7 个版本
| 0.0.5 | 2024 年 5 月 24 日 |
|---|---|
| 0.0.5-rc2 | 2023 年 10 月 4 日 |
| 0.0.5-rc1 | 2023 年 5 月 7 日 |
| 0.0.4 | 2022 年 12 月 28 日 |
| 0.0.2 | 2022 年 9 月 23 日 |
#248 in Web 编程
每月下载 66 次
300KB
5.5K SLoC
![]()
![]()
![]()
![]()
由分段、分区、复制和不可变日志驱动的可扩展、分布式消息队列。
此项目目前正在进行中。
用法
laminarmq 提供了一个库 crate 和两个二进制文件,用于管理 laminarmq 部署。要将 laminarmq 作为库使用,请将以下内容添加到您的 Cargo.toml
[dependencies]
laminarmq = "0.0.5"
有关详细信息,请参阅最新的 git API 文档 或 Crate 文档。还有一个 书籍 正在被编写,以进一步描述设计决策、实现细节和配方。
laminarmq 在一个简单的提交日志抽象(按索引顺序排列的一系列记录)之上提供了一个,可以在此之上实现多个消息队列语义,例如发布/订阅,甚至完整的协议,如 MQTT。用户可以自由地以任何需要的顺序读取带有偏移的消息。
laminarmq 的主要里程碑
示例
在 示例 目录中找到展示 laminarmq 不同功能的示例。
媒体
与 laminarmq 项目相关的媒体。
[BLOG]在 Rust 中构建分段日志:从理论到生产!
设计
本节描述了 laminarmq 的内部设计。
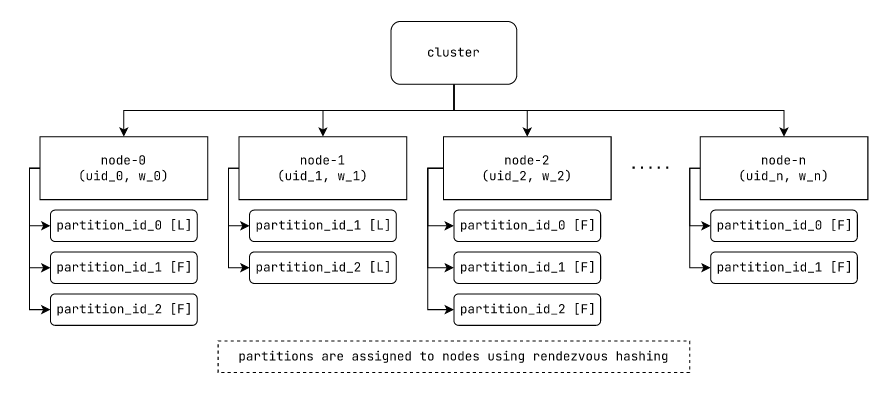
集群层次结构
partition_id_x is of the form (topic_id, partition_idx)
In this example, consider:
partition_id_0 = (topic_id_0, partition_idx_0)
partition_id_1 = (topic_id_0, partition_idx_1)
partition_id_2 = (topic_id_1, partition_idx_0)
精确的数字ID与partition_id和topic_id之间没有任何模式;可以有多个主题,每个主题可以有多个分区(通过partition_idx标识)。
… 或者
[cluster]
├── node#001
│ ├── (topic#001, partition#001) [L]
│ │ └── segmented_log{[segment#001, segment#002, ...]}
│ ├── (topic#001, partition#002) [L]
│ │ └── segmented_log{[segment#001, segment#002, ...]}
│ └── (topic#002, partition#001) [F]
│ └── segmented_log{[segment#001, segment#002, ...]}
├── node#002
│ ├── (topic#001, partition#002) [F]
│ │ └── segmented_log{[segment#001, segment#002, ...]}
│ └── (topic#002, partition#001) [L]
