5 个不稳定版本
| 0.3.1 | 2020 年 8 月 29 日 |
|---|---|
| 0.3.0 | 2020 年 6 月 20 日 |
| 0.2.1 | 2020 年 6 月 19 日 |
| 0.2.0 | 2020 年 6 月 15 日 |
| 0.1.0 | 2020 年 6 月 15 日 |
#472 in 文本处理
47,203 每月下载量
用于 80 个 crate (15 直接)
64KB
610 行
lexical-sort
这是一个用于比较和按字典顺序排序字符串(或文件路径)的库。这意味着非 ASCII 字符,如 á 或 ß,被当作它们最近的 ASCII 字符对待:á 被当作 a,ß 被当作 ss,等等。
字典比较不区分大小写。字母数字字符在所有其他字符(标点符号、空白、特殊字符、表情符号等)之后排序。
可以启用 自然排序,它还处理 ASCII 数字。例如,在启用自然排序的情况下,50 小于 100。还可以跳过非字母数字字符,例如,f-5 排在 f5 旁边。
如果不同的字符串具有相同的 ASCII 表示(例如,"Foo" 和 "fóò"),则回退到标准库中的默认方法,因此排序是确定的。
| 注意:此 crate 不试图为每个地区都正确无误,但它应该适用于广泛的地区,同时提供出色的性能。 |
用法
要排序字符串或路径,可以使用 StringSort 或 StringSort trait
use lexical_sort::{StringSort, natural_lexical_cmp};
let mut strings = vec!["ß", "é", "100", "hello", "world", "50", ".", "B!"];
strings.string_sort_unstable(natural_lexical_cmp);
assert_eq!(&strings, &[".", "50", "100", "B!", "é", "hello", "ß", "world"]);
有八个比较函数
| 函数 | lexicographical | natural | 跳过非字母数字字符 |
|---|---|---|---|
cmp |
|||
only_alnum_cmp |
yes | ||
lexical_cmp |
yes | ||
lexical_only_alnum_cmp |
yes | yes | |
natural_cmp |
yes | ||
natural_only_alnum_cmp |
yes | yes | |
natural_lexical_cmp |
yes | yes | |
natural_lexical_only_alnum_cmp |
yes | yes | yes |
注意,只有按字典顺序排序的函数才不区分大小写。
特性
所有比较函数构成一个 全序。只有当两个字符串由完全相同的 Unicode 代码点组成时,它们才被认为是相等的。
性能
该算法使用迭代器,从不分配堆内存。它针对主要由 ASCII 字符组成的字符串进行了优化;对于仅包含 ASCII 字符的字符串,字典比较函数的速度仅比 std 中的默认方法慢 2 到 3 倍,后者仅比较 Unicode 代码点。
请注意,对于在转换为小写ASCII后,开头许多字符相同的字符串,比较速度较慢。
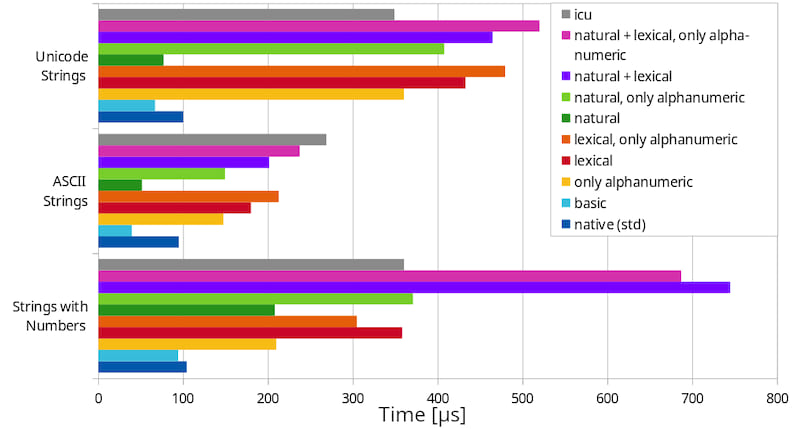
基准测试
这些基准测试是在搭载4个3.1GHz的AMD A8-7600 Radeon R7 CPU上执行的。
- 第一个基准测试比较了100个随机生成的5到20个字符的字符串,包含ASCII和非ASCII字符。
- 第二个基准测试也比较了100个随机生成的5到20个字符的字符串,但它们是纯ASCII字符。
- 最后一个基准测试比较了100个随机生成的字符串,每个字符串由
"T-"后跟1到8位十进制数字组成。这是对自然排序的压测。
第一个、灰色条形来自提供对icu C库绑定的rust_icu crate。它为英语执行“正确”的排序。在许多情况下,它更快,因为它在事先生成搜索键以减少总工作量。
最后一个、深蓝色条形是标准库中的字符串比较函数。
no_std 支持
此crate支持no_std环境。请注意,您必须禁用默认功能才能在没有标准库的情况下编译。
此crate目前不需要分配器,尽管这可能会在未来改变。
贡献
欢迎贡献、错误报告和功能请求!
如果缺少对某些字符的支持,您可以将其贡献给any_ascii crate。
许可证
本项目双授权于MIT和Apache 2.0许可证。使用您喜欢的任意一个。
依赖
~240KB