1 个不稳定版本
| 0.1.0 | 2024 年 8 月 7 日 |
|---|
#237 在 算法 中
111 每月下载量
27MB
1.5K SLoC
.lr
用于教育目的的 LR(1) 解析器生成器和可视化工具。
目录
- 什么是 LR(1) 解析器?
- 为什么你要制作这个?
- 我如何在 gif 中使用 CLI?
- 我可以将其作为独立的库使用吗?
- 它是如何工作的?
- 有任何基准测试吗?
- 我可以修改它吗?
- 你在创建此项目时使用了哪些资源?
- 它的许可方式是什么?
什么是 LR(1) 解析器?
LR(1) 解析器 是一种 自底向上解析器,用于解析 上下文无关语言 的子集。
1 表示解析器在做出解析决策时将使用单个前瞻标记。
LR(1) 解析器功能强大,因为它们可以解析广泛的上下文无关语言,包括大多数编程语言!
为什么你要制作这个?
为了学习和帮助他人学习!该项目允许你可视化 LR(1) 解析器,从构建到解析,这使理解它们的工作方式变得更容易。
我如何在 gif 中使用 CLI?
如果你想用 dotlr 来可视化解析器构建和不同语法的逐步解析,你可以使用 crate 的主可执行文件。
安装
你可以从 crates.io 安装 dotlr CLI。
cargo install dotlr
用法
将以下内容粘贴到名为 grammar.lr 的文件中
P -> E
E -> E '+' T
E -> T
T -> %id '(' E ')'
T -> %id
%id -> /[A-Za-z][A-Za-z0-9]+/
使用语法文件和输入运行 dotlr CLI
dotlr grammar.lr "foo(bar + baz)"
它将打印
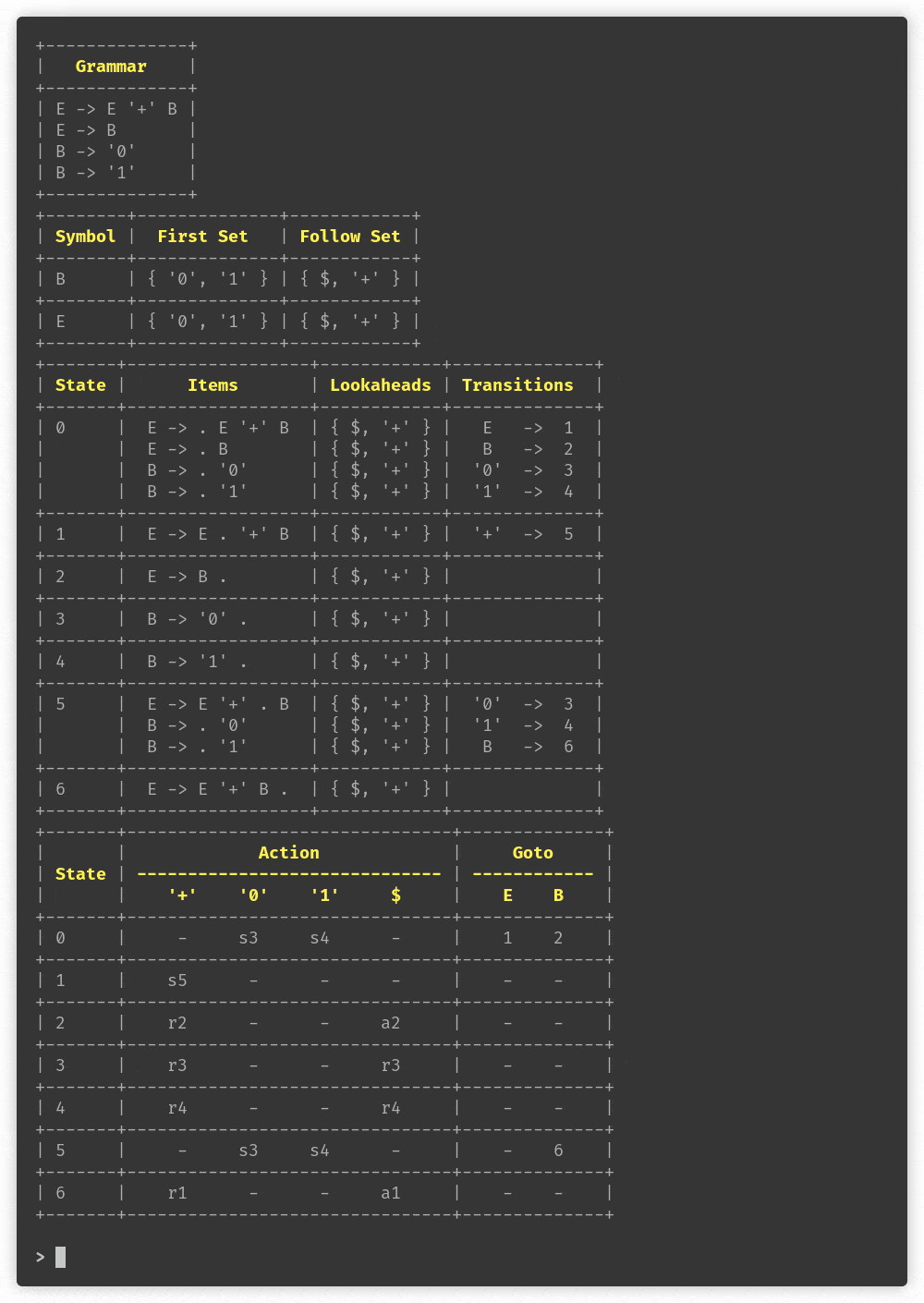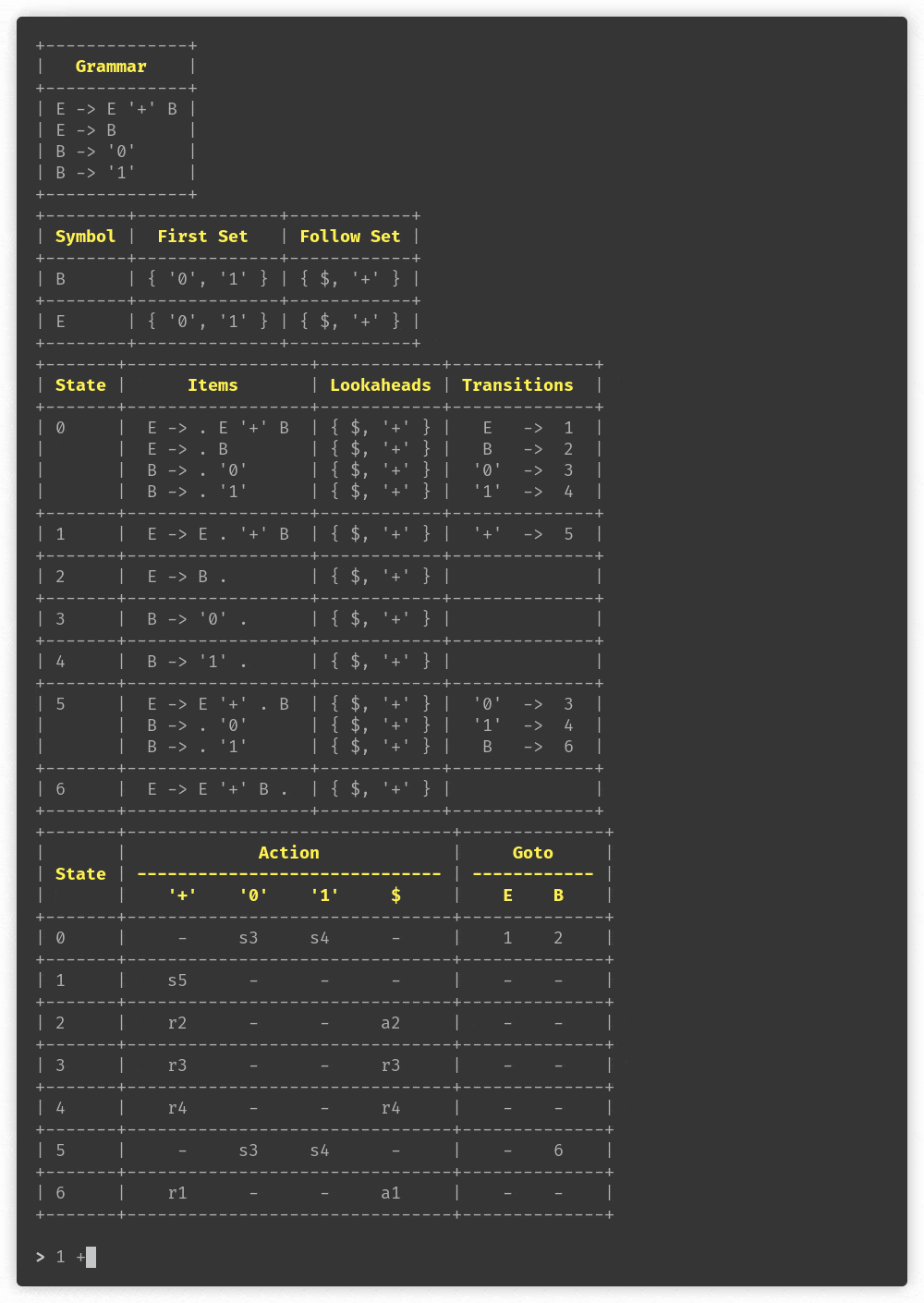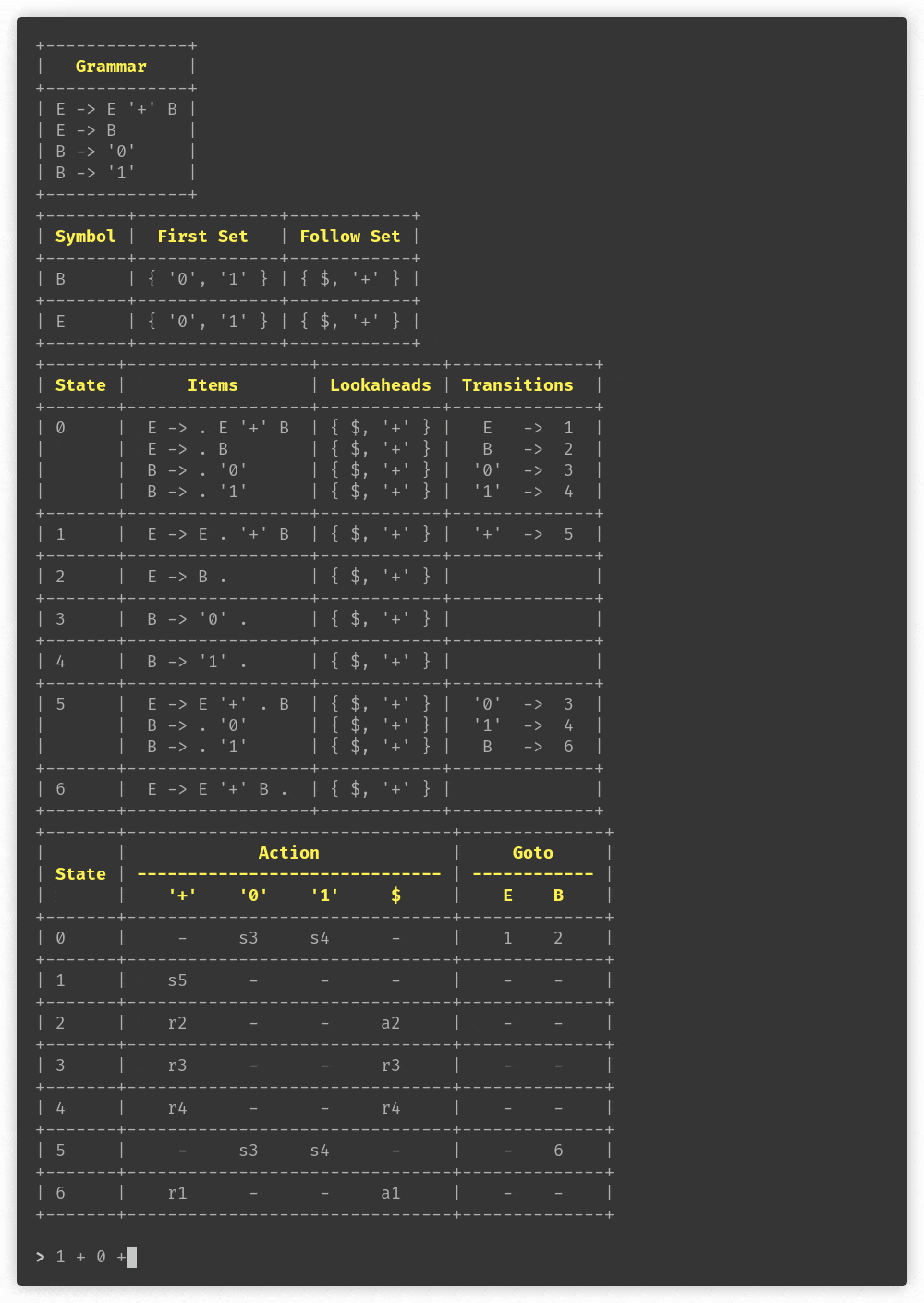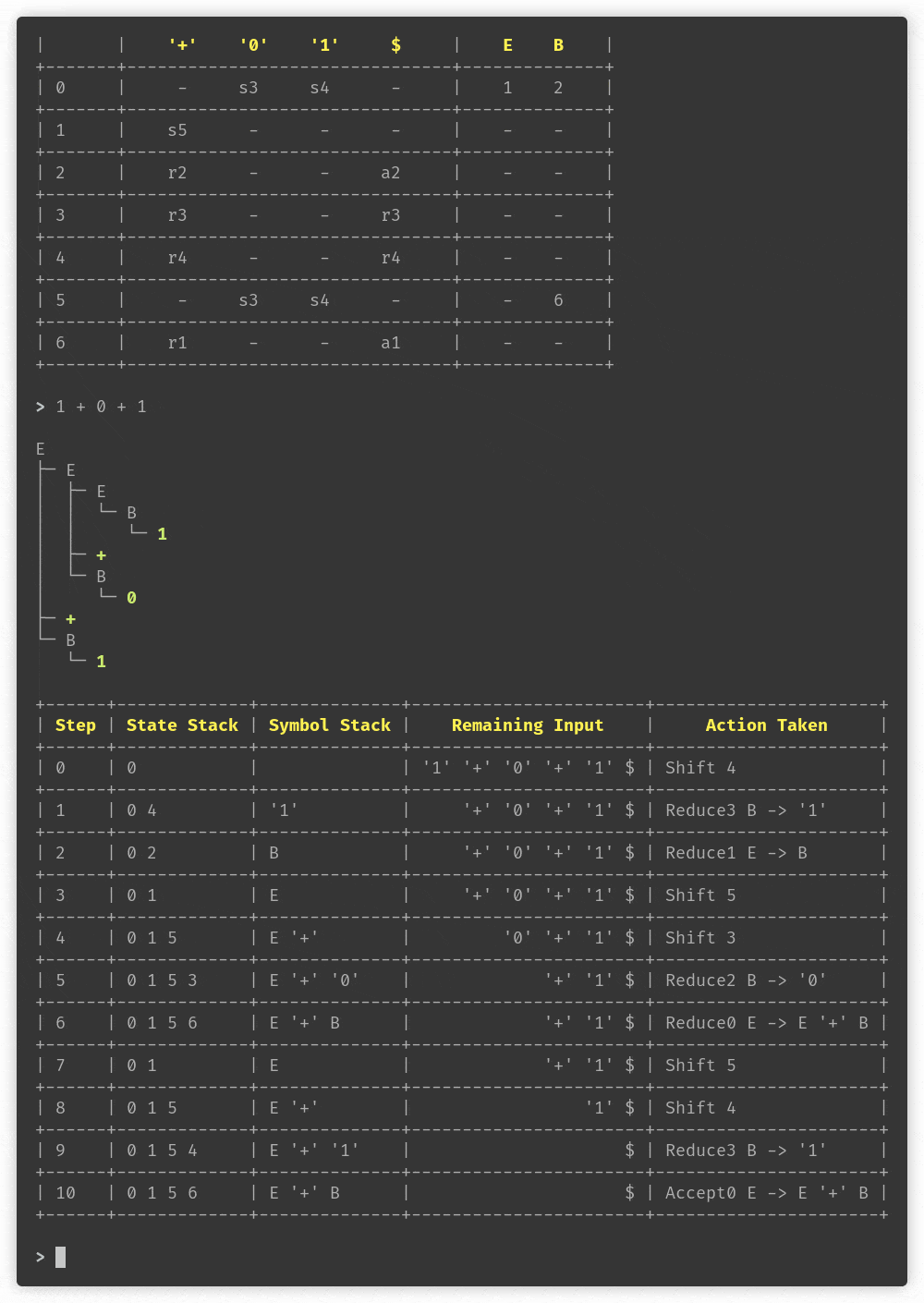
+--------------------------------+
| Grammar |
+--------------------------------+
| P -> E |
| E -> E '+' T |
| E -> T |
| T -> %id '(' E ')' |
| T -> %id |
| |
| %id -> /^[A-Za-z][A-Za-z0-9]+/ |
+--------------------------------+
+--------+-----------+-----------------+
| Symbol | First Set | Follow Set |
+--------+-----------+-----------------+
| T | { %id } | { $, '+', ')' } |
+--------+-----------+-----------------+
| E | { %id } | { $, '+', ')' } |
+--------+-----------+-----------------+
| P | { %id } | { $ } |
+--------+-----------+-----------------+
+-------+------------------------+--------------+---------------+
| State | Items | Lookaheads | Transitions |
+-------+------------------------+--------------+---------------+
| 0 | P -> . E | { $ } | E -> 1 |
| | E -> . E '+' T | { $, '+' } | T -> 2 |
| | E -> . T | { $, '+' } | %id -> 3 |
| | T -> . %id '(' E ')' | { $, '+' } | |
| | T -> . %id | { $, '+' } | |
+-------+------------------------+--------------+---------------+
| 1 | P -> E . | { $ } | '+' -> 14 |
| | E -> E . '+' T | { $, '+' } | |
+-------+------------------------+--------------+---------------+
| 2 | E -> T . | { $, '+' } | |
+-------+------------------------+--------------+---------------+
| 3 | T -> %id . '(' E ')' | { $, '+' } | '(' -> 4 |
| | T -> %id . | { $, '+' } | |
+-------+------------------------+--------------+---------------+
| 4 | T -> %id '(' . E ')' | { $, '+' } | E -> 5 |
| | E -> . E '+' T | { ')', '+' } | %id -> 6 |
| | E -> . T | { ')', '+' } | T -> 9 |
| | T -> . %id '(' E ')' | { ')', '+' } | |
| | T -> . %id | { ')', '+' } | |