│ └── segmented_log{[segment#001, segment#002, ...]}
└── ...other nodes
[L] := leader; [F] := follower
图: laminarmq集群层次结构,展示分区和复制。
“主题”是一组记录的集合。主题被划分为多个“分区”。每个分区随后在多个“节点”上进一步复制。一个“节点”可能包含某个或所有“主题”的分区。这样,主题在集群的节点上既被分区也被复制。
在“主题”级别没有消息的顺序。然而,一个“分区”是一组按记录索引排序的有序记录。
虽然我们在概念上维护分区和主题的层次结构,但在集群级别,我们选择维护主题分区的平面表示。我们在分区级别提供了一个基本的提交日志API。
用户可以执行以下操作
- 在分区级别直接与我们消息队列交互
- 在主题分区之间使用客户端负载均衡
这减轻了在分区之间负载均衡消息和消息流所有权记录的集群负担。可以根据需要构建基于分区提交日志API的高级结构。
每个分区副本组有一个领导者,写入数据到那里,以及一组跟随者,它们跟随领导者并且可以被读取。用户可以使用客户端负载均衡来平衡对领导者及其所有跟随者的读取。
每个分区副本由一个分段日志用于存储。
服务发现和分区分配到节点
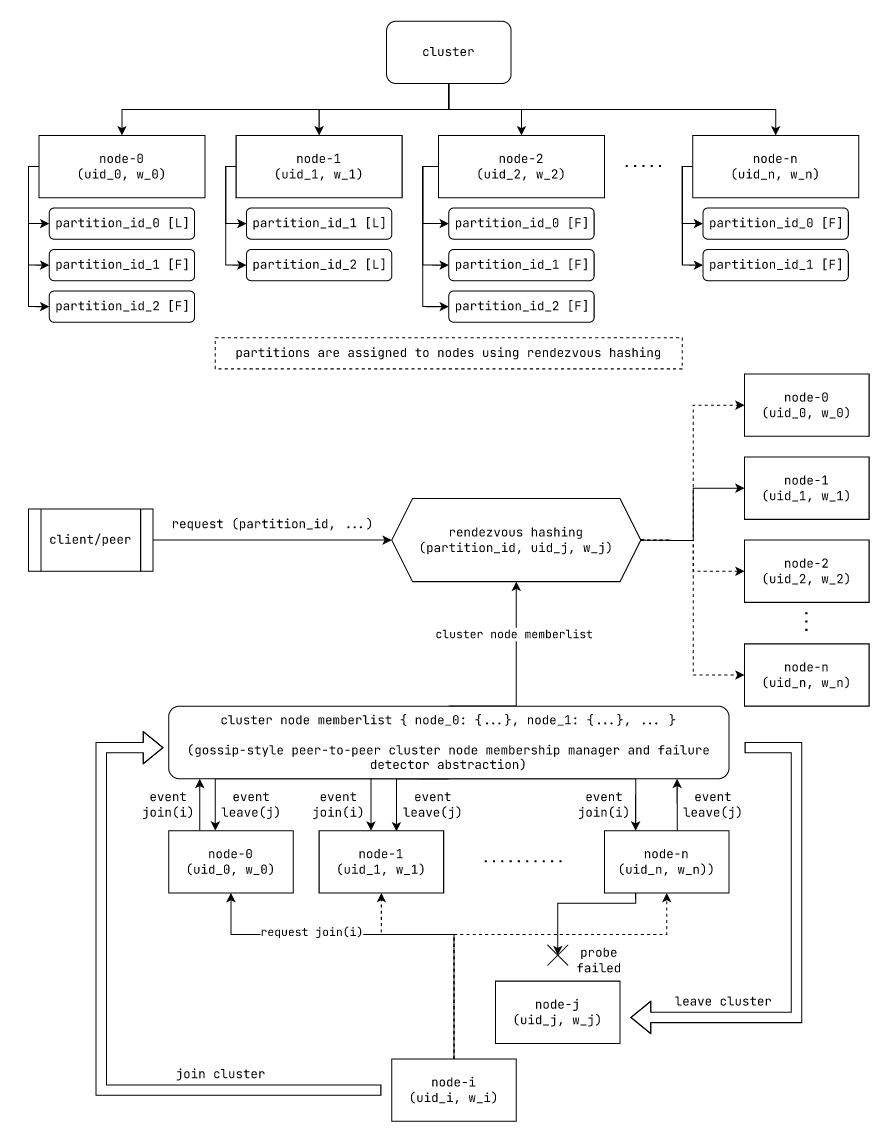
图: laminarmq使用的基于 rendezvous散列的分区分配和基于八卦风格的发现机制
在我们的集群中,节点使用八卦风格的点对点机制相互发现。其中一种机制是SWIM(可伸缩弱一致性感染式进程组成员资格)。
在此机制中,每个成员节点通过八卦风格的信息传播机制通知组内其他成员一个节点是否加入或离开集群(一个节点向相邻节点八卦,它们再向其邻居八卦,依此类推)。
为了检测节点是否已失败,节点随机探测集群中的单个节点。例如,节点A直接探测节点B。如果节点B响应,则它没有失败。如果节点B没有响应,A尝试通过集群中的其他节点间接探测节点B,例如,节点A可能会要求节点C探测节点B。节点A继续使用集群中的所有其他节点间接探测节点B。如果节点B对任何间接探测做出响应,则它仍被视为未失败。否则,它被视为已失败并从集群中移除。
有机制可以减少由于暂时中断引起的错误失败。论文详细介绍了这些机制。
这也是Hashicorp Serf的核心技术,其中对失败检测和收敛速度进行了进一步改进。
使用此机制,我们可以获得集群中所有成员的列表,包括它们的唯一ID和容量权重。然后我们使用它们的ID和权重来确定放置分区的地方,使用rendezvous散列。
来自维基百科文章
Rendezvous或最高随机权重(HRW)散列是一种算法,允许客户端在可能的n个选项中就k个选项达成分布式一致。一个典型的应用场景是当客户端需要就对象分配给哪个站点(或代理)达成一致时。
在我们的情况下,我们使用会合哈希来确定放置分区副本的节点子集。
对于某些哈希函数 H,某些权重函数 f(w, hash) 和分区 ID P_x,我们按照以下步骤进行:
- 对于集群中具有权重
w_i的每个节点N_i,我们计算R_i = f(w_i, H(concat(P_x, N_i))) - 我们根据节点排名值
R_i对属于节点集N的所有节点N_i进行排名。 - 对于某个复制因子
k,我们选择排名前k的节点来放置分区 IDP_x的k个副本。
(我们假设 k <= |N|;其中 |N| 是节点数,k 是副本数)
通过这种机制,任何拥有集群中所有成员的 ID 和权重的任何人都可以计算分区的副本目标节点。此信息还可以用于在客户端和服务器端路由分区请求到适当的节点。
