4 个稳定版本
| 2.0.0 | 2023 年 4 月 12 日 |
|---|---|
| 1.1.1 | 2023 年 2 月 10 日 |
| 1.1.0 | 2023 年 2 月 4 日 |
| 1.0.0 | 2023 年 1 月 27 日 |
#542 in 文本处理
37 次每月下载
1MB
2.5K SLoC
litua
- 作者
- tajpulo
- 版本
- 2.0.0
- 徽章


读取文本文档,以 Lua 语言接收其树状结构,并在表示为字符串之前对其进行操作。
这是什么?
输入
文本文档出现在许多环境中。实际上,我们喜欢它们作为记录想法和概念的简单方式。它们帮助我们进行沟通。但有时,我们希望将其转换为其他文本格式或处理其内容。litua 以特别的方式帮助解决这个问题。
您可以编写如下文本文档
In olden times when wishing still helped one, there lived a king whose daughters were all beautiful; and the youngest was so beautiful that the sun itself, which has seen so much, was astonished whenever it shone in her face.
但这段文本很无聊。您通常关心标记。标记是一些特殊的指令,用于注释文本
In olden times when wishing still helped one, there lived a {bold king} whose daughters were all {italic beautiful}; and the youngest was so beautiful that the sun itself, which has seen so much, was astonished whenever it shone in her face.
在这种情况下,文本 {加粗 X} 和 {斜体 Y} 有一些特殊含义。例如,它可能意味着文本以特殊样式表示(例如,X 以粗体字体表示,Y 以草书表示)。通常,我们以下列方式定义 litua 输入语法
{element[attr1=value1][attribute2=val2] text content of element}
- element 是标记元素的名称。其名称表示其语义。在 litua 的术语中,我们可以自行定义语义。
- attr1 和 attr2 是该标记元素的属性。它提供了有关标记元素的更多细节。例如,它可以指定用于表示这些标记元素的字体。本质上,我们有一个与值 value1 相关的属性 attr1。我们还有一个与 val2 相关的属性 attr2。
- content 是受该标记影响的文本。
最后,我要告诉你一个秘密:value1、val2 以及 元素的文本内容 不一定是文本,也可以是元素本身。因此,以下在 litua 输入语法 中是允许的
{bold[font-face=Bullshit Sans] {italic Blockchain managed information density}}
在这个意义上,litua 输入语法与 XML(例如:<element attr1="value1" attribute2="val2">text content of <element>/element>)、LISP(例如:(element :attr1 "value1" :attribute2 "val2" "text content of element"))以及标记语言在一般上非常相似。顺便说一句,如果您在文档中确实需要 { 或 },您可以通过写作 {left-}-brace 或 {right-}-brace 分别来逃避这些语义。litua 输入语法文件必须始终以 UTF-8 编码。
处理文档
让我们将元素示例放入 litua 输入语法 的文本文档中(doc.lit)。然后我们可以调用 litua
bash$ litua doc.lit
输出文件扩展名为 out:doc.out。它非常无聊:它正好是输入
bash$ cat doc.out
{element[attr1=value1][attribute2=val2] text content of element}
如果告诉你这个元素在 Lua 中的表示,那就更有趣了
local node = {
-- the string giving the node type
["call"] = "element",
-- the key-value pairs of arguments.
-- values are sequences of strings or nodes
["args"] = { ["attr1"] = { [1] = "value1" }, ["attribute2"] = { [1] = "val2" } },
-- the sequence of elements occuring in the body of a node.
