1 个不稳定版本
| 0.0.7 | 2024年6月12日 |
|---|
#179 在 科学
33KB
642 行
Edge Python API
连接到 dRISK Edge 的 API。
有用的 Edge 链接
一些对新边缘用户有用的链接
- 登录到边缘: demo.drisk.ai
- 文档: demo.drisk.ai/docs
安装
pip install drisk_api
基本用法
该 API 支持在图上执行创建/读取/更新/删除操作的基本构建块。例如
from drisk_api import GraphClient
token = "<edge_auth_token>"
# create or conntect to a graph
new_graph = GraphClient.create_graph("a graph", token)
graph = GraphClient("graph_id", token)
# make a new node
node_id = graph.create_node(label="a node")
# get a node
node = graph.get_node(node_id)
# get the successors of the node
successors = graph.get_successors(node_id)
# update the node
graph.update_node(node_id, label="new label", size=3)
# add edges in batch
with graph.batch():
graph.add_edge(node, other, weight=5.)
更多示例
我们可以使用这些构建块来创建我们最感兴趣的任何图。下面是一些示例
维基百科爬虫
在这个示例中,我们将抓取给定维基百科页面的主 URL 链接,并从中创建一个图。
大部分代码将利用 wikipedia api,并不特别重要。更有趣的是,我们如何使用 api 将对应的信息转换为图,然后在边缘中探索它。
首先加载相关模块
import wikipedia
from wikipedia import PageError, DisambiguationError, search, WikipediaPage
from tqdm import tqdm
from drisk_api import GraphClient
让我们定义一些辅助函数,这些函数将帮助我们为给定页面创建维基百科 URL 的图。需要注意的是主要函数 wiki_scraper,它将找到给定页面中的“最重要的”链接并将它们添加到图中,链接回原始页面。它将对每个节点递归执行此操作,直到达到终止条件(例如,最大递归深度)。
def find_page(title):
"""Find the wikipedia page."""
results, suggestion = search(title, results=1, suggestion=True)
try:
title = results[0] or suggestion
page = WikipediaPage(title, redirect=True, preload=False)
except IndexError:
raise PageError(title)
return page
def top_links(links, text, top_n):
"""Find most important links in a wikipedia page."""
link_occurrences = {}
for link in links:
link_occurrences[link] = text.lower().count(link.lower())
sorted_links = sorted(link_occurrences.items(), key=lambda x: x[1], reverse=True)
top_n_relevant_links = [link for link, count in sorted_links[:top_n]]
return top_n_relevant_links
def wiki_scraper(
graph,
page_node,
page_name,
string_cache,
visited_pages,
max_depth=3,
current_depth=0,
max_links=10,
first_depth_max_links=100,
):
try:
page = find_page(title=page_name)
except (DisambiguationError, PageError) as e:
return
# add the url to the page_node (and make sure label is right)
graph.update_node(page_node, label=page_name, url=page.url)
if page_name in visited_pages or current_depth >= max_depth:
return
links = top_links(page.links, page.content, first_depth_max_links if current_depth == 0 else max_links)
if current_depth == 0:
tqdm_bar = tqdm(total=len(links), desc="wiki scraping")
for link in links:
if current_depth == 0:
tqdm_bar.update(1)
# see if we have already visted the page
new_page_node = None
if link in string_cache:
new_page_node = string_cache[link]
else:
# if we haven't add a new node and add to cache
new_page_node = graph.create_node(label=link)
string_cache[link] = new_page_node
# link this original page to the new one
graph.create_edge(page_node, new_page_node, 1.)
# repeat for new link
wiki_scraper(
graph,
new_page_node,
link,
string_cache,
visted_pages,
current_depth=current_depth + 1,
max_links=max_links,
first_depth_max_links=first_depth_max_links,
)
visited_pages.add(page_name)
然后我们可以连接到我们的图(或创建一个新图)
TOKEN = "<edge_auth_token>"
graph_id = "graph_id"
home_view = "view_id"
g = GraphClient(graph_id, TOKEN)
并运行爬虫
page_name = "Napoleon"
string_cache = {}
visted_pages = set()
page_node = g.create_node(label=page_name)
g.add_nodes_to_view(home_view, [page_node], [(0., 0.)])
with g.batch():
wiki_scraper(
g,
page_node,
page_name,
string_cache,
visted_pages,
max_depth=3,
current_depth=0,
max_links=3,
first_depth_max_links=2,
)
然后我们可以前往边缘与图交互
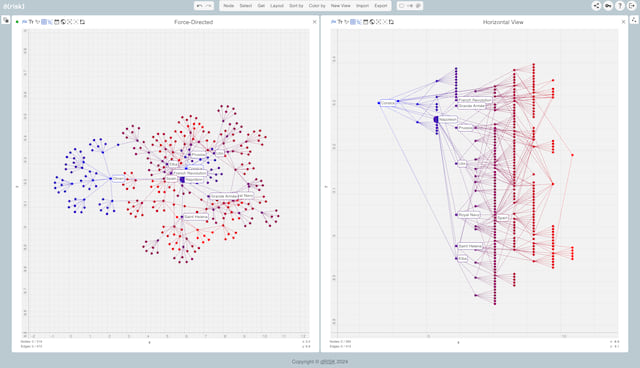
)))
依赖关系
~2.8–9.5MB
~87K SLoC