+-------+------------------------+--------------+---------------+
| 5 | T -> %id '(' E . ')' | { $, '+' } | '+' -> 11 |
| | E -> E . '+' T | { ')', '+' } | ')' -> 13 |
+-------+------------------------+--------------+---------------+
| 6 | T -> %id . '(' E ')' | { ')', '+' } | '(' -> 7 |
| | T -> %id . | { ')', '+' } | |
+-------+------------------------+--------------+---------------+
| 7 | T -> %id '(' . E ')' | { ')', '+' } | %id -> 6 |
| | E -> . E '+' T | { ')', '+' } | E -> 8 |
| | E -> . T | { ')', '+' } | T -> 9 |
| | T -> . %id '(' E ')' | { ')', '+' } | |
| | T -> . %id | { ')', '+' } | |
+-------+------------------------+--------------+---------------+
| 8 | T -> %id '(' E . ')' | { ')', '+' } | ')' -> 10 |
| | E -> E . '+' T | { ')', '+' } | '+' -> 11 |
+-------+------------------------+--------------+---------------+
| 9 | E -> T . | { ')', '+' } | |
+-------+------------------------+--------------+---------------+
| 10 | T -> %id '(' E ')' . | { ')', '+' } | |
+-------+------------------------+--------------+---------------+
| 11 | E -> E '+' . T | { ')', '+' } | %id -> 6 |
| | T -> . %id '(' E ')' | { ')', '+' } | T -> 12 |
| | T -> . %id | { ')', '+' } | |
+-------+------------------------+--------------+---------------+
| 12 | E -> E '+' T . | { ')', '+' } | |
+-------+------------------------+--------------+---------------+
| 13 | T -> %id '(' E ')' . | { $, '+' } | |
+-------+------------------------+--------------+---------------+
| 14 | E -> E '+' . T | { $, '+' } | %id -> 3 |
| | T -> . %id '(' E ')' | { $, '+' } | T -> 15 |
| | T -> . %id | { $, '+' } | |
+-------+------------------------+--------------+---------------+
| 15 | E -> E '+' T . | { $, '+' } | |
+-------+------------------------+--------------+---------------+
+-------+---------------------------------------+----------------------+
| | Action | Goto |
| State | ------------------------------------- | -------------------- |
| | '+' '(' ')' %id $ | P E T |
+-------+---------------------------------------+----------------------+
| 0 | - - - s3 - | - 1 2 |
+-------+---------------------------------------+----------------------+
| 1 | s14 - - - a1 | - - - |
+-------+---------------------------------------+----------------------+
| 2 | r3 - - - r3 | - - - |
+-------+---------------------------------------+----------------------+
| 3 | r5 s4 - - r5 | - - - |
+-------+---------------------------------------+----------------------+
| 4 | - - - s6 - | - 5 9 |