在我们的情况下,我们使用客户端负载均衡来平衡所有幂等分区请求,这些请求可以在可能包含请求分区副本的任何节点上执行。对于非幂等请求,如果我们将其发送到任何候选节点,它们将重定向到副本集的当前领导者。
支持的执行模型
laminarmq 支持两种执行模型
- 由 Rust 生态系统中的各种异步运行时(例如
tokio)使用的通用异步执行模型 - 每个核心一个线程的执行模型
在“每个核心一个线程”的执行模型中,单个处理器核心仅限于单个线程。此模型鼓励设计最小化线程间竞争和锁定,从而提高软件服务的尾延迟。阅读:“线程每核心架构对应用程序尾延迟的影响”。
在“每个核心一个线程”的执行模型中,我们必须利用应用级分区,以便每个线程负责一组请求和/或责任。我们还必须通过适当的请求路由到线程来补充此模型,以确保请求的局部性。在我们的情况下,这相当于每个线程只负责节点中分区副本的一部分。与分区副本相关的请求始终路由到同一线程。以下部分将更详细地介绍如何实现这一点。
我们认识到,尽管“每个核心一个线程”的执行模型有一些固有的优势,但与现有的 Rust 生态系统兼容将显著提高采用率。因此,我们设计了我们的系统,其中包含可重用的组件,可以组织以适应两种执行模型。
节点中的请求路由
通用设计
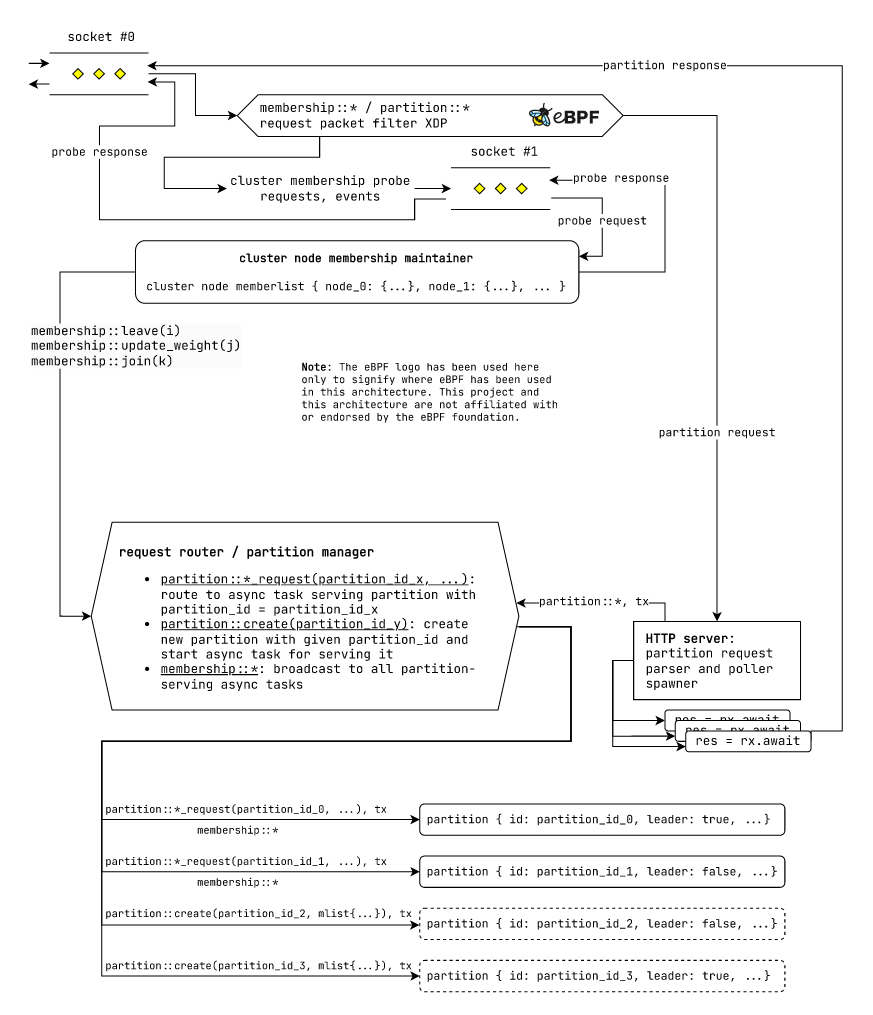
图:使用通用执行模型在 laminarmq 节点中进行请求路由机制。
在我们的集群中,我们有两种类型的请求
- 成员请求:用于通过八卦式服务发现系统维护集群成员资格。
- 分区请求:用于与
laminarmq主题分区交互。
我们使用一个 eBPF XDP 过滤器,将请求数据包在套接字层分类为成员请求数据包和分区请求数据包。接下来,我们使用 eBPF 将成员数据包路由到该节点中成员管理子系统专用的不同套接字。分区请求数据包则保持原样流动。
接下来有一个 "HTTP 服务器",它将来自原始套接字的新到达的分区请求数据包解析为有效的 partition::* 请求。对于每个 partition::* 请求,HTTP 服务器都会为其生成一个未来的处理任务。这个请求处理器未来的操作如下:
- 为请求创建一个新的通道
(tx, rx)。 - 将解析后的分区请求和通道的发送端
(partition::*, tx)一起发送到 "请求路由器" 的接收通道。 - 等待这个未来的通道创建的接收端,以获取响应。
res = rx.await - 当我们从这个未来的通道接收响应时,我们将它序列化并返回给接收数据包的套接字。
接下来有一个 "请求路由器/分区管理器",负责将各种请求路由到分区服务未来的处理任务。请求路由器单元接收来自成员子系统的 membership::* 请求和来自 "HTTP 服务器" 请求处理未来的 partition::* 请求(从现在起也称为请求轮询未来的,因为它们轮询通道接收端 rx 的响应)。请求路由器单元按照以下方式路由请求:
membership::*请求被广播到所有分区服务未来。(partition::*_request(partition_id_x, …), tx)元组使用partition_id路由到目标分区。(partition::create(partition_id_x, …), tx)元组由请求路由器/分区管理器本身处理。为此,请求路由器/分区管理器创建一个新的分区服务未来,分配所需的存储单元,并在tx上发送适当的响应。
最后,各个分区服务器期货在到达我们的节点并路由后,都会收到 membership::* 和 (partition::*, tx) 请求。它们会根据需要处理请求,并在适用的情况下向 tx 发送响应。
