5个版本
| 0.1.4 | 2022年12月1日 |
|---|---|
| 0.1.3 | 2022年12月1日 |
| 0.1.2 | 2022年11月30日 |
| 0.1.1 | 2022年11月29日 |
| 0.1.0 | 2022年11月18日 |
#1586 在 解析器实现
76KB
1.5K SLoC
Gutenberg-RS
此包使从Rust中过滤和获取古腾堡(http://www.gutenberg.org)信息变得更容易。它最初是Python版本的移植,但现在在多个方面有所不同。
目标受众是那些需要为其项目获取数据的机器学习工作者,但任何人都可以自由使用。
包
- 生成一个本地缓存(所有古腾堡信息),您可以对其进行查询以获取书籍ID。本地缓存可以是sqlite(默认)
- 从古腾堡书籍下载并清理原始文本
该包已在Windows和Linux上使用Rust 1.64.0进行了测试。它比Python版本更快、更小。
用法
构建sqlite缓存
let settings = GutenbergCacheSettings::default();
setup_sqlite(&settings, false, true).await?;
这将使用默认设置并构建缓存(如果尚未构建)。它将下载古腾堡的存档,解包,解析并存储信息。构建缓存后,您可以通过辅助函数或本地sqlite查询获取和查询它。
let mut cache = SQLiteCache::get_cache(&settings).unwrap();
let res = cache.query(&json!({
"language": "\"en\"",
}))?;
辅助查询函数将返回书籍ID,然后您可以像这样使用它们
use gutenberg_rs::sqlite_cache::SQLiteCache;
use gutenberg_rs::text_get::get_text_from_link;
....
for (idx, r) in res.iter().enumerate() {
println!("getting text for gutenberg idx: {}", r);
let links = cache.get_download_links(vec![*r])?;
for link in links {
let res = get_text_from_link(&settings, &link).await.unwrap();
}
上面的代码将按ID下载书籍文本并将其本地缓存,以便下次需要时更快。您还可以使用以下方式删除文本的标题
...
let res = get_text_from_link(&settings, &link).await.unwrap();
let only_content = strip_headers(res)
您可以在示例文件夹中找到更多信息。
为了更好的控制,您还可以设置GutenbergCacheSettings
- CacheFilename
- CacheUnpackDir
- CacheArchiveName
- CacheRDFDownloadLink
- TextFilesCacheFolder
//example
let mut settings = GutenbergCacheSettings::default();
settings.CacheFilename = "testcachename.db".to_string();
此库的Rust版本比Python版本更快,但增加的幅度并不是十倍,因为瓶颈可能是硬盘速度(解析)和下载速度(获取内容)。
标准查询字段
- language
- author
- title
- subject
- publisher
- bookshelve
- rights
- downloadlinkstype
上述查询字段用于形成过滤古腾堡书籍ID的json查询。查询函数仅返回古腾堡书籍ID,如果需要更多信息,需要使用缓存内部连接的本地查询。此连接使用rusqlite,sqlite表结构如下所示
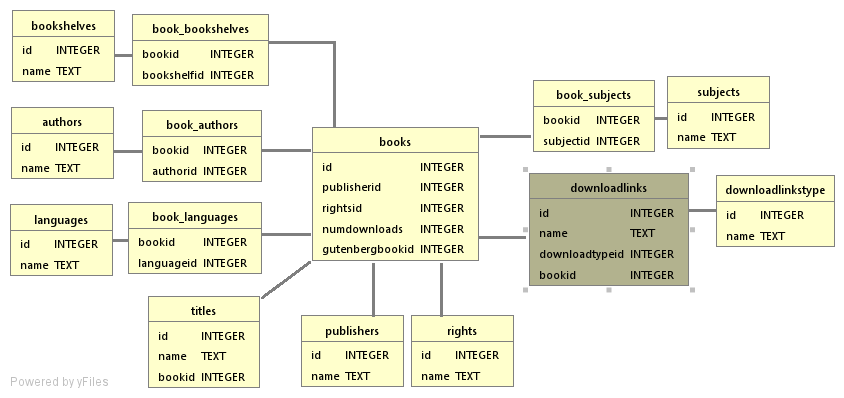
作为一个快速简便的例子,我们可以使用这个库来获取特定类别的英文书籍,并查看是否在其中找到某个特定时间(文学时钟的起点)。
// this is a helper function that converts a time (hours:minutes) into spoken english time
fn time_to_text(hour: usize, minute: usize) -> Result<String, Error> {
let nums = vec![
"zero",
"one",
"two",
"three",
"four",
"five",
"six",
"seven",
"eight",
"nine",
"ten",
"eleven",
"twelve",
"thirteen",
"fourteen",
"fifteen",
"sixteen",
"seventeen",
"eighteen",
"nineteen",
"twenty",
"twenty one",
"twenty two",
"twenty three",
"twenty four",
"twenty five",
"twenty six",
"twenty seven",
"twenty eight",
"twenty nine",
];
match minute {
0 => Ok(format!("{} o'clock", nums[hour])),
1 => Ok(format!("one minute past {}", nums[hour])),
59 => Ok(format!("one minute to {}", nums[hour])),
15 => Ok(format!("quarter past {}", nums[hour])),
30 => Ok(format!("half past {}", nums[hour])),
45 => Ok(format!("quarter to {}", nums[hour])),
_ => {
if minute <= 30 {
Ok(format!("{} minutes past {}", nums[minute], nums[hour]))
} else if minute > 30 {
Ok(format!(