+-------+---------------------------------------+----------------------+
| 5 | s11 - s13 - - | - - - |
+-------+---------------------------------------+----------------------+
| 6 | r5 s7 r5 - - | - - - |
+-------+---------------------------------------+----------------------+
| 7 | - - - s6 - | - 8 9 |
+-------+---------------------------------------+----------------------+
| 8 | s11 - s10 - - | - - - |
+-------+---------------------------------------+----------------------+
| 9 | r3 - r3 - - | - - - |
+-------+---------------------------------------+----------------------+
| 10 | r4 - r4 - - | - - - |
+-------+---------------------------------------+----------------------+
| 11 | - - - s6 - | - - 12 |
+-------+---------------------------------------+----------------------+
| 12 | r2 - r2 - - | - - - |
+-------+---------------------------------------+----------------------+
| 13 | r4 - - - r4 | - - - |
+-------+---------------------------------------+----------------------+
| 14 | - - - s3 - | - - 15 |
+-------+---------------------------------------+----------------------+
| 15 | r2 - - - r2 | - - - |
+-------+---------------------------------------+----------------------+
> foo(bar + baz)
P
└─ E
└─ T
├─ foo
├─ (
├─ E
│ ├─ E
│ │ └─ T
│ │ └─ bar
│ ├─ +
│ └─ T
│ └─ baz
└─ )
+------+---------------+-------------------+---------------------------+----------------------------+
| Step | State Stack | Symbol Stack | Remaining Input | Action Taken |
+------+---------------+-------------------+---------------------------+----------------------------+
| 0 | 0 | | %id '(' %id '+' %id ')' $ | Shift 3 |
+------+---------------+-------------------+---------------------------+----------------------------+
| 1 | 0 3 | %id | '(' %id '+' %id ')' $ | Shift 4 |
+------+---------------+-------------------+---------------------------+----------------------------+
| 2 | 0 3 4 | %id '(' | %id '+' %id ')' $ | Shift 6 |
+------+---------------+-------------------+---------------------------+----------------------------+
| 3 | 0 3 4 6 | %id '(' %id | '+' %id ')' $ | Reduce4 T -> %id |
+------+---------------+-------------------+---------------------------+----------------------------+
| 4 | 0 3 4 9 | %id '(' T | '+' %id ')' $ | Reduce2 E -> T |
+------+---------------+-------------------+---------------------------+----------------------------+
| 5 | 0 3 4 5 | %id '(' E | '+' %id ')' $ | Shift 11 |
+------+---------------+-------------------+---------------------------+----------------------------+