每个核心执行模型的线程兼容设计
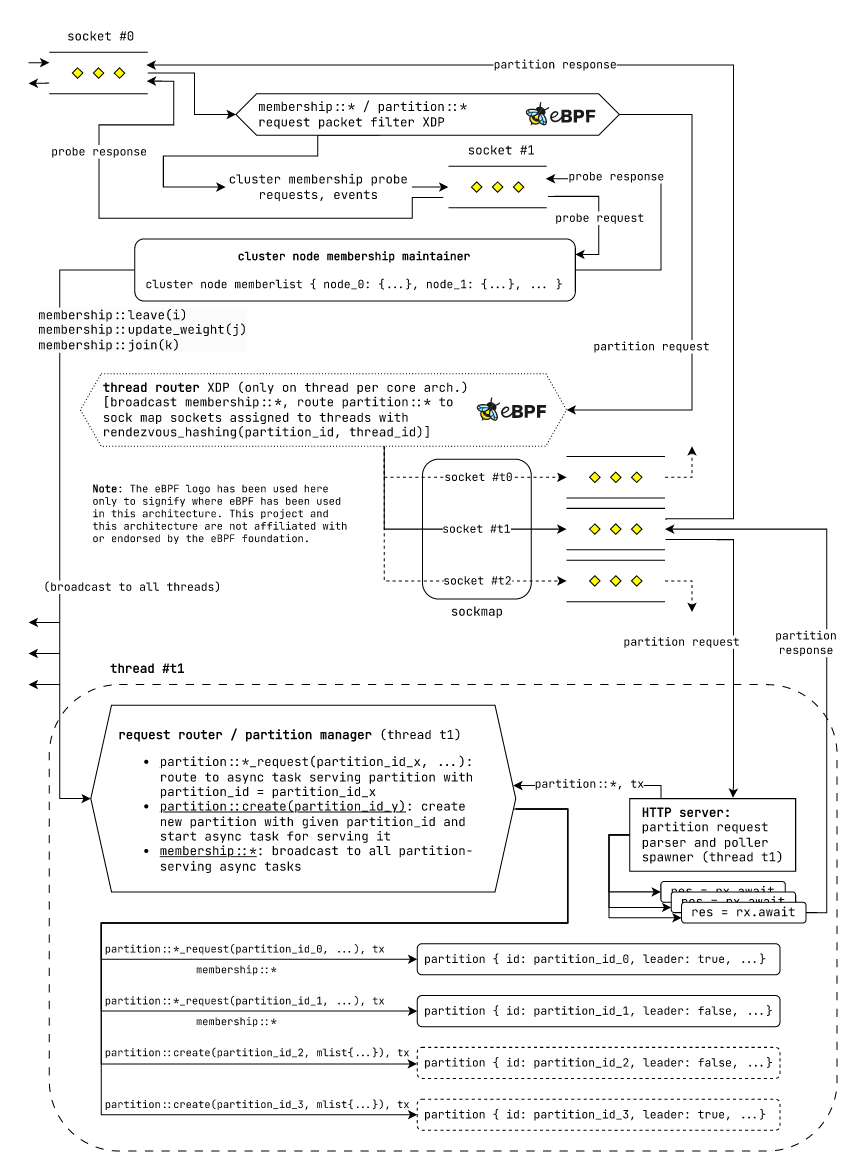
图:使用每个核心执行模型的 laminarmq 节点中的请求路由机制。
在每个核心执行模型中,每个线程负责一组分区。因此,每个线程都有自己的“请求路由器/分区管理器”、“HTTP 服务器”和一组分区服务期货。我们在不同的处理器核心上运行多个这样的线程。
现在,如之前所述,我们需要将单个请求路由到正确的目标线程,以确保请求的局部性。我们使用专门的“线程路由器”eBPF XDP过滤器将分区请求数据包路由到目标线程。
“线程路由器”eBPF XDP过滤器维护一个eBPF sockmap,其中包含每个线程监听请求的套接字。对于每个传入请求,我们使用此 sockmap 将其路由到目标线程。现在我们可以再次利用 rendezvous hashing 来确定用于请求的线程。我们使用 partition_id 和 thread_id 进行 rendezvous hashing。由于所有线程都在不同的处理器核心上运行,它们将具有类似的处理请求能力,因此将具有相等的权重。利用这一点,属于特定分区的请求将始终路由到特定节点上的同一线程。这确保了高程度的请求局部性。
其余组件的行为如前所述。注意我们如何能够重复使用相同的组件在截然不同的执行模型中,正如之前承诺的那样。
分区控制流和复制
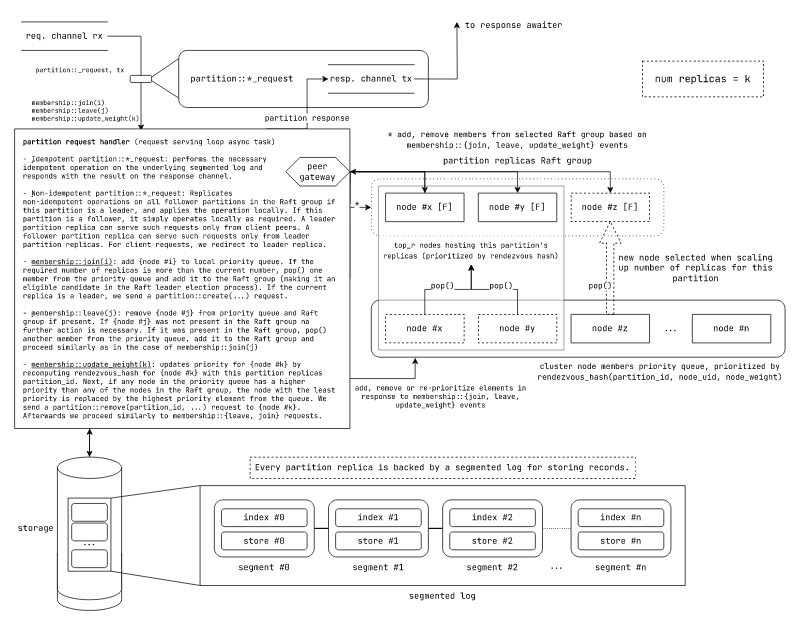
图:在 laminarmq 中的分区服务期货控制流和分区复制机制。
分区控制器期货从请求路由器期货接收成员事件请求 membership::{join, leave, update_weight} 或 (partition::*, tx) 请求。
分区请求处理器按以下方式处理不同请求:
-
幂等
partition::*_request:在底层数据段上进行必要的幂等操作,并通过响应通道返回结果。 -
非幂等
partition::*_request:主副本和从副本对非幂等副本的处理不同- 主副本:如果此分区是主副本,则在 Raft 组中的所有从副本上复制非幂等操作,然后本地应用操作。这可能涉及首先发送 Raft 追加请求,在大多数副本响应后本地写入,然后本地提交,最后将提交传递给所有其他副本。主副本只对客户端请求做出响应。忽略来自从副本的非幂等请求。
- 从副本:从副本只对领导者的非幂等请求做出响应。从客户端来的非幂等请求被重定向到领导者。从副本通过根据 Raft 本地应用更改来处理非幂等请求。
一旦副本完成请求处理,如果存在,它们将适当响应发送回响应通道。(重定向响应也会正确编码并发送回响应通道)。
-
membership::join(i):将节点 #i 添加到本地优先队列。如果所需的副本数量超过当前数量,则从优先队列中弹出一个成员并将其添加到 Raft 组(使其成为 Raft 领导选举过程的候选者)。如果当前副本是领导者,我们发送一个partition::create(...)请求。如果没有副本是领导者,我们将每个副本初始化为候选者,开始领导选举过程。 -
membership::leave(j):如果存在,则从优先队列和 Raft 组中删除节点 #j。如果{node #j}不在 Raft 组中,则无需进一步操作。如果它在 Raft 组中,则从优先队列中弹出一个成员,将其添加到 Raft 组,并按照membership::join(j)的情况进行操作。 -
