6 个版本 (破坏性更新)
| 0.4.1 | 2024 年 1 月 8 日 |
|---|---|
| 0.4.0 | 2024 年 1 月 7 日 |
| 0.3.0 | 2024 年 1 月 5 日 |
| 0.2.0 | 2024 年 1 月 1 日 |
| 0.0.0 | 2023 年 12 月 26 日 |
#1489 in 解析器实现
每月 78 次下载
47KB
1K SLoC
mdsplode
![]()
![]()
![]()
![]()
![]()
一个用于解析 Markdown 文件(元数据、AST、渲染部分和完整渲染)的命令行工具
关于
该工具是由于一些 LFE 项目中迫切需要更细粒度地处理 Markdown 文件以发布项目而出现的。
依赖项
该项目是用 Rust 编写的,并依赖于该工具链以及常规的 gcc 工具链。此外,还需要 jq 和 oniguruma 的库文件。有关如何安装这些文件的说明,请参阅 支持 jq 查询。
Shell
mdsplode 的主要用途是作为另一个长时间运行进程的管理,该进程写入 mdsplode 的 stdin 并从其 stdout 读取。这通过交互式 shell 完成。
在 CLI 上使用该命令启动 shell
cargo install mdsplode
mdsplode shell
或从本仓库的克隆版中启动
cd mdsplode
make build
./bin/mdsplode shell
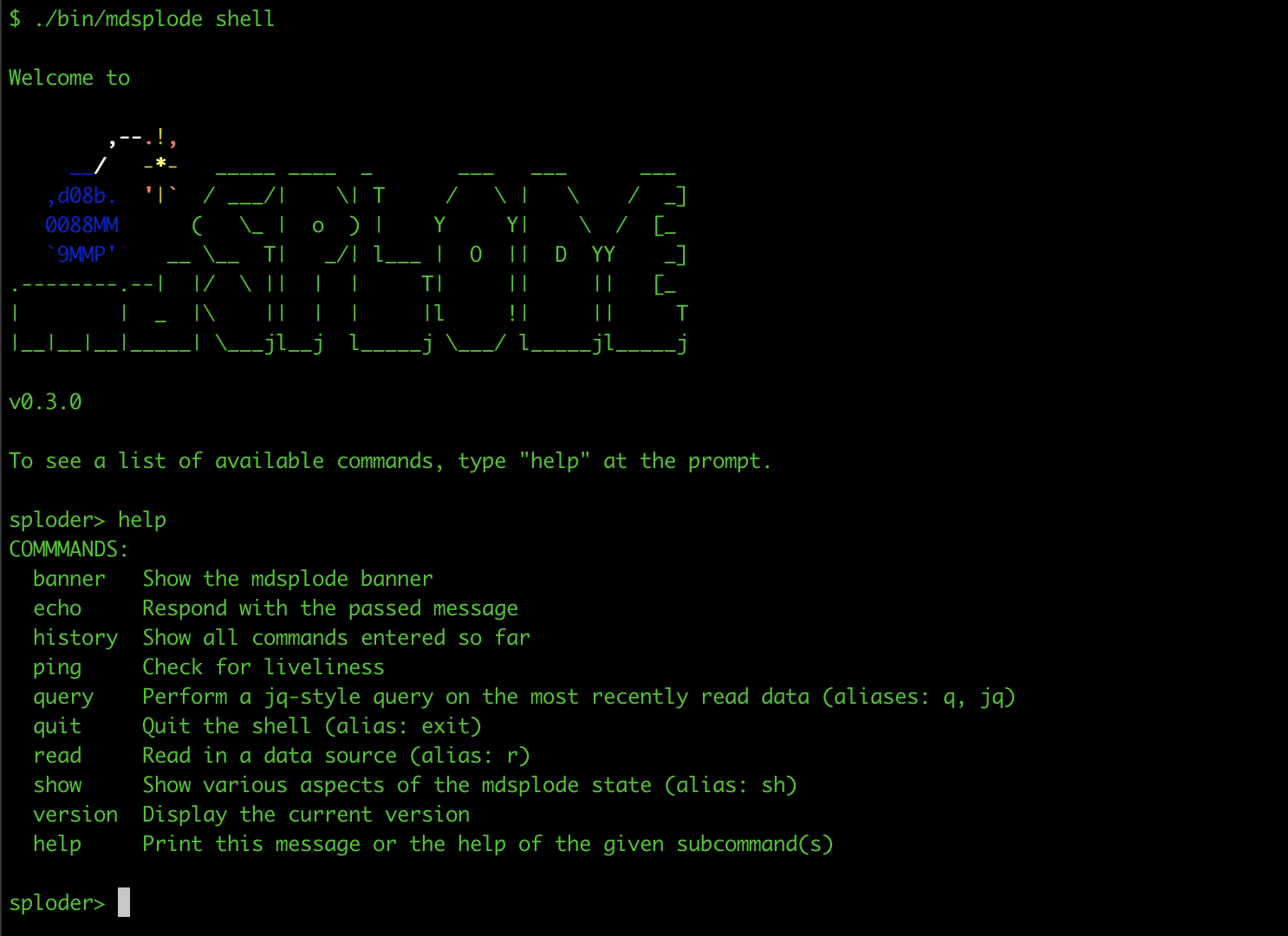
快速会话
sploder> read md "tests/data/learn.md"
Loaded "tests/data/learn.md"
sploder> show in-file
tests/data/learn.md
sploder> show source
... # Markdown data
sploder> show parsed
... # JSON data
sploder> read json "tests/data/parsed.json"
Loaded "tests/data/parsed.json"
sploder> query '.children.nodes[] | select(.depth == 3) | .source'
"Sub Heading 1"
"Sub Heading 2"
sploder> query --pretty '.children.nodes[] | select(.source == "Sub Heading 1")'
{
"children": {
"html": "<p>Sub Heading 1</p>",
"json": "",
"nodes": [
{
"children": {
"html": "",
"json": "",
"nodes": []
},
"depth": -1,
"html": "<p>Sub Heading 1</p>",
"name": "text",
"source": "Sub Heading 1"
}
]
},
"depth": 3,
"name": "heading",
"source": "Sub Heading 1"
}
sploder> read md "tests/data/learn.md"
Loaded "tests/data/learn.md"
sploder> show fm
{
"frontmatter": {
"extra": {