| 6 | 0 3 4 5 11 | %id '(' E '+' | %id ')' $ | Shift 6 |
+------+---------------+-------------------+---------------------------+----------------------------+
| 7 | 0 3 4 5 11 6 | %id '(' E '+' %id | ')' $ | Reduce4 T -> %id |
+------+---------------+-------------------+---------------------------+----------------------------+
| 8 | 0 3 4 5 11 12 | %id '(' E '+' T | ')' $ | Reduce1 E -> E '+' T |
+------+---------------+-------------------+---------------------------+----------------------------+
| 9 | 0 3 4 5 | %id '(' E | ')' $ | Shift 13 |
+------+---------------+-------------------+---------------------------+----------------------------+
| 10 | 0 3 4 5 13 | %id '(' E ')' | $ | Reduce3 T -> %id '(' E ')' |
+------+---------------+-------------------+---------------------------+----------------------------+
| 11 | 0 2 | T | $ | Reduce2 E -> T |
+------+---------------+-------------------+---------------------------+----------------------------+
| 12 | 0 1 | E | $ | Accept0 P -> E |
+------+---------------+-------------------+---------------------------+----------------------------+
如果你省略了输入,你还可以进入 REPL 模式
dotlr grammar.lr
我可以将其作为独立的库使用吗?
是的,你可以从 crates.io 依赖 dotlr crate。
设置
将以下内容粘贴到你的 dependencies 部分的 Cargo.toml
dotlr = { version = "0.1", default-features = false }
示例
以下是一个基本示例,展示了 dotlr crate 的主要操作
use dotlr::{
Grammar,
Parser,
ParserError,
};
const GRAMMAR: &str = r#"
P -> E
E -> E '+' T
E -> T
T -> %id '(' E ')'
T -> %id
%id -> /[A-Za-z][A-Za-z0-9]+/
"#;
const INPUT: &str = r#"
foo(bar + baz)
"#;
fn main() {
let grammar = match Grammar::parse(GRAMMAR.trim()) {
Ok(grammar) => grammar,
Err(error) => {
eprintln!("grammar error: {}", error);
return;
}
};
let parser = match Parser::new(grammar) {
Ok(parser) => parser,
Err(error) => {
eprintln!("parser error: {}", error);
if let ParserError::Conflict { parser, .. } = error {
parser.dump();
}
return;
}
};
let tokens = match parser.tokenize(INPUT.trim()) {
Ok(tokens) => tokens,
Err(error) => {
eprintln!("tokenization error: {}", error);
return;
}
};
let (parse_trace, parse_tree) = match parser.trace(tokens) {
Ok(result) => result,
Err(error) => {
eprintln!("tokenization error: {}", error);
return;
}
};
parser.dump();
println!();
parse_tree.dump();
println!();
parse_trace.dump(parser.grammar());
}
它是如何工作的?
让我们逐步构建以下语法的解析器
E -> E '+' F
E -> F
F -> F '*' T
F -> T
T -> %b
%b -> /[0-1]/
然后逐步解释以下输入的解析步骤
1 + 0 * 1
开始之前的一些注意事项
$代表输入标记的结束- 在
dotlr中,不支持可以扩展为空字符串的符号,这简化了下面的解释(即没有像S ->这样的规则)
1) 解析语法
