9个版本 (5个重大更改)
| 0.6.1 | 2024年6月24日 |
|---|---|
| 0.6.0 | 2024年3月11日 |
| 0.5.1 | 2024年2月25日 |
| 0.5.0 | 2024年1月24日 |
| 0.1.1 | 2023年11月29日 |
#271 在 数据结构
每月131 次下载
230KB
4.5K SLoC
分层稀疏bitset
![]()
![]()
![]()
bitset之间操作(交集、并集等)的性能高。内存使用低。
类似于hibitset,但内存消耗更低。与hibitset不同,它实际上是稀疏的——内存使用不依赖于集合中的最大索引。只有使用的块数量(或元素)才是关键。同样地,它也利用分层位掩码加速结构来减少bitset之间操作的计算复杂性。
使用
use hi_sparse_bitset::reduce;
use hi_sparse_bitset::ops::*;
type BitSet = hi_sparse_bitset::BitSet<hi_sparse_bitset::config::_128bit>;
let bitset1 = BitSet::from([1,2,3,4]);
let bitset2 = BitSet::from([3,4,5,6]);
let bitset3 = BitSet::from([3,4,7,8]);
let bitset4 = BitSet::from([4,9,10]);
let bitsets = [bitset1, bitset2, bitset3];
// reduce on bitsets iterator
let intersection = reduce(And, bitsets.iter()).unwrap();
assert_equal(&intersection, [3,4]);
// operation between different types
let union = intersection | &bitset4;
assert_equal(&union, [3,4,9,10]);
// partially traverse iterator, and save position to cursor.
let mut iter = union.iter();
assert_equal(iter.by_ref().take(2), [3,4]);
let cursor = iter.cursor();
// resume iteration from cursor position
let iter = union.iter().move_to(cursor);
assert_equal(iter, [9,10]);
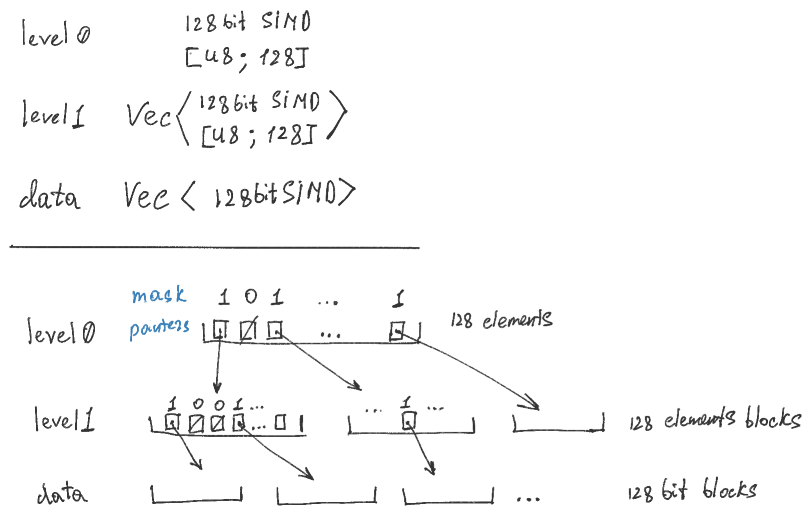
内存占用
由于是真正稀疏的,hi_sparse_bitset只为使用的块分配内存。hi_sparse_bitset::BitSet具有三级层次结构,第一和第二级包含位掩码和间接信息,第三级是实际的位数据。目前,整个第一级(本身就是一个块)和第二级的一个块总是被分配。
对于config::_128bit的层次结构内存开销:最小(初始)= 416字节,最大 = 35 Kb。
SmallBitSet
hi_sparse_bitset::SmallBitSet使用“SparseBitMap”技术而不是完整大小的数组来存储块指针,这允许仅存储指向非空块的指针。然而,这项技术引入了一些额外的性能开销,但所有操作仍然具有O(1)的复杂度,就像BitSet一样。
性能
它在所有bitset之间操作和所有情况下都比hashset和纯bitset快得多。甚至比hibitset还要快。请参阅基准测试。
与hibitset比较
尽管hi_sparse_bitset在访问每一级时有一个间接层,但它对于所有操作都比hibitset快(有时显著)。