membership::update_weight(k):通过使用 rendezvous_hash 重新计算节点 #k 的优先级,更新节点{node #k}的优先级。接下来,如果优先队列中任何节点的优先级高于 Raft 组中任何节点,则将优先级最低的节点替换为队列中优先级最高的元素。我们向{node #k}发送一个partition::remove(partition_id, ...)请求。之后,我们按照membership::{leave, join}请求的方式继续操作。
当一个节点宕机时,将适当的 membership::leave(i) 消息(其中 i 是宕机的节点)发送到集群中的所有节点。每个节点上的分区副本控制器相应地处理成员请求。实际上
- 对于该节点中的每个领导者分区
- 如果它的 Raft 组中没有其他节点的跟随者副本,则该分区会宕机。
- 如果其他节点中有跟随者副本,它们之间将进行领导选举,一旦选出领导者,该分区的读取和写入操作将正常进行。
- 对于该节点中的每个跟随者分区
- 同一 Raft 组中剩余的副本将继续根据 Raft 的机制运行。
对于节点上每个宕机的分区副本,使用 rendezvous hash 优先级选择新的主机节点。
在我们的系统中,我们为不同的数据存储桶(副本组)使用不同的Raft组。CockroachDB 和 Tikv 将这种方式称为在同一个节点上为不同的数据存储桶使用不同的Raft组为MultiRaft。
更多信息请在此处查看
每个分区控制器都由一个 segmented_log 用于持久化记录。
持久化机制
segmented_log:用于在分区中存储记录的持久化数据结构
用于存储的分割日志数据结构最初在Apache Kafka 论文中进行了描述。

图:在 *nix 文件系统上持久化 segmented_log 数据结构的组织方式。
分割日志是一系列读取段和一个单独的写入段的集合。每个“段”在磁盘上由一个称为“存储”的存储文件支持。
日志是
- “不可变的”,因为只允许“追加”、“读取”和“截断”操作。无法从日志中间更新或删除记录。
- “分割的”,因为它由段组成,每个段处理特定偏移量范围的记录。
所有写入都进入写入段。新记录在写入段的 offset = write_segment.next_offset 处写入。当我们用尽写入段容量时,我们关闭写入段并重新打开它作为读取段。重新打开的段被添加到读取段列表中。然后,创建一个新的写入段,其 base_offset 等于上一个写入段的 next_offset。
当从特定的偏移量读取时,我们线性检查哪个段包含给定的读取段。如果找到能够处理给定偏移量读取的段,我们就从这个段中读取。如果没有在读取段中找到这样的段,我们默认使用写入段。在这种情况下,从写入段读取时可能发生以下情况
- 写入段已同步包括给定偏移量消息在内的消息。在这种情况下,记录成功读取并返回。
- 写入段尚未同步给定偏移量的数据。在这种情况下,读取失败,并出现段I/O错误。
- 如果偏移量超出甚至写入段的范围,我们返回“范围超出”错误。
laminarmq 对 segmented_log 数据结构的特定增强
尽管传统的 segmented_log 数据结构对于 commit_log 实现来说性能相当高,但它仍然需要以下属性对于要追加的记录是真实的
- 我们在内存中具有整个记录
- 在记录追加之前,我们知道记录字节的长度和记录字节的校验和
在从异步字节数据流中读取记录字节时无法知道这些信息。如果没有增强,我们必须将中间字节数据缓冲区连接到向量中。这不仅会导致更多分配,还会降低我们的系统性能。
