1 个不稳定版本
| 新 0.1.0 | 2024 年 8 月 13 日 |
|---|
141 在 嵌入式开发 中
111 每月下载量
5.5MB
2.5K SLoC
包含 (Mach-o exe, 38KB) heatshrink
嵌入式 Heatshrink
此库是对 C 库 heatshrink 的重写/移植。它具有与原始库相同的 sink/poll API,但使用 Rust 编写。它通过针对推送位和数组操作的优化而更快。它修复了在模糊测试期间发现的某些错误。
主要功能
- 低内存使用(低至 50 字节)适用于少于 50 字节的一些情况,以及适用于小于 300 字节的大多数通用情况。
- 增量、有限的 CPU 使用您可以用任意小的数据块处理输入数据。这在硬实时环境中是一个有用的特性。
用法
以下是从库中提取的示例,它使用流式 API 进行一次性压缩。如果想要连续流式传输,则重复使用相同的 HeatshrinkEncoder 实例。同样,HeatshrinkDecoder 也一样。
#[inline]
fn read_in(stdin: &mut impl Read, buf: &mut [u8]) -> usize {
stdin.read(buf).expect("Failed to read from stdin")
}
#[inline]
fn write_out(stdout: &mut impl Write, data: &[u8]) {
stdout.write_all(data).expect("Failed to write to stdout");
}
pub fn encode(window_sz2: u8, lookahead_sz2: u8, stdin: &mut impl Read, stdout: &mut impl Write) {
let mut encoder = HeatshrinkEncoder::new(window_sz2, lookahead_sz2)
.expect("Failed to create encoder");
const WORK_SIZE_UNIT: usize = 1024; // Aritrary size, just > 0
let mut buf = [0; WORK_SIZE_UNIT];
let mut scratch = [0; WORK_SIZE_UNIT * 2];
// Sink all bytes from the input buffer
let mut not_empty = false;
loop {
let read_len = read_in(stdin, &mut buf);
not_empty |= read_len > 0;
if read_len == 0 {
break;
}
let mut read_data = &buf[..read_len];
while !read_data.is_empty() {
let sink_res = encoder.sink(read_data);
match sink_res {
HSESinkRes::Ok(bytes_sunk) => {
read_data = &read_data[bytes_sunk..];
}
_ => unreachable!(),
}
loop {
match encoder.poll(&mut scratch) {
HSEPollRes::Empty(sz) => {
write_out(stdout, &scratch[..sz]);
break;
}
HSEPollRes::More(sz) => {
write_out(stdout, &scratch[..sz]);
}
HSEPollRes::ErrorMisuse | HSEPollRes::ErrorNull => unreachable!(),
}
}
}
}
if !not_empty {
return;
}
// Poll out the remaining bytes
loop {
match encoder.finish() {
HSEFinishRes::Done => {
break;
}
HSEFinishRes::More => {}
HSEFinishRes::ErrorNull => unreachable!(),
}
loop {
match encoder.poll(&mut scratch) {
HSEPollRes::Empty(sz) => {
write_out(stdout, &scratch[..sz]);
break;
}
HSEPollRes::More(sz) => {
write_out(stdout, &scratch[..sz]);
}
HSEPollRes::ErrorMisuse | HSEPollRes::ErrorNull => unreachable!(),
}
}
}
}
压缩性能
