11 个版本
| 0.2.5 | 2024年7月26日 |
|---|---|
| 0.2.4 | 2024年7月26日 |
| 0.2.2 | 2024年5月10日 |
| 0.1.5 | 2024年5月4日 |
#169 在 并发
每月 375 次下载
用于 2 crates
33KB
361 行
k-lock
一种用于保护共享数据的互斥原语
此互斥锁将阻塞等待锁变为可用的线程。互斥锁可以通过 [new] 构造函数创建。每个互斥锁都有一个类型参数,表示它所保护的数据。数据只能通过从 [lock] 和 [try_lock] 返回的 RAII 守卫来访问,这保证了数据只在互斥锁被锁定时才被访问。
与 std::sync::Mutex 的区别
16 线程,短临界区表达式:*mutex.lock() += 1;
Mac OS
目前此锁未针对 Mac OS 进行优化。在 Mac OS 上快速加锁的方法是使用 pthread_mutex,这尚未在 k-lock 中实现。如果您需要您的互斥锁在 Mac OS 上表现良好,您需要使用 std::sync::Mutex。
AWS c7g.2xlarge aarch64
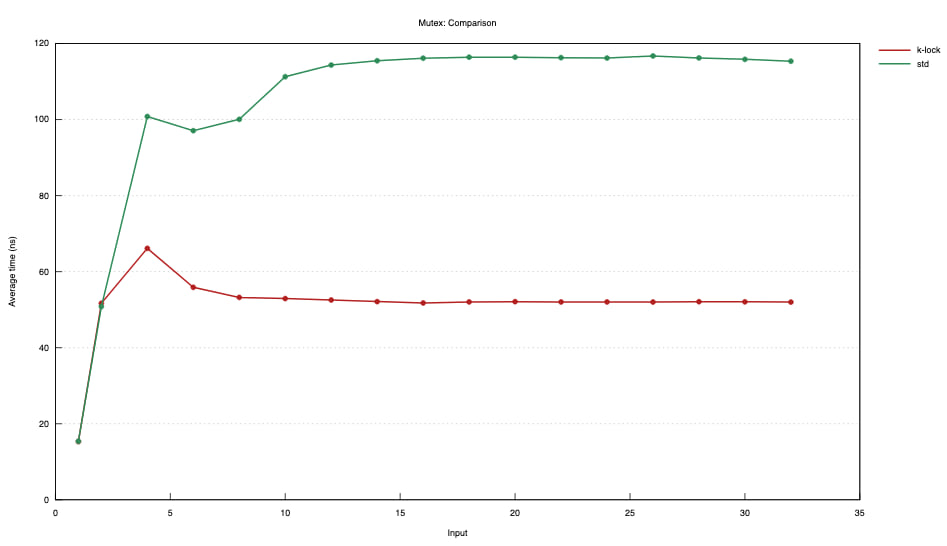
微小的临界区
哈希表临界区
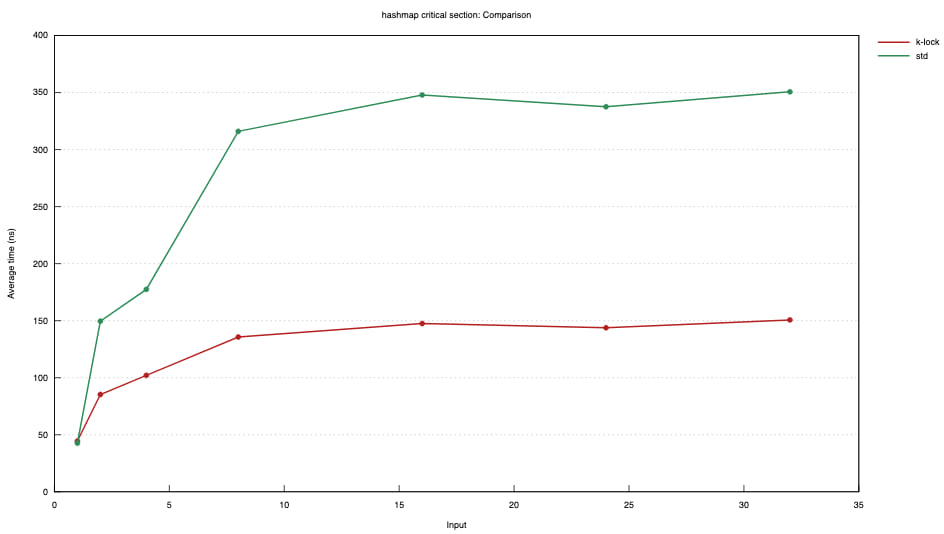
线程数位于 X 轴上。
关于
此互斥锁针对简短临界区进行了优化。它通过快速进展时持续自旋来避免系统调用。当竞争激烈时,它还积极唤醒多个等待者。
在某些情况下,std::sync::Mutex 可能更好。始终,分析和测量很重要。此互斥锁经过测试,在用于与 HashMap 一起工作的简短锁上优于 std::sync::Mutex,但需要进一步研究以确定其适用于更长时间范围。
本模块中的互斥锁实现及其文档大多借鉴了备受尊敬的 std::sync::Mutex 的内容和经验,在此表示衷心的感谢。
中毒策略
本模块中的互斥锁采用了 std::sync::Mutex 的中毒策略。
预期大多数使用本互斥锁的场景都将使用 lock().expect("description") 将一个线程的恐慌传播到所有同步线程中。
示例
use std::sync::Arc;
use std::thread;
use std::sync::mpsc::channel;
use k_lock::Mutex;
const N: usize = 10;
// Spawn a few threads to increment a shared variable (non-atomically), and
// let the main thread know once all increments are done.
//
// Here we're using an Arc to share memory among threads, and the data inside
// the Arc is protected with a mutex.
let data = Arc::new(Mutex::new(0));
let (tx, rx) = channel();
for _ in 0..N {
let (data, tx) = (Arc::clone(&data), tx.clone());
thread::spawn(move || {
// The shared state can only be accessed once the lock is held.
// Our non-atomic increment is safe because we're the only thread
// which can access the shared state when the lock is held.
//
// We unwrap() the return value to assert that we are not expecting
// threads to ever fail while holding the lock.
let mut data = data.lock().unwrap();
*data += 1;
if *data == N {
tx.send(()).unwrap();
}
// the lock is unlocked here when `data` goes out of scope.
});
}
rx.recv().unwrap();
要早于包围作用域的末尾解锁互斥锁保护,可以创建一个内部作用域或手动丢弃保护。
use std::sync::Arc;
use std::thread;
