2个稳定版本
| 1.0.14 | 2024年2月22日 |
|---|
426 在 编程语言
2.5MB
6K SLoC
包含 (ELF 可执行文件/库, 6.5MB) bench/work/main.bin
高阶虚拟机 (HVM)
高阶虚拟机 (HVM) 是一个纯函数运行时,它是 惰性 的,非垃圾回收 的和 大规模并行 的。它也是 beta-最优 的,这意味着对于高阶计算,在某些情况下,它可能比其他替代方案(包括Haskell的GHC)指数级(在渐近意义上)更快。
这是由于一个新的计算模型,即 交互网,它取代了 图灵机 和 λ演算。该模型之前的实现效率低下,然而,最近的突破极大地提高了其效率,从而产生了HVM。尽管它相对较新,但它在某些情况下已经超过了成熟的编译器,并且正在不断改进。
欢迎来到计算机大规模并行的未来!
即将推出生产版本!
这里的代码是一个原型,但首个生产就绪版本即将推出,包含大量的优化以及最重要的正确性工作。在此跟踪进度:HVM-Core。
示例
本质上,HVM是一种极简主义函数式语言,编译成基于Interaction Nets的新型运行时。这种方法不仅内存高效(不需要GC),还具有两个显著优势:自动并行性和beta最优性。其想法是,您编写一个简单的函数式程序,HVM将其转换为大规模并行、beta最优的可执行程序。下面的例子突出了这些优势在实际中的表现。
冒泡排序
| 来源:HVM/examples/sort/bubble/main.hvm | 来源:HVM/examples/sort/bubble/main.hs |
|
|
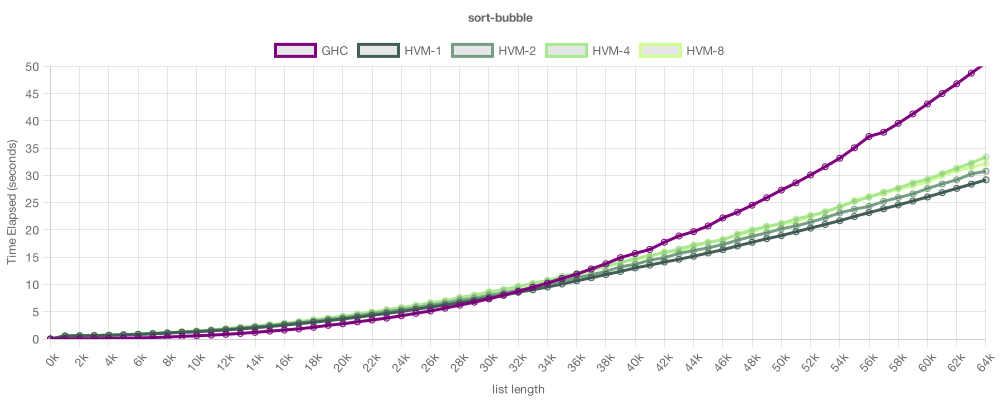
在这个例子中,我们在HVM和GHC(Haskell的编译器)上运行了一个简单的、递归的冒泡排序。注意算法是相同的。图表显示了每个运行时排序给定大小列表所需的时间(越低越好)。紫色线表示GHC(单线程),绿色线表示HVM(1、2、4和8线程)。如您所见,它们的性能相似,HVM略胜一筹。遗憾的是,在这里,其性能并没有随着核心的增加而提高。这是因为这种冒泡排序的实现是固有的顺序,所以HVM无法改进它。
基数排序
| 来源:HVM/examples/sort/radix/main.hvm | 来源:HVM/examples/sort/radix/main.hs |
|
|
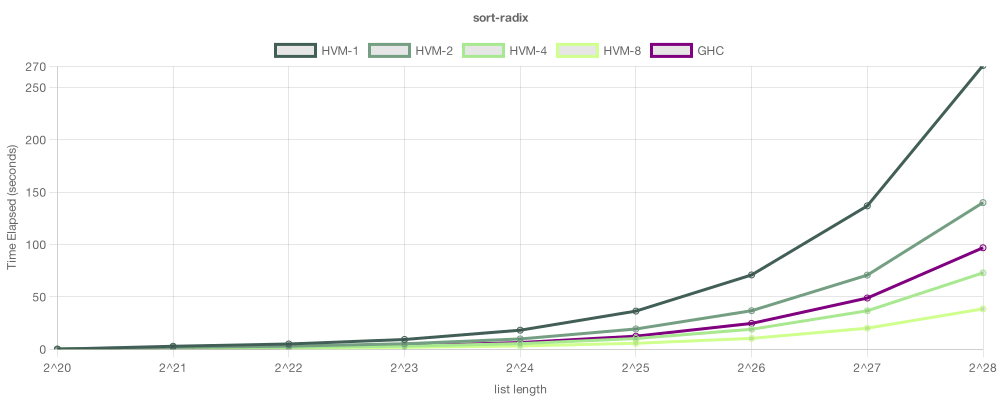
在这个例子中,我们尝试了一个基于合并不可变树的基数排序。在这个测试中,目前GHC的单线程性能更优——这通常是情况,因为GHC历史悠久,具有天文数字的微观优化——然而,由于这个算法是固有的并行的,所以在足够的核心下,HVM能够超越GHC。在有8个线程的情况下,HVM将大型列表排序得比GHC快2.5倍。