首先,我们需要将语法字符串解析为一个可以处理的语法对象。
语法对象将包含
-
符号(HashSet)
- 语法中的符号集合
(例如,{ E, F, T })
- 语法中的符号集合
-
起始符号(Symbol)
- 要解析的符号
(例如,E)
- 要解析的符号
-
常量标记(HashSet)
- 语法中的常量标记集合
(例如,{ '+', '*' })
- 语法中的常量标记集合
-
正则表达式(HashMap
- 正则表达式标记到相应编译后正则表达式的映射
(例如,{ b -> /[0-1]/ })
- 正则表达式标记到相应编译后正则表达式的映射
-
规则(Vec)
- 语法中的规则列表
(例如,[ E -> E '+' F, E -> F, ... ])
- 语法中的规则列表
这通过一个简单的手写解析器在src/grammar.rs中完成。
2) 计算FIRST集合
现在,我们需要根据以下约束为语法中的每个符号计算一个标记集合
- 对于每个
token ∈ FIRST(Symbol),以下条件至少有一个必须成立符号->标记...∈ 语法.规则Symbol -> 另一个符号 ... ∈ 语法.rules并且
标记 ∈FIRST(另一个符号)
至于实现,这里是一个类似Python的伪代码,用于计算FIRST集合的算法
# Start with FIRST(all_symbols) = {}
first_sets = {}
# Iterate until no more changes
while first_sets.has_changed():
# Iterate over the rules of the grammar
for rule in grammar:
# If pattern of the rule starts with a token
if rule.pattern[0].is_token:
# S -> '+' ... <==> S can start with '+'
# --------------------------------------
# Add the matching token to the FIRST set of the symbol of the rule
first_sets[rule.symbol].add(rule.pattern[0])
# If pattern of the rule starts with a symbol
elif rule.pattern[0].is_symbol:
# S -> E ... <==> S can start with anything E can start with
# ----------------------------------------------------------
# Add every token in the FIRST set of the matching symbol
# to the FIRST set of the symbol of the rule
first_sets[rule.symbol].extend(first_sets[rule.pattern[0]])
这通过src/tables.rs来完成。
示例语法的FIRST集合
+--------+-----------+
| Symbol | First Set |
+--------+-----------+
| T | { %b } |
+--------+-----------+
| F | { %b } |
+--------+-----------+
| E | { %b } |
+--------+-----------+
3) 计算FOLLOW集合
接下来,我们需要根据以下约束为语法中的每个符号计算另一个标记集合
- 对于每个
token ∈ FOLLOW(Symbol),以下条件至少有一个必须成立-
Symbol == 语法.start_symbol并且
标记== $ -
任何内容-> ...符号标记...∈ 语法.规则 -
Anything -> ... 符号 另一个符号 ... ∈ 语法.rules和
标记 ∈FIRST(另一个符号) -
符号 -> ... 另一个符号 ∈ 语法.rules和
标记 ∈FOLLOW(另一个符号)
-
关于实现,下面是计算FOLLOW集的算法的类似Python的伪代码
# Start with just FOLLOW(grammar.start_symbol) = { $ }
follow_sets = { grammar.start_symbol: { $ } }
# Iterate until no more changes
while follow_sets.has_changed():
# Iterate over the rules of the grammar
for rule in grammar:
# Iterate over the 2-windows of the pattern of the rule
for i in range(len(rule.pattern) - 1):
# If the first atomic pattern is a symbol
if rule.pattern[i].is_symbol:
# And if the second atomic pattern is a token
if rule.pattern[i + 1].is_token:
# S -> ... E '+' ... <==> E can follow '+'
# ----------------------------------------
# Add the matching token to the FOLLOW set of the matching symbol
follow_sets[rule.pattern[i]].add(rule.pattern[i + 1])
