1 个不稳定版本
| 0.21.0 |
|
|---|---|
| 0.20.1 | 2024年2月12日 |
#130 在 性能分析
11KB
86 行
使用这个 RISC Zero 分析器在水中行走

该仓库提供了一个 RISC Zero 程序的插件,它可以统计程序不同部分对循环数的贡献,检测导致大量循环的执行步骤,并解释其背后的原因。
开发者可以在程序中添加 start_timer!、stop_start_timer! 和 stop_timer! 来追踪循环的来源。以下是一个例子。
start_timer!("Load data");
......
start_timer!("Read from the host");
......
stop_start_timer!("Check the length");
......
stop_start_timer!("Hash");
......
stop_timer!();
stop_timer!();
分析器将输出有关循环分解的彩色信息。具体来说,如果分析器看到一个执行步骤,尽管它只导致少量循环,但它也会将其突出显示并找出其背后的原因。
有人可能会问,为什么我们说这个分析器是“水中行走”。这是因为,与基于 eprintln! 的先前解决方案不同,该分析器本身非常努力地不干扰程序的原始执行,特别是循环计数。
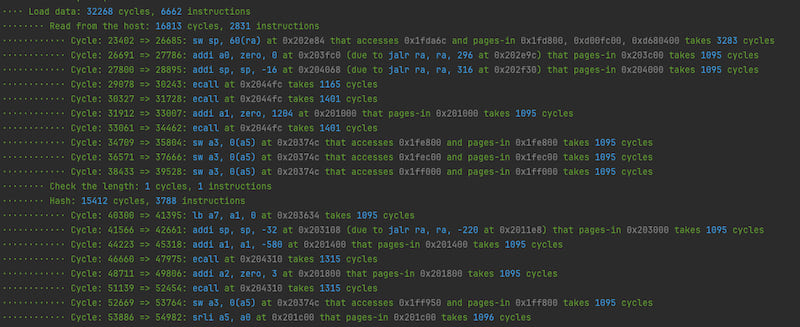
如何使用?
需要在 RISC Zero 程序的主机和客户端进行必要的更改。
主机
主机应使用主机 crate l2r0-profiler-host 并使用 ExecutorEnv 来运行程序。
let cycle_tracer = Rc::new(RefCell::new(CycleTracer::default()));
let env = ExecutorEnv::builder()
.write_slice(&task.a)
.write_slice(&task.b)
.write_slice(&task.long_form_c)
.write_slice(&task.k)
.write_slice(&task.long_form_kn)
.trace_callback(|e| {
cycle_tracer.borrow_mut().handle_event(e);
Ok(())
})
.build()
.unwrap();
let mut exec = ExecutorImpl::from_elf(env, METHOD_ELF).unwrap();
let _ = exec.run().unwrap();
cycle_tracer.borrow().print();
在上面的例子中,我们首先创建循环跟踪器。
let cycle_tracer = Rc::new(RefCell::new(CycleTracer::default()));
然后,我们使用 trace_callback 请求 ExecutorEnv 将执行跟踪发送回分析器。
.trace_callback(|e| {
cycle_tracer.borrow_mut().handle_event(e);
Ok(())
})
执行完成后,请请求循环跟踪器输出分析结果。
cycle_tracer.borrow().print();
客户端
客户端也有自己的 crate,l2r0-profiler-guest。导入它,并记得启用 print-trace 功能。
程序启动时,如下所示。
fn main() {
l2r0_profiler_guest::init_trace_logger();
start_timer!("Total");
......
stop_timer!();
}
我们首先初始化跟踪记录器。
l2r0_profiler_guest::init_trace_logger();
然后,客户端可以使用宏将程序分解成更小的部分进行检查。
它是如何工作的?
分析器的工作方式类似于硬件观察点。
当客户程序启动时,客户端周期跟踪器使用一些虚拟指令(写入零寄存器)来通知主机端周期跟踪器要监视的缓冲区。代码在此处:这里。
#[inline(always)]
pub fn init_trace_logger() {
unsafe {
core::arch::asm!(
r#"
nop
li x0, 0xCDCDCDCD
la x0, TRACE_MSG_CHANNEL
la x0, TRACE_MSG_LEN_CHANNEL
la x0, TRACE_SIGNAL_CHANNEL
nop
"#
);
}
}
主机端周期跟踪器将监视这三个通道。如果程序将这些数据写入这些内存位置,主机端周期跟踪器可以捕获这些更改并获取通道中的信息。
例如,
start_timer!(msg)将消息msg复制到TRACE_MSG_CHANNEL,并将消息长度写入TRACE_MSG_LEN_CHANNEL,这会触发主机端周期跟踪器标记一个新的计时器已开始。end_timer!()将零写入TRACE_SIGNAL_CHANNEL,这会触发主机端周期跟踪器标记之前的计时器已停止。
这两个计时器都设计得尽可能简单,因为我们希望它们不会占用太多周期。这是相对于之前在客户端使用 eprintln!("{}", env::get_cycle_count()); 的方法的一个显著改进,这本身就会创建很多周期并影响计算。
局限性
请注意,分析器只能看到内存写入,但不能看到内存读取。因此,尽管周期计数是正确的,但分析器只能解释一小部分重要的指令,说明周期从何而来。更具体地说,
- 如果一条指令使一个干净页变脏,分析器可以解释哪个页变脏了。
- 如果一条指令加载一个新页,分析器不能解释这条指令加载的是哪个页。
- 如果一条指令加载一个新页并立即将其变脏(这是从堆中分配的情况),分析器可以解释与该页变脏相关的周期,但不能解释与首次加载的页相关的周期。
另一个局限性是,当一个新的段开始时发生的所有周期都会计算到该段之后的第一条指令上。这些指令会有大量的周期,原因如下。
-
如果原本打算将指令放入之前的段,但空间不足,之前的段将提前关闭并使用虚拟周期。
-
当新段开始时,有预加载和后加载的周期。
-
现在新段没有加载的页,且没有页被标记为脏。这条指令可以触发许多页操作。假设这条指令是一个256位模数减少的系统调用,在最坏的情况下,
x、y、modulus和res每个都跨越两个页且不重叠,而res也跨越两个页且不重叠,系统调用的指令本身可能出现在新页中。这9个页甚至可以只共享根级页表,而不共享1级、2级、3级和4级页表——确保x、y、modulus、res在非常、非常特殊的位置交叉。请注意,res可能之前没有被读取过,因此它既要加载页又要将这些页标记为脏。这可以加载37页并标记11页为脏。
为了避免混淆,分析器将突出显示新段中的第一条指令。
如果您想对分页进行更精确的分析,请考虑使用RISC-Zero特定的GDB stub。
https://github.com/l2iterative/gdb0
此GDB stub提供了查询当前周期、已加载页数和脏页数的命令。
许可证
请参阅LICENSE。