请注意,可以通过在Haskell版本中使用par注解来并行化,但这需要耗时且昂贵的重构——在某些情况下,甚至无法仅使用par来实现所有可用的并行性。另一方面,HVM会自动将并行工作负载分配到所有可用的核心,实现横向可扩展性。随着HVM的成熟,单线程的差距将显著减少。
lambda乘法
| 来源:HVM/examples/lambda/multiplication/main.hvm | 来源:HVM/examples/lambda/multiplication/main.hs |
|
|
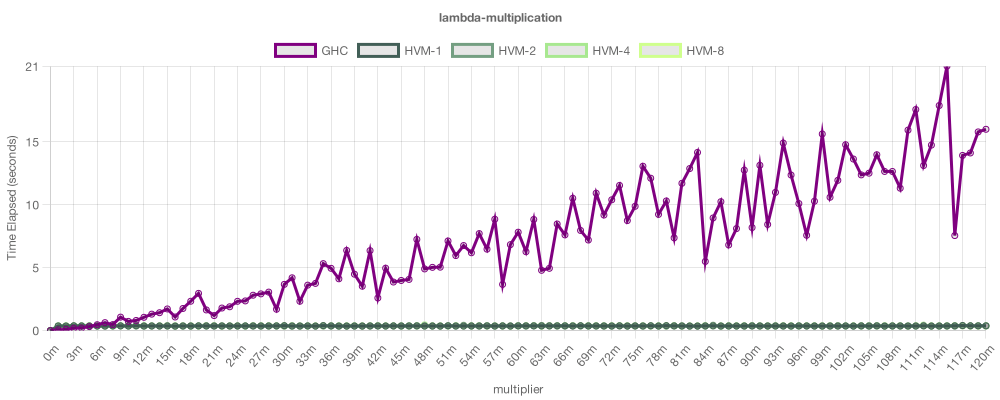
本例通过使用λ-编码实现了位运算乘法。它的目的是展示HVM(高阶虚拟机)的另一个重要优势:β优化。此图表没有错误:HVM乘以λ编码数字比GHC快得多,因为HVM可以处理非常高级的程序,具有最优的渐近性,而GHC则不能。这种技术可能看起来很神秘,但它实际上对于设计高效的函数式算法非常有用。例如,一个应用是实现对不可变数据类型的运行时消去。总的来说,HVM能够在线性时间内应用任何可融合函数2^n次,这听起来不可能,但确实如此。
图表制作于plotly.com。
入门指南
-
安装Rust nightly版
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh rustup toolchain install nightly -
安装HVM
cargo +nightly install hvm -
运行HVM表达式
hvm run "(@x(+ x 1) 41)"
就这样!要了解更高级的使用方法,请查看完整指南。
更多信息
-
要了解更多关于底层技术的信息,请查看
guide/HOW.md。 -
要提问和加入我们的社区,请查看我们的Discord服务器。
-
要直接联系作者,请发送电子邮件至taelin@higherorderco.com。
常见问题解答
HVM在单个核心上比GHC快吗?
不是。目前,HVM在单线程性能上似乎从50%快到3倍慢,如果Haskell代码利用了HVM尚未实现的优化(ST Monad、可变数组、内联、循环),甚至会更慢。
HVM比Rust快吗?
不是。
HVM比C快吗?
不是!
HVM有一天会快过这些吗?
这是一个难题。也许!底层模型非常高效。HVM与Rust共享相同的初始核心(affine λ-calculus),具有优秀的内存管理(没有thunks,没有垃圾收集)。有些人认为交互网是开销,但这并非如此——它们是缺乏开销。例如,HVM上的lambda函数仅使用2个64位指针,这几乎是轻量级的。此外,HVM的每个归约规则都是一个轻量级、常数时间的操作,可以编译成非常快的机器代码。因此,考虑到足够的优化,从正确的内联到真正的循环,再到内部可变性(FBIP-like?),我相信HVM有一天可以与GHC甚至Rust或C相媲美。但我们还有很长的路要走。
为什么基准测试比较单线程与多核心?