因此,为了适应这种情况,我们在设计中引入了一个中间索引层。
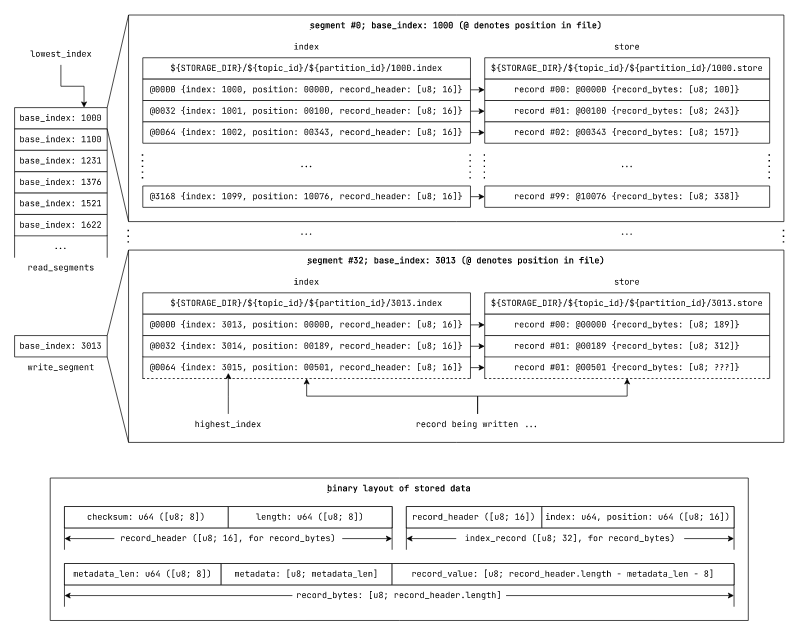
//! Index and position invariants across segmented_log
// segmented_log index invariants
segmented_log.lowest_index = segmented_log.read_segments[0].lowest_index
segmented_log.highest_index = segmented_log.write_segment.highest_index
// record position invariants in store
records[i+1].position = records[i].position + records[i].record_header.length
// segment index invariants in segmented_log
segments[i+1].base_index = segments[i].highest_index = segments[i].index[index.len-1].index + 1
图:在 *nix 文件系统上持久化 segmented_log 数据结构的组织方式。
在新设计中,我们不是使用原始偏移量来引用记录,而是使用索引来引用它们。每个段的索引将记录索引转换为段存储文件中的原始文件位置。
现在,存储附加操作接受一个异步的字节流,而不是连续排列的字节片。我们使用此操作来写入记录字节,并在写入记录字节时,计算记录字节长度和校验和。一旦我们将记录字节写入存储,我们就将其对应的record_header(包含校验和和长度)、位置和索引作为一个index_record写入段索引。
这提供了两个用户体验改进
- 允许异步流式写入,无需连接中间的字节缓冲区
- 通过易于使用的索引更容易访问记录
现在,为了防止恶意用户通过恶意构建的请求来过度加载我们的存储容量和内存,我们为所有附加操作提供了一个可选的append_threshold参数。当提供时,它防止流式附加写入写入比提供的append_threshold更多的字节。
在段级别,这要求我们保持段溢出容量。现在所有段附加操作都使用segment_capacity - segment.size + segment_overflow_capacity作为append_threshold值。一个好的segment_overflow_capacity值可以是segment_capacity / 2。
执行模型
通用异步运行时(例如tokio、async-std等。)
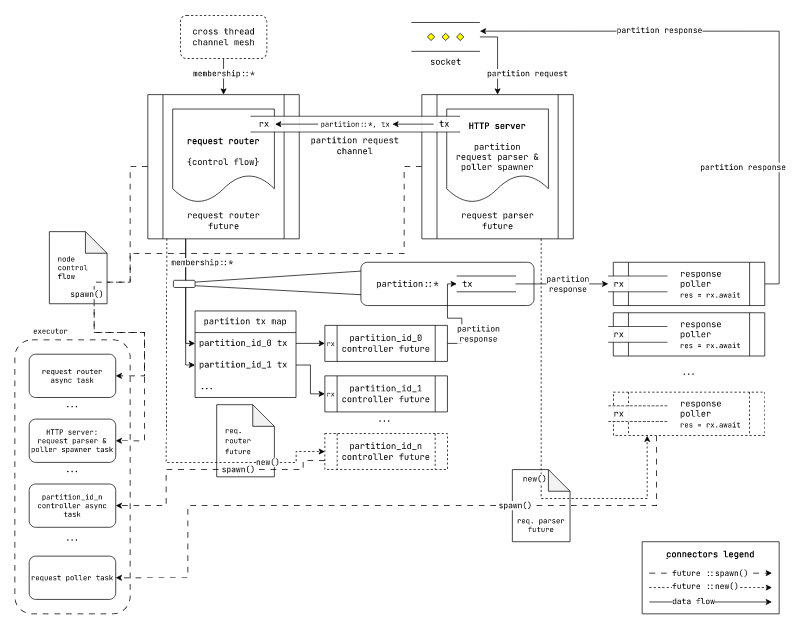
图:基于通用异步运行时的laminarmq执行模型
此执行模型基于所有Rust异步运行时使用的executor、reactor、waker抽象。我们不需要特别关心特定future的执行方式和位置。
在此执行模型中的数据流如下
- 一个HTTP服务器future从请求套接字解析HTTP请求
- 对于每个HTTP请求,它创建一个新的future来处理它
- HTTP处理器future通过通道将请求和响应通道tx发送到请求路由器。它还在响应rx端等待。
- 请求路由器future维护一个partition_id到每个分区控制器future指定的请求通道tx的映射。
- 对于每个接收到的分区请求,它将请求转发到适当的分区请求通道tx。如果收到