窗口大小 window_size = 1 << window_size2 控制回溯和前瞻缓冲区的大小。它决定了分配大小和 CPU 使用率。前瞻大小 lookahead_size = 1 << lookahead_size2 控制匹配的最大长度。窗口大小和前瞻大小的总和决定了用于替换匹配的位数,因此更高的前瞻大小并不总是意味着更好的压缩。
对于内存分配,这里是一些为差分压缩的传感器数据选择的实用值
const HEATSHRINK_WINDOW_SZ2: u8 = 11; // dramatically affects both heap and cpu usage
const HEATSHRINK_LOOKAHEAD_SZ2: u8 = 3; // barely affects anything, longer matches are rare in sensor data
const HEATSHRINK_INPUT_BUFFER_SIZE: u16 = 500; // Small enough that we don't fragment the heap, large enough that most payloads fit in one or two chunks
const HEATSHRINK_ALLOCATED_SIZE: usize = (2 << HEATSHRINK_WINDOW_SZ2) + (2 << (HEATSHRINK_WINDOW_SZ2 + 1)); // Input buffer plus search index
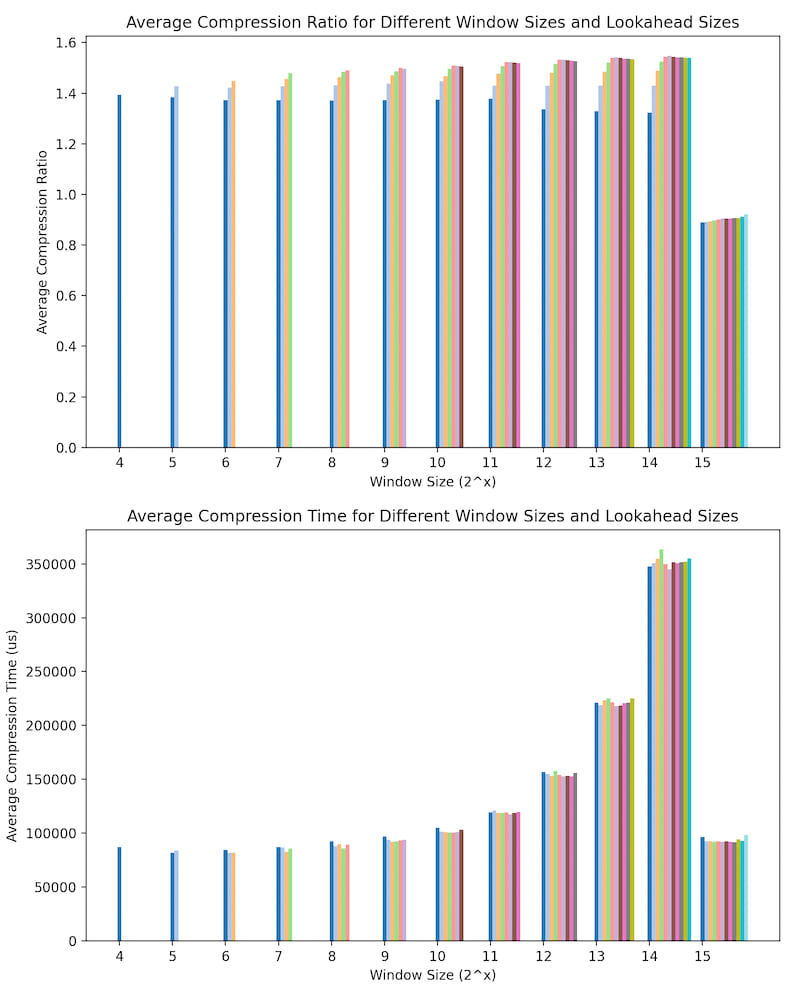
对于一些实际的差分压缩加速度计数据,以下是使用窗口大小 2=4 和前瞻大小 2=3 的最小值绘制的压缩时间和比率。前瞻大小 2 有效范围从 3 到窗口大小 2 - 1。压缩比率是原始大小与压缩大小的比率。压缩时间是压缩数据的微秒数。
CLI 二进制文件
有一个简单的CLI二进制文件。使用以下命令安装:cargo install --path . --features std。
它从stdin读取并写入stdout。以下是一个示例
hsz < input.txt > output.txt.hs
解压缩
hsz < output.txt.hs > output.txt
往返
hsz < input.txt | hsz -d > output.txt
diff input.txt output.txt
基准测试
hsz并不是最好的;它是基于LVSS的折衷方案。它在具有重复的数据上表现相当不错,但在压缩数据(如pngs)上表现不佳。以下是./bench.sh的一些结果:
| 工具 | 文件 | 平均压缩比率 | 平均压缩时间 | 平均解压缩时间 |
|---|---|---|---|---|
| gzip | tsz-compressed-data.bin | 0.55 | 0.042秒 | 0秒 |
| bzip2 | tsz-compressed-data.bin | 0.55 | 0.224秒 | 0.056秒 |
| xz | tsz-compressed-data.bin | 0.55 | 0.206秒 | 0.050秒 |
| zstd | tsz-compressed-data.bin | 0.55 | 0秒 | 0.002秒 |
| hsz | tsz-compressed-data.bin | 0.66 | 0.038秒 | 0.010秒 |
| gzip | fuzz/index.html | 0.10 | 0.010秒 | 0秒 |
| bzip2 | fuzz/index.html | 0.05 | 0.070秒 | 0.010秒 |
| xz | fuzz/index.html | 0.06 | 0.136秒 | 0秒 |
| zstd | fuzz/index.html | 0.08 | 0秒 | 0秒 |
| hsz | fuzz/index.html | 0.20 | 0.010秒 | 0秒 |
| gzip | average-compression-tsz-data.png | 0.92 | 0.040秒 | 0秒 |
| bzip2 | average-compression-tsz-data.png | 0.94 | 0.154秒 | 0.080秒 |
| xz | average-compression-tsz-data.png | 0.88 | 0.260秒 | 0.080秒 |
| zstd | average-compression-tsz-data.png | 0.93 | 0.006秒 | 0秒 |
| hsz | average-compression-tsz-data.png | 1.05 | 0.040秒 | 0.020秒 |
测试和模糊测试
测试运行时间非常长,因为原始库非常接近u16的最大范围。测试编译了几个包含许多有效配置排列的小文件。
模糊测试分为两个选项
./fuzz.sh 1000000- 这将生成一些文件,使用dd生成,然后用二进制文件进行往返压缩/解压缩