2个版本
| 0.1.1 | 2024年6月18日 |
|---|---|
| 0.1.0 | 2024年6月18日 |
220 在 数据库接口
780KB
669 行
esdump-rs
快速将Elasticsearch或OpenSearch索引导出到对象存储 🚀
特性
- 超级快速
- 支持使用zstd或gzip压缩输出
- 原生支持AWS、Google Cloud和Azure的对象存储
- 支持过滤和选择特定字段
- 详细的进度输出和日志记录
- 作为单个小型静态二进制文件或Docker镜像提供
- 在Windows、Linux或MacOS上运行
- 用Rust编写 🦀
安装
版本:从发布页面获取预构建的可执行文件 发布页面
Docker: docker run ghcr.io/gitguardian/esdump-rs:v0.1.0
用法
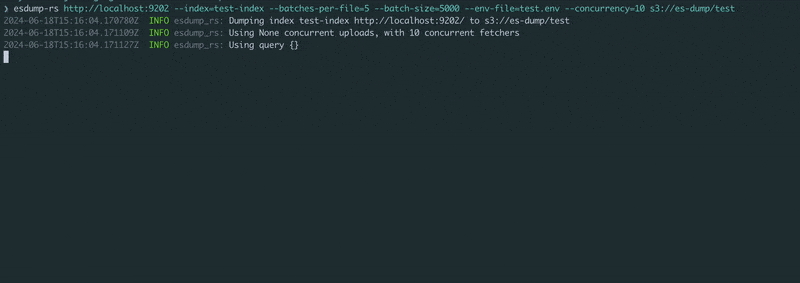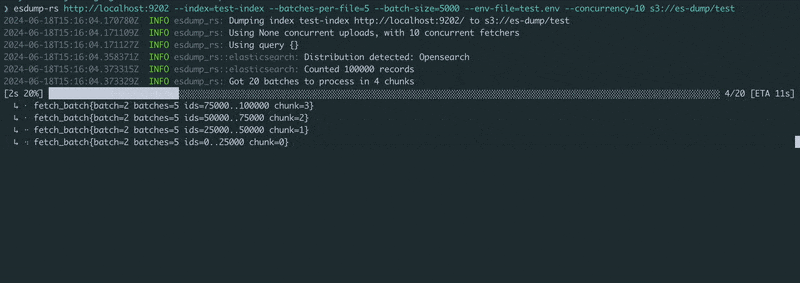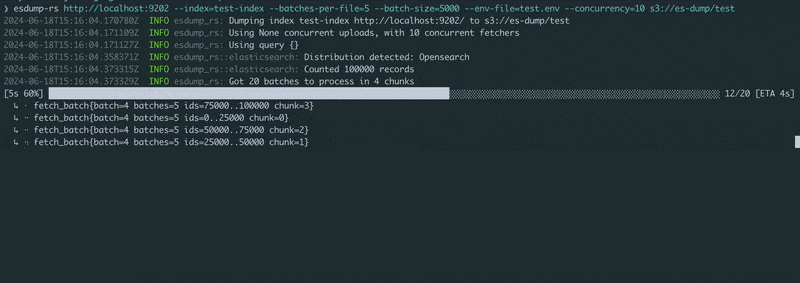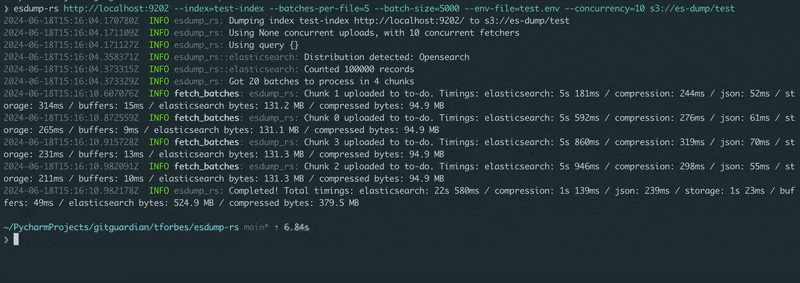
传递Elasticsearch或OpenSearch HTTP(s) URL和一个对象存储URL。在环境中设置凭据(请参阅 example.env),然后运行!
$ esdump-rs https://:9200 s3://es-dump/test/ \
--index=test-index \
--batches-per-file=5 \
--batch-size=5000 \
--concurrency=10
可以将批量大小和并发性等设置作为标志
Usage: esdump-rs [OPTIONS] --index <INDEX> --concurrency <CONCURRENCY> --batch-size <BATCH_SIZE> --batches-per-file <BATCHES_PER_FILE> <ELASTICSEARCH_URL> <OUTPUT_LOCATION>
Arguments:
<ELASTICSEARCH_URL> Elasticsearch cluster to dump
<OUTPUT_LOCATION> Location to write results. Can be a file://, s3:// or gs:// URL
Options:
-i, --index <INDEX>
Index to dump
-c, --concurrency <CONCURRENCY>
Number of concurrent requests to use
-l, --limit <LIMIT>
Limit the total number of records returned
-b, --batch-size <BATCH_SIZE>
Number of records in each batch
--batches-per-file <BATCHES_PER_FILE>
Number of batches to write per file
-q, --query <QUERY>
A file path containing a query to execute while dumping
-f, --field <FIELD>
Specific fields to fetch
--compression <COMPRESSION>
Compress the output files [default: zstd] [possible values: gzip, zstd]
--concurrent-uploads <CONCURRENT_UPLOADS>
Max chunks to concurrently upload *per task*
--upload-size <UPLOAD_SIZE>
Size of each uploaded [default: 15MB]
-d, --distribution <DISTRIBUTION>
Distribution of the cluster [possible values: elasticsearch, opensearch]
--env-file <ENV_FILE>
Distribution of the cluster [default: .env]
-h, --help
Print help
-V, --version
Print version
依赖项
~25–39MB
~629K SLoC