"{} minutes to {}",
nums[60 - minute],
nums[(hour % 12) + 1]
))
} else {
Err(Error::InvalidResult(String::from("bad time")))
}
}
}
}
async fn exec() -> Result<(), Error> {
// let's do something fun in this example :
// - create the cache
// - download some english books from particular shelves
// - search for a certain time mention in all books
// - display the paragraph with the time mention
// here we create the cache settings with the default values
let settings = GutenbergCacheSettings::default();
// generate the sqlite cache (this will download, parse and create the db)
setup_sqlite(&settings, false, true).await?;
// we grab the newly create cache
let mut cache = SQLiteCache::get_cache(&settings).unwrap();
// we query the cache for our particular interests to get the book ids we need
let res = cache.query(&json!({
"language": "\"en\"",
"bookshelve": "'Romantic Fiction',
'Astounding Stories','Mystery Fiction','Erotic Fiction',
'Mythology','Adventure','Humor','Bestsellers, American, 1895-1923',
'Short Stories','Harvard Classics','Science Fiction','Gothic Fiction','Fantasy'",
}))?;
// we get the first 10 english books from above categories and concat them into a big pile of text
let max_number_of_texts = 10;
let mut big_string = String::from("");
for (idx, r) in res.iter().enumerate() {
println!("getting text for gutenberg idx: {}", r);
let links = cache.get_download_links(vec![*r])?;
for link in links {
let text = get_text_from_link(&settings, &link).await?;
let stripped_text = strip_headers(text);
big_string.push_str(&stripped_text);
break;
}
if idx >= max_number_of_texts {
break;
}
}
// write the file just so we have it
let output_filename = "big_file.txt";
if std::path::Path::new(output_filename).exists() {
// delete it if it already exists
fs::remove_file(output_filename)?;
}
fs::write(output_filename, &big_string)?;
// we get the time in words
let word_time = time_to_text(6, 0)?;
println!("The time is {}, now lets search the books", &word_time);
// we find the time in our pile of text and display the paragraph
let index = big_string.find(&word_time);
match index {
Some(found) => {
// find the whole paragraph where we have the time mentioned
let search_window_size = 1000;
let back_search = &big_string[found - search_window_size..found];
let start_paragraph = match back_search.rfind("\n\r") {
Some(x) => found + x - search_window_size,
None => found - search_window_size,
};
let end_search = &big_string[found..found + search_window_size];
let end_paragraph = match end_search.find("\n\r") {
Some(x) => x + found,
None => found + search_window_size,
};
let slice = &big_string[start_paragraph..end_paragraph];
print!(
"{}-{} [{}] {}",
start_paragraph, end_paragraph, found, slice
);
}
None => {
println!("could not find text in books")
}
}
Ok(())
}
依赖项
~33–47MB
~826K SLoC