它们并不比较!请注意,所有基准测试都包括单线程HVM执行的一行,这通常比GHC慢3倍。我们包括多线程HVM执行,以便我们可以可视化其性能如何随着核心数量的增加而扩展,而无需更改代码。我们不包含多核心GHC执行,因为GHC不支持自动并行性,因此在不更改代码的情况下无法使用线程。请记住,再次提醒,基准测试并没有声称HVM比GHC快。
HVM支持完整的λ-Calculus还是System-F?
还不是!HVM是TOIOFPL书中提出的无账本的归约算法的实现,直到第40页。因此,它不支持一些λ项,例如
(λx.(x x) λf.λx.(f (f x)))
虽然HVM是图灵完备的,因此可以在其上实现完整的λ-演算解释器——但这种限制仅针对内置闭包。请注意,许多流行的语言也不包含完整的λ-演算闭包;例如,Rust由于借用系统,仅覆盖了非常受限的子集。话虽如此,HVM涵盖了广泛的λ-项类别,包括Y-组合子、教堂编码(甚至算法如加法、乘法和指数运算),以及任意数据类型(包括原生和斯科特编码)和递归。
HVM是否会支持完整的λ-演算或System-F?
是的!我们计划通过实现TOIOFPL中描述的完整算法来实现,即第40页之后。遗憾的是,这导致了大约10倍的性能开销。因此,我们想要谨慎行事,以保持HVM的效率。目前,计划如下:
-
将λ表达式分为全λ表达式和轻λ表达式
-
轻λ表达式是HVM目前的实现。它们速度快,但不支持完整的λ-演算。
-
全λ表达式会慢一些,但通过“内部括号/交叉面包”,支持完整的λ-演算。
-
-
为了减少开销,使用EAL推理将全λ表达式转换为轻λ表达式
基本仿射逻辑是一种拒绝合同结构规则的子结构逻辑,用受控形式的复制代替它。通过将EAL推理扩展到HVM,我们将能够将大多数全λ表达式转换为轻量级λ表达式,从而大大减少相关的减速。
最后,请注意,这仅涉及λ表达式。低阶项(构造函数、树、递归)不受影响。
不受支持的项是“未定义行为”吗?
不是!不受支持的λ项,如λx.(x x) λf.λx.(f (f x))不会导致HVM显示未定义行为。HVM将始终表现出确定性,并为任何输入提供正确的结果,只是结果将以交互演算(IC)语义表示。IC是λ演算(LC)的替代品,它在处理非线性变量方面略有不同。因此,这些“不受支持”的项只是LC和IC评估不一致的情况。理论上,你可以将HVM用作交互网运行时,并且在这些语义下它总是会给出完全正确的答案——但这并不常见,所以我们很少谈论它。
HVM的主要创新是什么?简单来说?
在复杂的术语中,HVM的主要创新是它是交互网的效率实现,交互网是一种并发计算模型。但是,有一种方法可以将其翻译成更熟悉的术语。HVM的性能、并行性和无GC自由都源于其基于线性核心的事实——就像Rust一样!但是,在它之上,而不是添加循环和引用(加上“借用检查器”),HVM添加了递归和一种懒、增量克隆原语。例如,以下表达式:
let xs = (Cons 1 (Cons 2 (Cons 3 Nil))) in [xs, xs]
计算为
let xs = (Cons 2 (Cons 3 Nil)) in [(Cons 1 xs), (Cons 1 xs)]
注意第一个Cons 1层是增量复制的。这使得复制几乎免费,就像Haskell的懒评估器允许你创建无限列表一样:只有在实际读取副本时才会产生成本!这种懒克隆原语无处不在,涵盖了HVM运行时的所有原语:构造函数、数字和λ表达式。然而,这种想法在λ表达式中会失败:如何增量复制λ表达式呢?
let f = λx. (2 + x) in [f, f]
如果你尝试这样做,你会意识到为什么这是不可能的
let f = (2 + x) in [λx. f, λx. f]
这个问题的解决方案是交互网模型带来的主要洞察,更详细的描述可以在HOW.md文档中找到。
是否HVM总是渐近比GHC快?