-- the items of content can be strings or nodes themselves
["content"] = {
[1] = "text content of element"
},
}
例如,node.call 允许您访问标记元素的名称。 node.content[1] 允许您访问 element 在 Lua 中的第一个且唯一的内容成员的字符串。记住,在 Lua 中,集合类型中的第一个元素存储在索引 1 中(而不是大多数编程语言中的 0)。
现在在同一个目录中创建一个 Lua 文件 hooks.lua(文件名必须以 hooks 开头,并以 .lua 结尾)并包含以下内容
Litua.convert_node_to_string("element", function (node)
return "The " .. tostring(node.call) .. " said: " .. tostring(node.content[1])
end)
现在让我们再次调用 litua
bash$ litua doc.lit
[…]
bash$ cat doc.out
The element said: text content of element
哇,我们刚刚修改了处理文档的行为 😍
钩子
实际上,我们使用了一个名为 钩子 的概念来修改行为。我们通过 convert_node_to_string 注册钩子,以便在 litua 尝试将节点转换为字符串时触发钩子。钩子是一个 Lua 函数。让我们阅读 Lua 语法
Litua.convert_node_to_string("element", function (node)
return "The " .. tostring(node.call) .. " said: " .. tostring(node.content[1])
end)
Litua.convert_node_to_string是一个函数,由 litua 在您运行litua时定义。- 第一个参数必须是一个字符串,即
"element",它告诉 litua 何时 调用第二个参数。 - 第二个参数以关键字
function开始,以关键字end结束。这是钩子。它是一个函数,接受一个名为node的参数。它可以运行任意代码,并且特别地,它最终返回一个字符串,该字符串由node变量的数据构建而成。..是Lua中的字符串连接运算符,而tostring是一个内置的Lua函数,它将任何值转换为字符串对象。
完整的钩子集合在此给出
_litua.on_setup
目的:注册一个在初始时运行的钩子,并可选择初始化_litua.global变量,以满足您的需求
默认行为:不执行任何操作
钩子:该钩子不接受任何参数,并返回nil_litua.modify_initial_string
目的:注册一个在on_setup之后运行的钩子,并可选择预处理文本文档的源代码
默认行为:返回原始源代码
钩子:该钩子接受源代码作为字符串、源文件路径作为字符串,并返回更新后的源代码作为字符串_litua.read_new_node
目的:注册一个在将文档转换为元素层次结构之后运行的钩子。它允许您在修改之前查看某些节点
默认行为:不执行任何操作
钩子:该钩子接受当前节点的副本、树深度作为整数,并返回nil_litua.modify_node
目的:注册一个在read_new_node之后运行的钩子,并允许您实际修改一个节点
默认行为:返回原始节点
钩子:该钩子接受当前节点、树深度作为整数以及过滤器名称,并返回(某个节点或字符串)和nil_litua.read_modified_node
目的:注册一个在modify_node之后运行的钩子。它允许您在修改之后查看某些节点
默认行为:不执行任何操作
钩子:该钩子接受当前节点的副本、树深度作为整数,并返回nil_litua.convert_node_to_string
目的:注册一个定义如何将节点表示为字符串的钩子
默认行为:返回其在_litua输入语法中的原始字符串表示形式
钩子:该钩子接受当前节点、树深度作为整数以及过滤器名称,并返回一个字符串和nil_litua.modify_final_string
目的:在将层次结构转换为字符串后注册一个钩子,并可选择后处理文本文档的源代码
默认行为:返回提供的字符串表示形式
钩子:该钩子接受字符串表示形式作为字符串,并返回一个字符串_litua.on_teardown
