5 个版本 (2 个稳定)
使用旧的 Rust 2015
| 1.0.1 | 2018年12月4日 |
|---|---|
| 1.0.0 | 2017年7月5日 |
| 0.1.2 | 2017年6月29日 |
| 0.1.1 | 2017年6月29日 |
| 0.1.0 | 2017年6月28日 |
#811 在 并发
3,243 每月下载量
用于 7 个 Crates (2 个直接)
35KB
128 行
hurdles
![]()
![]()
![]()
一个可扩展的屏障(类似于 std::sync::Barrier),允许多个线程同步某些计算的开始。
此 crate 提供与 std::sync::Barrier 相似的接口,但在许多并发等待的线程面前表现更好,并且每个线程的延迟惩罚更低(请参阅下面的基准测试)。但是,接口与标准库屏障有所不同
- 此 crate 中的
Barrier是Clone,不应该用sync::Arc包装。 - 此 crate 中的
Barrier::wait接收一个&mut self接收器,因为每个线程都必须保持一些本地状态。
此外,当线程在 Barrier::wait 上阻塞时,线程将(目前)永远不会 被挂起,而是围绕屏障自旋。在前几次自旋中,它也不会调用 sched_yield 以避免线程睡眠/唤醒的开销。如果预计线程几乎同时到达屏障,或者屏障延迟至关重要,这可能正是您想要的。但是,如果屏障间隔较远,那么您可能希望使用 std::sync::Barrier,因为它在处理长时间等待方面表现更好。
示例
use hurdles::Barrier;
use std::thread;
let mut handles = Vec::with_capacity(10);
let mut barrier = Barrier::new(10);
for _ in 0..10 {
let mut c = barrier.clone();
// The same messages will be printed together.
// You will NOT see any interleaving.
handles.push(thread::spawn(move|| {
println!("before wait");
c.wait();
println!("after wait");
}));
}
// Wait for other threads to finish.
for handle in handles {
handle.join().unwrap();
}
实现
在编写本文档时,std::sync::Barrier 的内部实现使用 Mutex,这会导致许多等待的线程之间的竞争,并且每次调用 wait 时都会产生不必要的性能开销。
这个crate实现了Mellor-Crummey和Scott在1991年发表的论文《在共享内存多处理器上的可扩展同步算法》中“3.1集中式屏障”部分所描述的基于计数的线性屏障,具体可参考Algorithms for scalable synchronization on shared-memory multiprocessors。若需更高级的解释,请参阅Lars-Dominik Braun的屏障算法简介。
数字
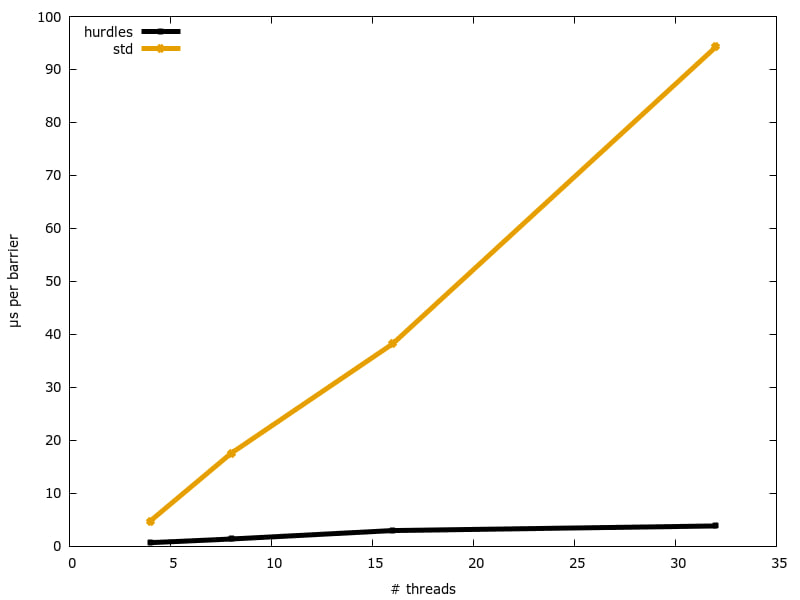
现代2核心(4HT)的Intel Core i7-5600U笔记本 @ 2.60GHz
test tests::ours_2 ... bench: 190 ns/iter (+/- 24)
test tests::std_2 ... bench: 2,054 ns/iter (+/- 822)
test tests::ours_4 ... bench: 236 ns/iter (+/- 2)
test tests::std_4 ... bench: 11,913 ns/iter (+/- 60)
戴尔服务器,配备两个10核心(20HT)的Intel Xeon E5-2660 v3 @ 2.60GHz,分布在两个NUMA节点上
test tests::ours_4 ... bench: 689 ns/iter (+/- 9)
test tests::std_4 ... bench: 4,762 ns/iter (+/- 151)
test tests::ours_8 ... bench: 1,380 ns/iter (+/- 13)
test tests::std_8 ... bench: 17,545 ns/iter (+/- 288)
test tests::ours_16 ... bench: 2,970 ns/iter (+/- 33)
test tests::std_16 ... bench: 38,215 ns/iter (+/- 469)
test tests::ours_32 ... bench: 3,838 ns/iter (+/- 129)
test tests::std_32 ... bench: 94,266 ns/iter (+/- 12,243)
或者,以下图示形式
依赖项
~1MB
~15K SLoC