# Or if the second atomic pattern is a symbol
elif rule.pattern[i + 1].is_symbol:
# S -> ... E F ... <==> E can follow anything F can start with
# ------------------------------------------------------------
# Add every token in the FIRST set of the second symbol
# to the FOLLOW set of the first symbol
follow_sets[rule.pattern[i]].extend(first_sets[rule.pattern[i + 1]])
# If pattern of ends with a symbol
if rule.pattern[-1].is_symbol:
# S -> ... E <==> S can follow anything E can follow
# --------------------------------------------------
# Add every token in the FOLLOW set of the matching symbol
# to the FOLLOW set of the symbol of the rule
follow_sets[rule.symbol].extend(follow_sets[rule.patten[-1]])
这通过src/tables.rs来完成。
示例语法的FOLLOW集
+--------+-----------------+
| Symbol | Follow Set |
+--------+-----------------+
| T | { $, '+', '*' } |
+--------+-----------------+
| F | { $, '+', '*' } |
+--------+-----------------+
| E | { $, '+' } |
+--------+-----------------+
4) 构建LR(1)自动机
现在是时候为语法构建LR(1)自动机了。
这里是不同语法的LR(1)自动机的示意图,以便了解LR(1)自动机是什么
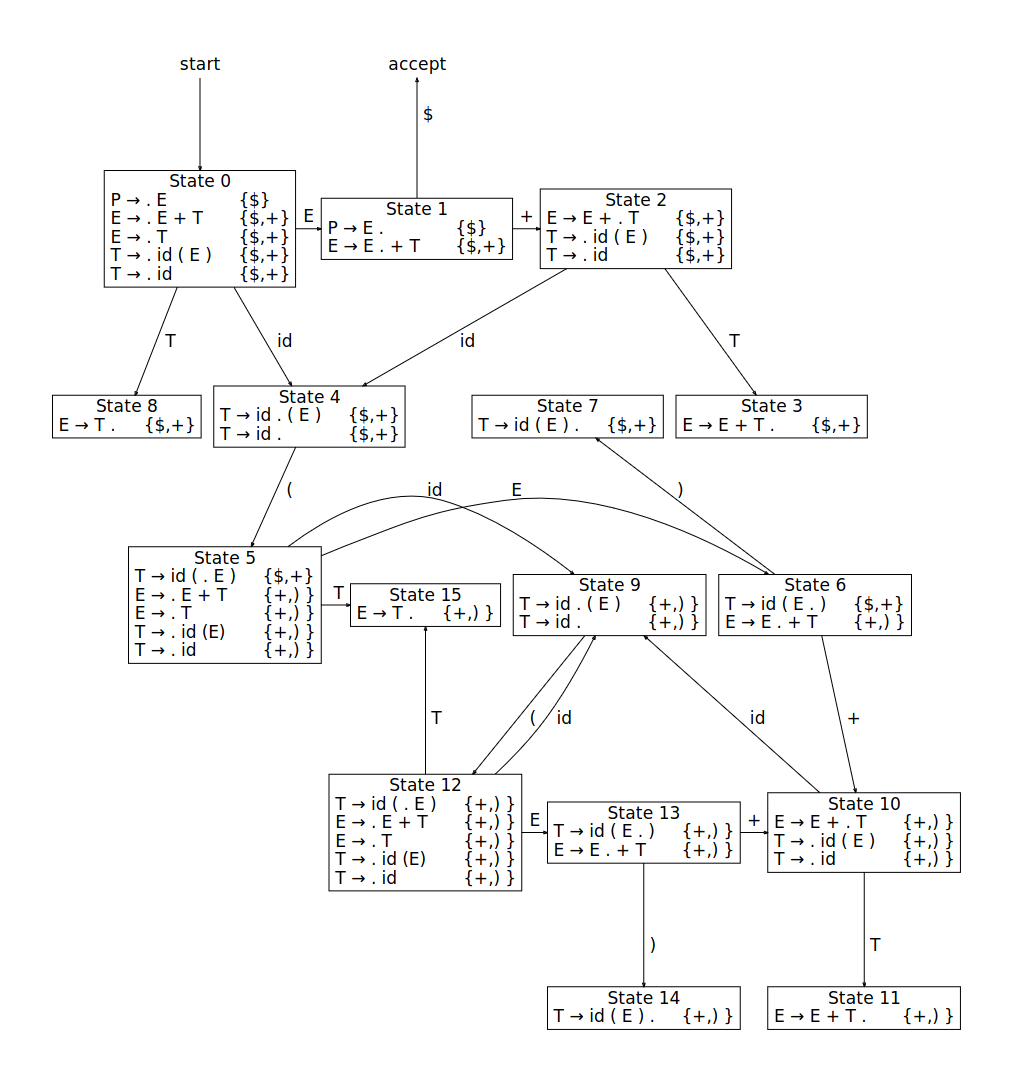
自动机对象只是一个状态列表。
每个状态有
-
id (usize)
- 状态的标识符
(例如,0,1)
- 状态的标识符
-
items (Vec)
- 状态LR(1)项的列表
(例如,E -> E . '+' F | { $, '+' })
- 状态LR(1)项的列表
-
transitions (HashMap<AtomicPattern, usize>)
- 将导致转到新状态的原子模式的映射
(例如,{ '+' -> 7 },{ %b -> 4, T -> 6 })
- 将导致转到新状态的原子模式的映射
每个项有
-
rule (Rule)
- 项的底层规则
(例如,E -> E '+' F在E -> E . '+' F | { $, '+' })
- 项的底层规则
-
dot (usize)
- 规则中点的位置
(例如,1在E -> E . '+' F | { $, '+' })
- 规则中点的位置
-
lookahead (HashSet)
- 在应用规则后可能跟随的标记的集合。请注意,其中之一必须是跟随标记,规则才能应用。
例如,在{ $, '+' }的E -> E . '+' F | }中
- 在应用规则后可能跟随的标记的集合。请注意,其中之一必须是跟随标记,规则才能应用。
关于实现,这里提供了构建 LR(1) 自动机的类似 Python 的伪代码算法
# Setup the kernel of the first state
first_state = next_empty_state()
for rule in grammar.rules:
if rule.symbol == grammar.start_symbol:
first_state.add_item(Item(rule, dot=0, lookahead={$}))
# Initialize construction state
states_to_process = [first_state]
processed_states = []
# Iterate until there aren't any more states to process.
while len(states_to_process) > 0:
# Get the state to process
state_to_process = states_to_process.pop()
# Computing closure of the state to process
# Loop until no more items are added
while True:
new_items = []
# Iterate current items to obtain new items
for item in state_to_process.items:
# If dot is not at the end of the pattern
if item.dot != len(item.rule.pattern):