"long_description": "Learning LFE must be taken in three tracks: learning the syntax particular to a Lisp on the Erlang VM, with all its support for pattern matching, Erlang-style arities, etc.; learning the ins-and-outs of BEAM languages and OTP; and finally, more deeply exploring the Lisp heritage of LFE. This multi-pronged approach is the path to success.",
"long_title": "Resources for Learning LFE"
},
"in_search_index": true,
"title": "Learn"
}
}
sploder> quit
Quitting ...
CLI 使用
查看所有解析后的解析数据
./bin/mdsplode \
--input ./tests/data/learn.md \
--pretty
查看过滤后的子集,例如,特定 Markdown 标题的解析元数据
./bin/mdsplode \
--input ./tests/data/learn.md \
--pretty \
--query '.children.nodes[] | select(((.depth == 3) and .name == "heading") and .source == "Getting Started")'
重要!:当使用 --pretty 时,只能使用产生有效 JSON 的 jq 查询;否则将导致 JSON 解析错误(因为使用 --pretty 需要重新解析为 JSON 以进行查询结果的后处理)。
获取深度为 3 的所有标题的 HTML
./bin/mdsplode \
--input ./tests/data/learn.md \
--query '.children.nodes[] | select((.depth == 3) and .name == "heading") | .children.nodes[].html'
该命令不会生成有效的 JSON,因此没有使用 --pretty(以避免错误,因为它根本不适用)。
查询以提取前缀
./bin/mdsplode \
--input ./tests/data/learn.md \
--query '.children.nodes[] | select(.name == "toml") | .json'
由于该字段是序列化的 JSON,我们可以将其作为原始字符串管道到 jq,然后再解析为 JSON 并格式化打印
echo `!!` | jq -r . | jq .frontmatter
{
"in_search_index": true,
"title": "Learn",
"extra": {
"long_description": "Learning LFE must be taken in three tracks: learning the syntax particular to a Lisp on the Erlang VM, with all its support for pattern matching, Erlang-style arities, etc.; learning the ins-and-outs of BEAM languages and OTP; and finally, more deeply exploring the Lisp heritage of LFE. This multi-pronged approach is the path to success.",
"long_title": "Resources for Learning LFE"
}
}
请注意,mdsplode 还支持操作目录(一次处理多个文件)。
许可
版权所有 © 2023-2024,Oxur Group
Apache 许可证,版本 2.0
依赖项
~10–20MB
~270K SLoC