目的:注册一个最终运行的钩子,并可选择在_litua.global中销毁变量,以满足您的需求
默认行为:不执行任何操作
钩子:该钩子不接受任何参数,并返回nil
请注意,文档始终位于一个名为document的无形顶级节点中。因此,如果您在输入文件中使用document元素并为此元素定义一个钩子,不要对额外的钩子调用感到惊讶。
示例
强烈建议按照此顺序查看示例,以了解如何使用钩子
- 枚举 – 用递增计数器替换调用
- 替换 – 首先定义替换对,然后应用它们
- literate-programming – 定义文档和代码块,并将它们写入不同的文件
- markup – 将树序列化为HTML5
为什么我应该使用它?
Litua是一个简单的文本处理工具,用于处理具有层次结构的文本文档。它让人联想到XSLT之类的工具,但人们常常抱怨XSLT对常用编程语言的陌生感。作为一个替代方案,我为litua提供了一个litua输入语法的解析器、rust到Lua的数据映射、Lua运行时和文本文件写入器。
如何安装
这是一个单静态可执行文件。它只依赖于基本系统库,如pthread、math和libc。它将整个Lua 5.4解释器与可执行文件一起打包。我期望它能在您的操作系统上直接运行。
如何运行
使用 -h 调用litua可执行文件以获取有关其他参数的信息
litua -h
Litua输入规范
以下文档定义了语法(另见 design/litua-lexer-state-diagram.jpg)
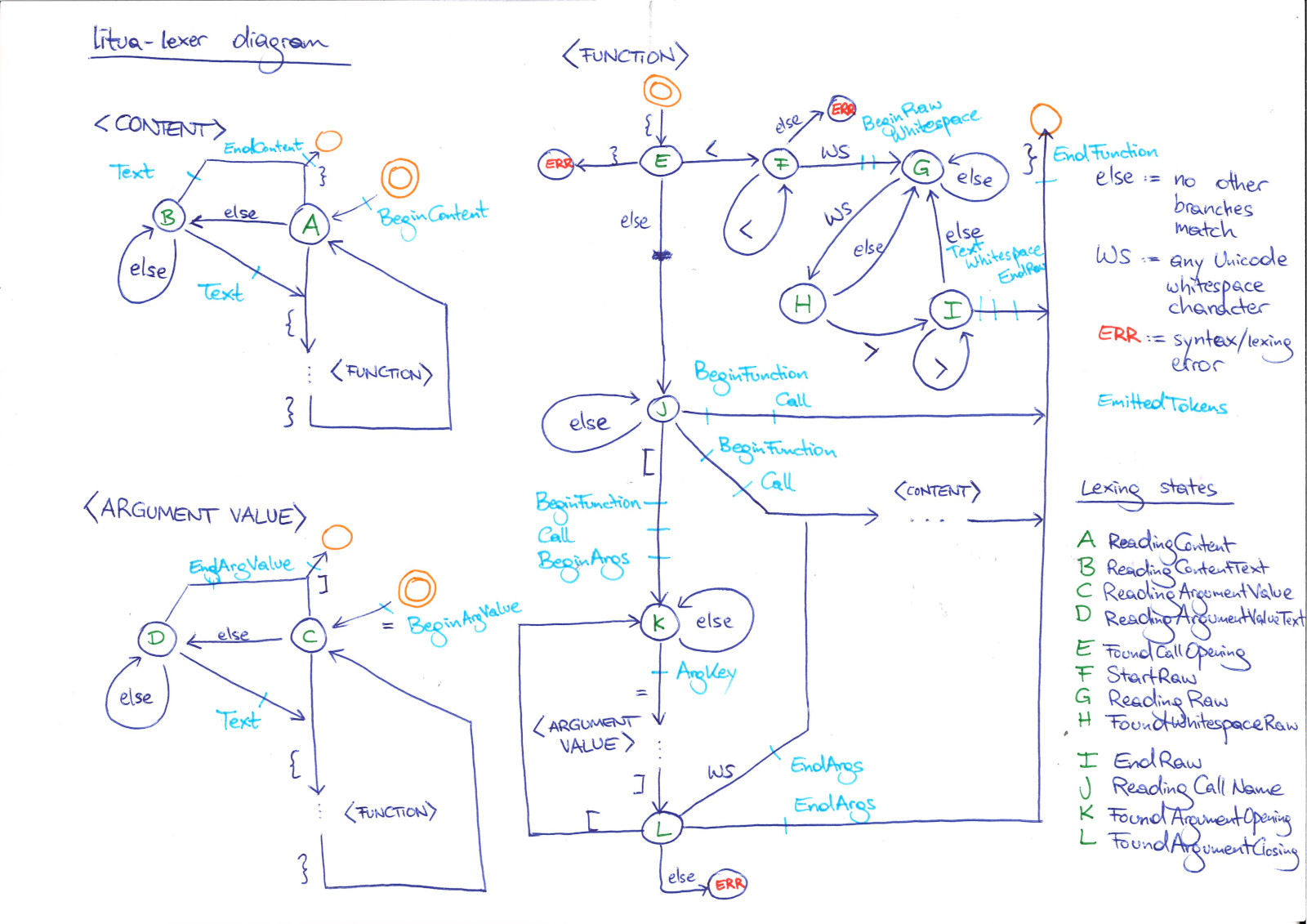{kind=link}
Node = (Text | RawString | Function){0,…}
Text = (NOT the symbols "{" or "}"){1,…}
RawString = "{<" Whitespace (NOT the string Whitespace-and-">}") Whitespace ">}"
| "{<<" Whitespace (NOT the string Whitespace-and-">>}") Whitespace ">>}"
| "{<<<" Whitespace (NOT the string Whitespace-and-">>>}") Whitespace ">>>}"
… continue up to 126 "<" characters
Function = "{" Call "}"
| "{" Call Whitespace "}"
| "{" Call Whitespace Node "}"
| "{" Call ( "[" Key "=" Node "]" ){1,…} "}"
| "{" Call ( "[" Key "=" Node "]" ){1,…} Whitespace "}"
| "{" Call ( "[" Key "=" Node "]" ){1,…} Whitespace Node "}"
Call = (NOT the symbols "}", "[" or "<")(NOT the symbols "[" or "<"){0,…}
Key = (NOT the symbol "="){1,…}
Whitespace = any of the 25 Unicode Whitespace characters
实质上,在函数调用名称中不要使用 "<" 或 "[",或在使用键时使用 "="。保持开闭括号的数量平衡(尽管这不是由语法强制执行的)。
改进
以下部分可以改进:
- 因为rust的HashMap表示在构建之间不一致,所以测试套件中没有检查
.parsed.expected文件。 - 验证用户代码的错误处理是否良好
- 改进了语法错误的错误报告(标记位置等)
源代码
源代码可在Github上找到。
许可协议
请参阅许可文件(提示:MIT许可)。
变更日志
- 0.9
- 第一个公开版本,包含原始字符串和四个示例
- 1.0.0
- 改进了stdout/stderr,改进了文档,CI构建,上传到crates.io
- 1.1.0
- 修复了modify-node hook的第三个参数,modify-hook现在也可以返回字符串
- 1.1.1
- 修复:原始字符串内容中的中断的 '>' 序列现在可以再次使用,从测试套件中删除了hook检查
- 2.0
- 改进了文档,在原始字符串中在 ">" 前需要空格
问题
请在Github问题页面上报告任何问题。
依赖关系
~2.6–5MB
~87K SLoC