# And if there is a symbol after dot
if item.rule.pattern[item.dot].is_symbol:
# Compute the lookahead for the new item
if item.dot == len(item.rule.pattern) - 1:
# S -> ... . E <==> Tokens in the current lookahead can follow E
# --------------------------------------------------------------
lookahead = item.lookahead
elif item.rule.pattern[item.dot + 1].is_token:
# S -> ... . E '+' <==> '+' can follow E
# --------------------------------------
lookahead = {item.rule.pattern[item.dot + 1]}
elif item.rule.pattern[item.dot + 1].is_symbol:
# S -> ... . E F <==> Tokens in FIRST(F) can follow E
# ---------------------------------------------------
lookahead = first_sets[item.rule.pattern[item.dot + 1]]
# Iterate over the rules of the grammar
for rule in grammar.rules:
# If the rule is for the symbol after dot
if rule.symbol == item.rule.pattern[item.dot]:
# Create a new item from the rule, with dot at the beginning
new_item = Item(rule, dot=0, lookahead=lookahead)
# If the item is not already in items of the state
if new_item not in state_to_process.items:
# Add it the set of new items
new_items.push(new_item)
# Process new items
for new_item in new_items:
# If a similar item with the same rule and the same dot but a different lookahead exists
if state_to_process.has_same_base_item(new_item):
# Merge lookaheads
state_to_process.merge_base_items(new_item)
# Otherwise
else:
# Add the new item directly
state_to_process.items.add(new_item)
# If state hasn't changed, break the loop
if not state_to_process.items.has_changed():
break
# Merge the states to process with an already existing state with the same closure.
replaced = False
for existing_state_with_same_items in processed_states:
if existing_state_with_same_items.items == state_to_process.items:
replaced = True
for state in processed_states:
# Replace transitions from existing states to point to the correct state.
state.transitions.replace_value(state_to_process, existing_state_with_same_items)
break
if replaced:
# If it's merged with an existing state, there is nothing else to do
continue
# Compute transitions of from the state to process.
for item in state_to_process.items:
# If dot is not at the end
if item.dot != len(item.rule.pattern):
# S -> ... . E ... <==> Seeing E would cause a transition to another state
# S -> ... . '+' ... <==> Seeing '+' would cause a transition to another state
# ----------------------------------------------------------------------------
atomic_pattern_after_dot = item.rule.pattern[item.dot]
