Python 计算。Python 将 IO 卸载到 Tokio,它调度 IO 并在必要时将其返回。

状态
这处于非常早期的开发阶段。项目的范围是雄心勃勃的。预计会有一些问题。
Puff 的最终目标可能是像 gevent 的 monkeypatch 一样,自动使现有项目与 Puff 兼容。
依赖项
~25–40MB
~712K SLoC