编号。在大多数常见情况下,它具有相同的渐近性。在某些情况下,它将更快地呈指数增长。在这个问题中,用户发现HVM显示某些函数具有二次渐近性,而GHC以线性时间计算这些函数。这让我感到惊讶,据我所知,尽管它有“最优”的标签,但似乎是底层理论的局限性。话虽如此,有几种方法可以缓解或解决此问题。一种方法是在书中也描述了“安全指针”,这会减少克隆开销,并将某些二次情况转换为线性。但这并不适用于所有情况。另一种补充方法是进行线性分析,将问题二次程序转换为更快的线性版本。最后,在最坏的情况下,我们可以像Haskell那样添加引用,但应该非常小心,以免破坏并行执行引擎所做的假设。要了解更多信息,请参阅Hacker News上的评论。
HVM的最优性是否仅适用于奇怪、学术性的λ编码术语?
不是。HVM的最优性带来了一些非常实用的好处。例如,所有Haskell作为编译时重写规则采用的“去林”技术,在HVM中都会自然地发生,在运行时。例如,Haskell优化
map f.map g
转换为
map(f.g)
这是一个硬编码的优化。在HVM中,这种优化会在运行时以非常通用和普遍的方式进行。因此,例如,如果你有类似
foldr (.) id funcs :: [Int -> Int]
GHC将无法将funcs列表中的函数“融合”,因为它们在编译时是未知的。HVM可以很好地完成这项工作。请参阅这个问题以获取实际示例。
λ编码的另一个实用应用是用于单子。在Haskell中,Free Monad库使用Church编码作为重要的优化。没有它,绑定的渐近性会使自由单子变得不太实用。HVM对Church编码数据的渐近性最优,这使得它在这些问题上表现良好。
为什么HVM如此易于并行化?
因为它完全线性:每个数据项在同一时间只出现在一个地方,这减少了同步的需求。此外,它是纯的,因此没有需要通信的全局副作用。正因为如此,并行化HVM表达式实际上非常简单:我们只需维护一个红ex的工作流式队列,并让一组线程计算它们。尽管如此,HVM需要同步的两个地方
-
在用于懒加载克隆的dup节点上:需要一个锁来防止线程通过,从而访问相同的数据
-
在替换操作上:这是因为替换可能会将数据从一条线程发送到另一条线程,因此必须原子性地执行
理论上,Haskell也可以并行化,GHC开发者曾尝试过,但我相信STG模型的非线性会使问题比HVM复杂得多,这可能导致由于同步开销而损失太多性能。
与其他运行时相比,HVM的内存占用如何?
有一种常见的误解,即“交互式”运行时会消耗比像Rust这样的“过程式”运行时更多的内存。情况并非如此。交互网络,如HVM实现的那样,不会增加任何开销,并且HVM会立即收集任何变得不可达的数据,就像Rust一样,因此没有积累的thunks会导致世界停止的垃圾收集,就像当前Haskell所发生的那样。
尽管如此,目前HVM尚未实现内存高效特性,如引用、循环和局部可变性。因此,要在HVM上做任何事情,您需要使用不可变数据类型和递归,这些特性自然会占用更多内存。因此,与C和Rust程序相比,今天的HVM程序将具有更大的内存占用。幸运的是,没有理论上的限制阻止我们添加循环和局部可变性,一旦我们这样做,我们可以期待与Rust相同的内存占用。唯一的缺点是共享引用:我们不确定是否要添加这些特性,因为它们可能会影响并行性。因此,我们可能会选择让惰性克隆成为唯一的形式的非线性,这将保持并行性,但可能会使一些算法更占用内存。
HVM的目的是取代GHC吗?
不是!GHC实际上是一个非常优秀、辉煌的运行时,很难与之匹敌。HVM旨在成为轻量级、大规模并行运行时,适用于函数式语言,甚至命令式语言,从Elm到JavaScript。话虽如此,我们确实想支持Haskell,但这将需要HVM达到一个成熟的后期阶段,同时还需要提供对完整lambda的支持,目前它还不支持。一旦我们这样做,HVM可以成为GHC的一个很好的替代品,为Haskell社区提供一个选项,在具有自动并行性、没有缓慢的垃圾收集器和beta-最优化的运行时中运行。最好的选择可能取决于您编译的应用程序类型,但拥有更多的选择通常更好,因此HVM可以成为Haskell社区的一个很好的工具。
HVM已经准备好投入生产了吗?
不是。HVM仍被视为一个原型。目前,我直接在上面工作了不到3个月。它比GHC和V8等其他编译器和运行时成熟得多。话虽如此,我们正在筹集资金,以便有一个专业的工程师团队专注于HVM。如果一切顺利,我们可以在2024年第一季度推出一个可用于生产的版本。
我运行了一个HVM程序,它消耗了1950GB,我的电脑爆炸了。
HVM是一个原型。预期会有错误。请打开一个问题!
我在生产中使用了HVM,现在我的公司破产了。
我辞职了。
相关工作
依赖关系
~6–9.5MB
~185K SLoC