此外,由于缓存迭代器可以跳过具有空级1块的bitset,因此它也在非交集的bitset之间操作中比hibitset在算法上更快。
与roaring比较
roaring 是一种混合bitset,使用排序的位块数组来存储大整数集合,而对于小集合则使用大固定大小的bitset。让我们考虑一个交错的 roaring 集合的情况,其中包含大整数。为了找到交集,它通过二分查找具有相同起始索引的位块,然后逐个交集位块。二分查找匹配位块的操作在算法上更复杂,为 O(log N),然后直接在层次结构中遍历交集位块,对于每个结果位块,这接近 O(1)。此外,由于位集合的树状结构,层次位集合可以提前丢弃非交集块组。
数据块操作
为了进一步提高速度,您可以直接与 DataBlock 进行操作。 DataBlock 是相对较小(相对而言)的位块,您可以存储和稍后迭代。
在未来的版本中,您还可以将 DataBlock 插入到 BitSet 中。
位集合迭代器的减少
除了“常规”的位集合到位集合(二进制)操作外,您还可以对位集合的迭代器(减少/折叠)应用操作。这样,您不仅可以对任意数量的位集合应用操作,而且对于任何位集合的数量,都会得到相同的结果类型。这允许有嵌套的减少操作。
有序/排序
迭代始终返回排序的序列。
使用游标挂起和恢复迭代器
BitSetInterface(任何类型的位集合)的迭代器可以返回游标,并可以回滚到游标。游标类似于 Vec 中的整数索引。这意味着,即使容器被更改,您也可以使用它。
多会话迭代
使用游标,您可以挂起迭代会话并在以后恢复。例如,您可以在多个位集合之间创建交集,迭代到某个点,并获取一个迭代器游标。然后,稍后,您可以在不同的状态(如果有的话)下创建相同的位集合之间的交集,并使用游标从上次停止的位置恢复迭代。
线程安全的多会话迭代
您也可以在多线程环境中使用“多会话迭代”。 (通过将位集合包装在 Mutex 中)
不变交集
如果位集合的交集(或任何其他操作)不会因位集合的突变而改变,则您有保证正确遍历其所有元素。
位集合突变缩小交集/并集
如果在交集中,只有 remove 操作会突变位集合,则这保证了在“多会话迭代”结束时您不会丢失任何有效元素。
投机迭代
对于其他情况,您可以保证向前推进,没有重复元素。 (在每次迭代会话中,您将看到初始有效元素和一些新的有效元素) 如果您不需要遍历确切的交集,则可以使用此功能。例如,如果在一个循环中重复处理相同的位集合的交集。
变更日志
有关版本差异,请参阅 CHANGELOG.md。
已知替代方案
-
hibitset - 层次密集型bitset。如果您插入一个索引 = 16_000_000,它将分配 2Mb 的 RAM。它使用 4 级层次结构,并且由于是密集型 - 不使用间接引用。这使得层次结构开销较小,并且在交集操作中它应该表现得更好 - 但实际上并没有(可能是因为额外的层次结构级别或某些实现细节)。
-
bitvec - 纯密集型bitset。基本操作(插入/包含)应相对较快(不是数量级)。bitset之间的操作 - 最坏情况下超线性慢(几乎总是如此),在最佳情况下性能大致相同(当每个bitset块都使用时)。本身没有内存开销,但内存使用量取决于bitset中的最大整数,因此如果您不需要进行bitset之间的操作,并且知道您的索引是相对较小的数字,或者预期bitset将被密集填充 - 这是个不错的选择。
-
HashSet<usize>- 您只有在处理一个相对较小且数字极大的集合时才应使用它。bitset之间的操作要慢几个数量级。其他操作也“仅仅”慢一些。 -
roaring - 压缩的混合bitset。操作的算法复杂度更高,但理论上具有无限的范围。它在bitset之间的操作中仍然比纯密集型bitset和hashset快几个数量级。有关详细信息,请参阅性能部分。
依赖项
约220KB