5个不稳定版本
| 0.3.1 | 2024年4月21日 |
|---|---|
| 0.3.0 | 2024年4月21日 |
| 0.2.1 | 2024年4月18日 |
| 0.2.0 | 2024年4月18日 |
| 0.1.0 | 2024年4月18日 |
#750 in 算法
每月24次下载
520KB
186 行
Phi累积检测器
简介
这是phi累积检测算法(在本论文中介绍)在Rust中的可插拔实现。该算法通过监控事件之间的时间来检测系统行为的变化。假设你想监控服务器是否存活(想象一个主/从配置),你想检查从机是否还在运行?你将如何做到这一点?
解决心跳问题
如果主节点注意到从机没有在固定的时间间隔内向我ping,我会认为它已经挂了。但有时从机只是稍微晚了点,比如间隔设置为500毫秒,从机在550毫秒时发送心跳ping,它不是已经死了吗?你该如何应对这种情况?
引入φ
φ定义为对监控系统失败的怀疑程度。该算法通过跟踪事件之间的时间并计算系统失败的概率来工作。该算法基于以下观察:在健康系统中,事件之间的时间遵循正态分布,而在失败系统中,事件之间的时间遵循具有更长尾部的分布。
φ值越高,在给定时间收到心跳的可能性就越低(正式定义见下文)
![]()
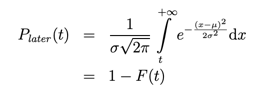
其中 F(t) 是正态分布的累积分布函数,μ 是正态分布的均值,σ 是正态分布的标准差,t 是事件之间的时间。
示例运行
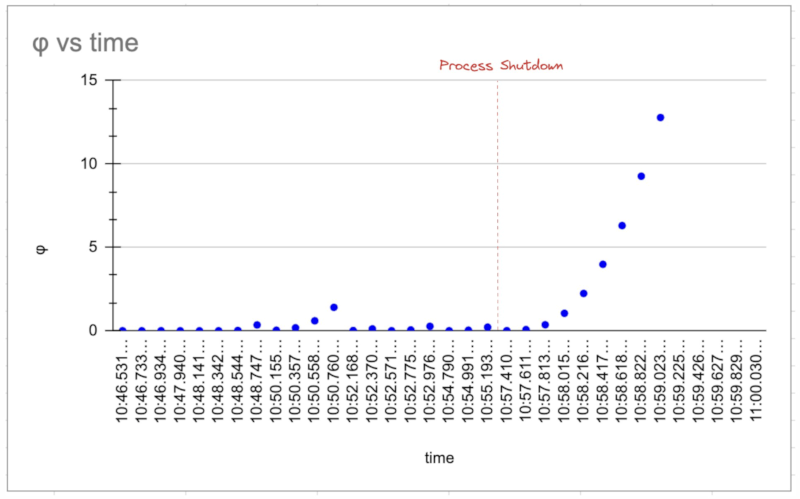
您可以使用examples/monitor.rs来模拟以下结果。图表表明,如果进程在红线处崩溃之前持续ping监控器,则怀疑水平通常很低。之后,怀疑水平将呈指数增长并趋于无穷大。您可以为任何阈值(例如:> 5.0)配置,以将进程视为已死。
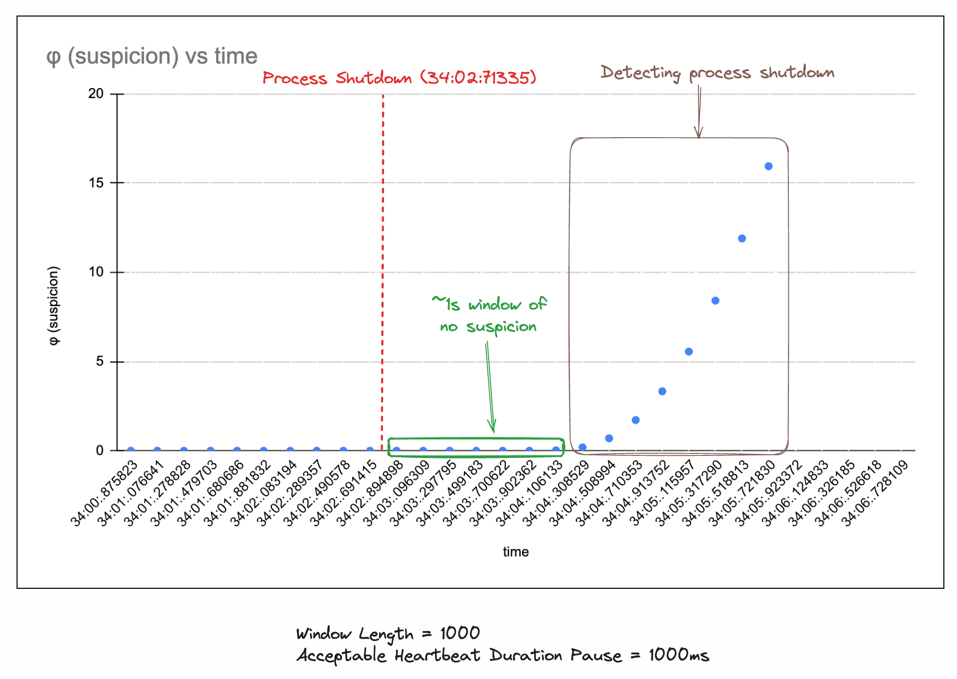
包括可接受的心跳暂停
您还可以包含一些暂停时间,以确保系统在因网络延迟而略微延迟的情况下不会被判定为死亡。您可以使用 ::with_acceptable_heartbeat_pause 创建具有可接受暂停时间的探测器。
依赖项
约10-20MB
约274K SLoC