use k_lock::Mutex;
const N: usize = 3;
let data_mutex = Arc::new(Mutex::new(vec![1, 2, 3, 4]));
let res_mutex = Arc::new(Mutex::new(0));
let mut threads = Vec::with_capacity(N);
(0..N).for_each(|_| {
let data_mutex_clone = Arc::clone(&data_mutex);
let res_mutex_clone = Arc::clone(&res_mutex);
threads.push(thread::spawn(move || {
// Here we use a block to limit the lifetime of the lock guard.
let result = {
let mut data = data_mutex_clone.lock().unwrap();
// This is the result of some important and long-ish work.
let result = data.iter().fold(0, |acc, x| acc + x * 2);
data.push(result);
result
// The mutex guard gets dropped here, together with any other values
// created in the critical section.
};
// The guard created here is a temporary dropped at the end of the statement, i.e.
// the lock would not remain being held even if the thread did some additional work.
*res_mutex_clone.lock().unwrap() += result;
}));
});
let mut data = data_mutex.lock().unwrap();
// This is the result of some important and long-ish work.
let result = data.iter().fold(0, |acc, x| acc + x * 2);
data.push(result);
// We drop the `data` explicitly because it's not necessary anymore and the
// thread still has work to do. This allow other threads to start working on
// the data immediately, without waiting for the rest of the unrelated work
// to be done here.
//
// It's even more important here than in the threads because we `.join` the
// threads after that. If we had not dropped the mutex guard, a thread could
// be waiting forever for it, causing a deadlock.
// As in the threads, a block could have been used instead of calling the
// `drop` function.
drop(data);
// Here the mutex guard is not assigned to a variable and so, even if the
// scope does not end after this line, the mutex is still released: there is
// no deadlock.
*res_mutex.lock().unwrap() += result;
threads.into_iter().for_each(|thread| {
thread
.join()
.expect("The thread creating or execution failed !")
});
assert_eq!(*res_mutex.lock().unwrap(), 800);
依赖
~0–10MB
~43K SLoC