3 个版本
| 0.1.2 | 2023年5月23日 |
|---|---|
| 0.1.1 | 2023年5月22日 |
| 0.1.0 | 2023年5月22日 |
2116 in 网页编程
42 个月下载量
300KB
1.5K SLoC
mlscraper-rust
自动生成用于网页抓取的 CSS 选择器
本项目受到 Python 包 mlscraper 的启发,但采用了不同的、更可扩展和可配置的方法来实现相同的效果。
示例
这是一个小示例(与 mlscraper 提供的相同),演示了 mlscraper-rust 如何自动生成简短的 CSS 选择器。
您可以通过在当前目录中运行 cargo run --release --example small 来运行此示例。
我们只需要告诉 mlscraper-rust 我们期望从网页中提取哪些值...
let html = reqwest::blocking::get("http://quotes.toscrape.com/author/Albert-Einstein/")
.expect("request") // Scrappy error handling for demonstration purposes
.text()
.expect("text");
let result = mlscraper_rust::train(
vec![html.as_str()],
vec![
AttributeBuilder::new("name")
.values(&[Some("Albert Einstein")])
.build(),
AttributeBuilder::new("born")
.values(&[Some("March 14, 1879")])
.build(),
],
Default::default(),
1
).expect("training");
println!("{:?}", result.selectors());
...然后它会输出它能够找到的最优(即最简洁)的选择器
{"出生": .作者-出生-日期, "姓名":h3}
现在我们可以使用训练好的 result 对象来抓取类似页面
let html = reqwest::blocking::get("http://quotes.toscrape.com/author/J-K-Rowling")
.expect("request")
.text()
.expect("text");
let dom = result.parse(&html)
.expect("parse");
result.attributes()
.for_each(|attr| {
println!("{attr}: {:?}", result.get_value(&dom, attr).ok().flatten())
})
这会输出
born: Some("July 31, 1965")
name: Some("J.K. Rowling")
与原始 mlscraper 类似,mlscraper-rust 在提供 多个 输入文件和 多个 属性值时发挥出全部潜力,例如
// ------- 8< ---------------------
// ... excerpt from examples/big.rs
let result = train(
// Multiple input documents
htmls.iter().map(|s| s.as_ref()).collect(),
vec![
// We expect this value to be "Defeat" on the first page, "Victory"
// on the second, etc.
AttributeBuilder::new("team0result")
.values(&[Some("Defeat"), Some("Victory"), Some("Victory")])
.build(),
// ------------------- >8 ---------
mlscraper-rust 将自动生成适用于所有提供的值的 所有 输入文档的 CSS 选择器。
相对于 mlscraper(Python)的优点
- 更好的性能:我们不是测试 $O(2^n)$ 个可能的选择器,而是随机生成 CSS 选择器,并使用基本的模糊算法迭代地改进它们。请参见下面的性能比较。
- 更小的占用空间:mlscraper(Python)有时在处理 30kb 的 HTML 文件时会被 oomkiller 杀死。我们的实现在许多文档和属性上没有问题(尽管我们可以使用一些多线程)-- 请参见
examples/big.rs。 - 处理缺失数据的正确方法:我们允许某些训练示例中存在缺失值,并提供不同的处理这些情况的方法(见MissingDataStrategy)。
- 处理重复数据的正确方法:如果一个值出现多次,你可以控制哪些元素应该被优先选择(见MultipleMatchesStrategy)。
- 可配置的数据源:你可以定义什么应该算作HTML标签的“文本”。
- 过滤:你可以添加自定义过滤器来控制生成的CSS选择器类型!
性能比较
我们对两个亚马逊产品页面(苹果iPhone,三星Galaxy)的mlscraper和mlscraper_rust性能进行了比较,这些页面已被下载到python_comparison/{amazon_iphone, amazon_galaxy}.html。
你可以在python_comparison/amazon.py(原始mlscraper python库)和examples/amazon.rs(我们自己的)中读取使用的基准测试代码。
我们比较了每种方法在“训练”方面的时间,即生成合适的选择器所需的时间。我们使用五次运行的平均时间。
| 抓取任务 | 原始mlscraper时间 | 我们的时间 | 加速比 | 原始mlscraper选择器 | 我们的选择器 |
|---|---|---|---|---|---|
| 提取产品名称 | 1771 ms | 25 ms | 71x | #landingImage |
#landingImage或#comparison_image |
| 提取产品价格 | 1122 ms | 21 ms | 53x | #base-product-price |
#base-product-price |
| 一次性提取名称和价格 | 6193 ms | 34 ms | 182x | 如上所述 | 如上所述 |
| 查找“加入购物车”按钮 | ? (> 5 min) | 16 ms | - | - | #comparison_add_to_cart_button3-announce |
大规模示例
所有这些优势都在你可以通过运行以下命令运行的big.rs大规模示例中得到证明:cargo run --release --example big。
它从leagueofgraphs.com抓取各种匹配数据。
mlscraper-rust提供了一个函数,可以突出显示DOM中选择到的元素,用红色边框表示。让程序运行一段时间后,这是“big”示例的输出
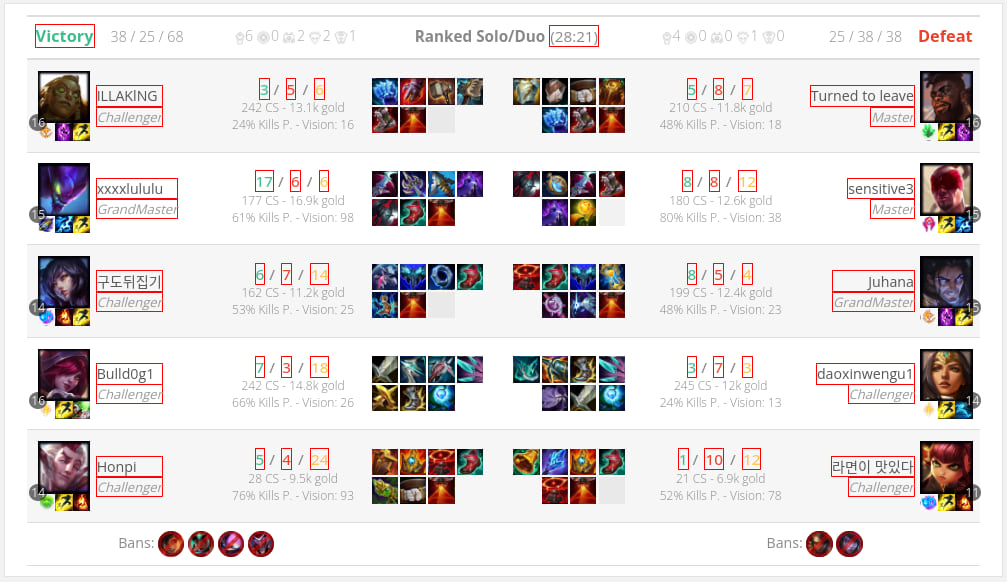
用法
在你的项目的Cargo.toml中
[dependencies]
mlscraper-rust = "0.1.2"
可选地,添加features = ["serde"]以启用(反)序列化TrainingResult使用serde。
依赖关系
~1–1.3MB
~24K SLoC