partition::create(...)请求,它创建一个新的分区控制器future。 - 分区控制器future将响应发送到提供的响应通道tx。
- 响应poller future接收它,并返回一个序列化的响应到套接字。
所有future都是使用异步运行时指定的{…}::spawn(…)方法创建的。我们不需要指定关于future对应的任务如何以及在哪里执行任何细节。
每个核心一个线程的异步运行时(例如glommio)
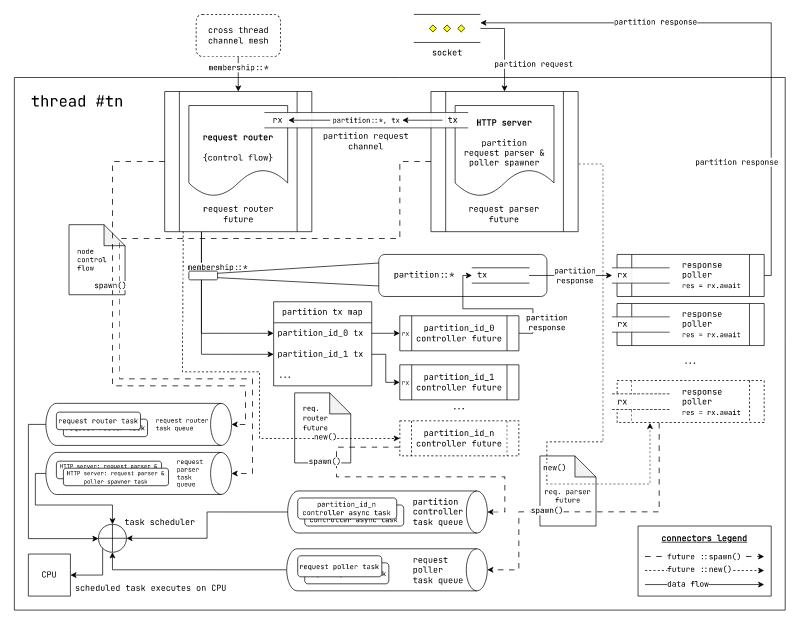
图:基于每个核心一个线程的异步运行时的laminarmq执行模型
在按核心线程模型中,由于每个处理器核心限制为单个线程,因此需要在线程中高效地调度任务。因此,每个工作线程运行自己的任务调度器。
我们目前使用glommio作为我们的按核心线程运行时。
在这里,可以在不同的任务队列中安排任务,并且不同的任务队列可以分配特定的CPU时间份额。通常,具有类似延迟特性的任务会在同一个任务队列上执行。例如,Web服务器任务将运行在与将数据持久化到磁盘的任务不同的队列上。
我们重用我们在通用异步运行时执行模型中使用的相同构造。唯一不同的是,我们明确关注未来任务类在哪个任务队列上执行。在我们的情况下,我们有以下4个任务队列
- 请求路由任务队列
- HTTP服务器请求解析任务队列
- 分区副本控制器任务队列
- 响应轮询任务队列
每个任务队列都可以分配特定的CPU时间份额。代码glommio还提供了根据它们的运行时延迟特性自动推断这些CPU时间份额的实用工具。
除此之外,glommio利用了新的Linux 5.x io_uring API,它为网络和磁盘接口提供真正的异步IO。 (其他async运行时,如tokio,在线程池中对磁盘IO操作进行阻塞系统调用。)
io_uring还有这样的优点:可以一起排队多个系统调用,然后通过最多进行一次上下文切换来异步等待它们的完成。还可以避免上下文切换。这是通过称为提交队列和完成队列的成对环形缓冲区实现的。一旦设置好队列,用户就可以在提交队列上排队多个系统调用。Linux内核处理系统调用,并将结果放入完成队列。然后,用户可以自由地从完成队列中读取结果。设置队列后的整个流程不需要任何额外的上下文切换。
阅读更多:https://man.archlinux.org/man/io_uring.7.en
glommio在io_uring之上提供了异步运行时的额外抽象,支持网络、磁盘IO、通道、单线程锁等。
阅读更多:https://www.datadoghq.com/blog/engineering/introducing-glommio/
测试
你可以像对任何其他crate一样使用cargo运行测试。然而,由于laminarmq即将支持多个运行时,一些运行时在运行步骤之前可能需要一些额外的设置。
例如,需要更新Linux内核(至少5.8)并支持io_uring的glommio异步运行时。glommio还需要至少512 KiB的锁定内存以使io_uring正常工作。(注意:512 KiB是启动单个executor所需的最小值。启动多个executor可能需要相应地提高限制。我建议在8 GiB RAM的机器上使用8192 KiB。)
首先,检查当前的memlock限制
ulimit -l
# 512 ## sample output
如果memlock资源限制(rlimit)小于512 KiB,你可以按照以下方式提高它
sudo vi /etc/security/limits.conf
* hard memlock 512
* soft memlock 512
为了使新的限制生效,你需要再次登录到机器。使用上述方法使用ulimit验证是否反映了限制。
(在旧版WSL版本中,你可能需要每次都启动一个登录shell,以便限制得到反映)
su ${USER} -l限制在登录外壳内部仍然存在。截至2022年12月22日的最新WSL2版本中,这不再是必需的。
最后,克隆存储库并运行测试
git clone https://github.com/arindas/laminarmq.git
cd laminarmq/
cargo test
基准测试
与测试相同的先决条件。一旦满足先决条件,您可以使用cargo正常运行基准测试
git clone https://github.com/arindas/laminarmq.git
cd laminarmq/
cargo bench
完整的最新基准测试报告可在https://arindas.github.io/laminarmq/bench/latest/report找到。
所有基准测试都是在以下机器上运行的
- 4核CPU(英特尔(R) 酷睿(TM) i5-7200U CPU @ 2.50GHz)
- 8GB RAM(SK Hynix HMA81GS6AFR8N-UH DDR4 2133 MT/s)
- 128GB SSD存储(SanDisk SD8SN8U-128G-1006)
精选基准测试报告
本节展示了部分精选的基准测试报告。
注意:我们使用以下名称表示不同的记录大小
size_name size comments tiny12bytesnone tweet140bytesnone half_k560bytes≈512bytesk1120bytes≈1024bytes(1KiB)linked_in_post2940bytes≤3000bytes(3 KB)blog11760bytes(11.76 KB)4X linked_in_post
commit_log write benchmark with 1KB messages

图:比较不同存储后端的时间消耗与输入大小(字节)(越低越好)
在此处查看更详细的基准测试报告here
此基准测试测量在不同commit_log存储后端写入大小为1KB的消息所需的时间。
我们还对不同存储后端进行了实施分析。以下是对DmaStorage后端的分析。

图:在DmaStorage后端上执行10,000次1KB消息写入的火焰图
如您所见,大量时间被花费在简单地散列请求字节上。
segmented_log streaming read benchmark with 1KB messages
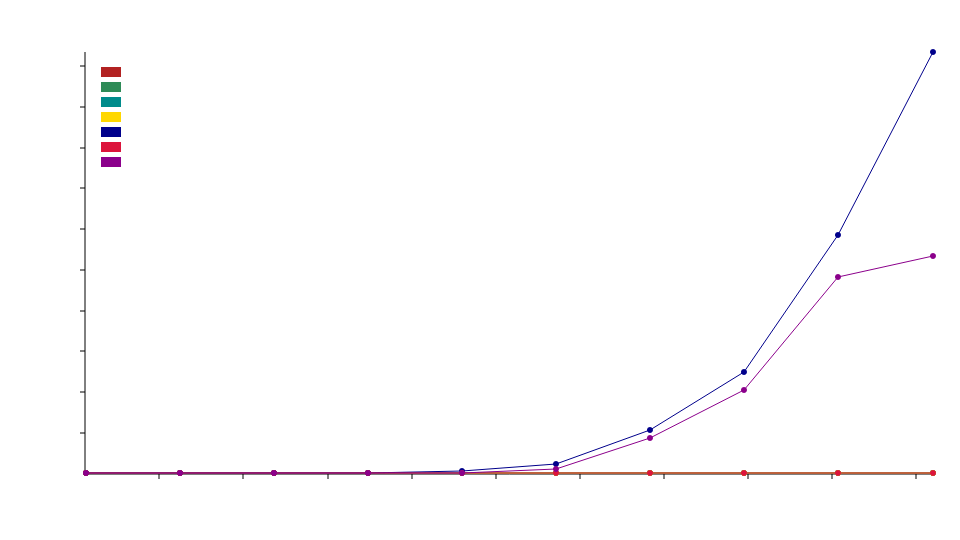
图:比较不同存储后端的时间消耗与输入大小(字节)(越低越好)
在此处查看更详细的基准测试报告here
此基准测试测量在不同segmented_log存储后端对大小为1KB的消息进行流式读取所需的时间。
我们还对不同存储后端进行了实施分析。以下是对DmaStorage后端的分析。

图:在DmaStorage后端上执行10,000次1KB消息读取的火焰图
在这种情况下,更多的时间花在系统调用和I/O上。
其余的基准测试报告可在https://arindas.github.io/laminarmq/bench/latest/report找到。
许可
laminarmq在MIT许可下授权。有关详细信息,请参阅许可。
依赖项
~19-34MB
~526K SLoC