# If state to transition is not created yet, create an empty state for it.
if atomic_pattern_after_dot is not in transitions:
# Create an empty state to transition to
state_to_process.transitions[atomic_pattern_after_dot] = next_empty_state()
# Setup the kernel of the state to transition
state_to_transition = state_to_process.transitions[atomic_pattern_after_dot]
state_to_transition.items.push(item.shift_dot_to_right())
# Add state to process to processed states, as we're done with it
processed_states.push(state_to_process)
这部分内容在 src/automaton.rs 中实现。
示例语法的 LR(1) 自动机
+-------+------------------+-----------------+--------------+
| State | Items | Lookaheads | Transitions |
+-------+------------------+-----------------+--------------+
| 0 | E -> . E '+' F | { $, '+' } | E -> 1 |
| | E -> . F | { $, '+' } | F -> 2 |
| | F -> . F '*' T | { $, '+', '*' } | T -> 3 |
| | F -> . T | { $, '+', '*' } | %b -> 4 |
| | T -> . %b | { $, '+', '*' } | |
+-------+------------------+-----------------+--------------+
| 1 | E -> E . '+' F | { $, '+' } | '+' -> 7 |
+-------+------------------+-----------------+--------------+
| 2 | E -> F . | { $, '+' } | '*' -> 5 |
| | F -> F . '*' T | { $, '+', '*' } | |
+-------+------------------+-----------------+--------------+
| 3 | F -> T . | { $, '+', '*' } | |
+-------+------------------+-----------------+--------------+
| 4 | T -> %b . | { $, '+', '*' } | |
+-------+------------------+-----------------+--------------+
| 5 | F -> F '*' . T | { $, '+', '*' } | %b -> 4 |
| | T -> . %b | { $, '+', '*' } | T -> 6 |
+-------+------------------+-----------------+--------------+
| 6 | F -> F '*' T . | { $, '+', '*' } | |
+-------+------------------+-----------------+--------------+
| 7 | E -> E '+' . F | { $, '+' } | T -> 3 |
| | F -> . F '*' T | { $, '+', '*' } | %b -> 4 |
| | F -> . T | { $, '+', '*' } | F -> 8 |
| | T -> . %b | { $, '+', '*' } | |
+-------+------------------+-----------------+--------------+
| 8 | E -> E '+' F . | { $, '+' } | '*' -> 5 |
| | F -> F . '*' T | { $, '+', '*' } | |
+-------+------------------+-----------------+--------------+
5) 构建ACTION和GOTO表
最后,我们可以根据以下约束计算解析器的 ACTION 和 GOTO 表
-
对于每个
action ∈ ACTION(state, token),以下条件至少要满足其中一个-
Anything -> ... . token ... | lookahead ∈ state.items和
action==Shift(state.transitions[标记]) -
Anything -> ... . | lookahead ∈ state.items和
token ∈ lookahead和
token == $和
item.rule.symbol == grammar.start_symbol和
action==Accept(item.rule) -
Anything -> ... . | lookahead ∈ state.items和
token ∈ lookahead和
(token != $或item.rule.symbol != grammar.start_symbol) 和
action==Reduce(item.rule)
-
-
对于每个
goto ∈ GOTO(state, Symbol),以下条件至少要满足其中一个Anything -> ... . Symbol ... | lookahead ∈ state.items和
goto==state.transitions[符号]
关于实现,下面是构建 ACTION 和 GOTO 表的类似 Python 的伪代码算法
# Initialize empty action tables
action_table = {}
goto_table = {}
# For each state in the automaton
for state in automaton.states:
# Iterate over the items of the state
for item in state.items:
# If dot is at the end of the item
if item.dot == len(item.rule.pattern):
# S -> ... . <==> We can either reduce the rule or accept if S is a start symbol
# ------------------------------------------------------------------------------
# We can only perform actions for the tokens in the follow set of the symbol of the rule
for following_token in follow_sets[item.rule.symbol]:
# And only if the token is also in the lookahead of the item
if following_token in item.lookahead:
# Finally, if the token is $ and matching rule is a start symbol
if following_token == $ and item.rule.symbol == grammar.start_symbol:
# We should accept
action_table[state, following_token].push(Accept(item.rule))
# Otherwise
else:
# We should reduce the matching rule
action_table[state, following_token].push(Reduce(item.rule))
else:
# We get the last atomic pattern
atomic_pattern_after_dot = item.rule.pattern[item.dot]
# And the transition on the atomic pattern from the automaton
transition = state.transitions[atomic_pattern_after_dot]
if atomic_pattern_after_dot.is_token:
# S -> ... . '+' ... <==> We should shift and transition to another state
# if the dot precedes a token
# -------------------------------------------------------------------
action_table[state, atomic_pattern_after_dot].push(Shift(transition))
elif atomic_pattern_after_dot.is_symbol:
# S -> ... . E ... <==> We should update GOTO table if the dot precedes a symbol
# This can only happen after a reduction, and the parser
# would look to GOTO table to determine the next state
# --------------------------------------------------------------------------------
goto_table[state, atomic_pattern_after_dot] = transition
这通过src/tables.rs来完成。
示例语法的 ACTION 和 GOTO 表
+-------+-------------------------------+-------------------+
| | Action | Goto |
| State | ----------------------------- | ----------------- |
| | '+' '*' %b $ | E F T |
+-------+-------------------------------+-------------------+
| 0 | - - s4 - | 1 2 3 |
+-------+-------------------------------+-------------------+
| 1 | s7 - - - | - - - |
+-------+-------------------------------+-------------------+
| 2 | r2 s5 - a2 | - - - |
+-------+-------------------------------+-------------------+
| 3 | r4 r4 - r4 | - - - |
+-------+-------------------------------+-------------------+
| 4 | r5 r5 - r5 | - - - |
+-------+-------------------------------+-------------------+
| 5 | - - s4 - | - - 6 |
+-------+-------------------------------+-------------------+
| 6 | r3 r3 - r3 | - - - |
+-------+-------------------------------+-------------------+
| 7 | - - s4 - | - 8 3 |
+-------+-------------------------------+-------------------+
| 8 | r1 s5 - a1 | - - - |
+-------+-------------------------------+-------------------+
6) 分词输入
在 dotlr 中的词法分析算法是最简单的词法分析算法。
以下是一个类似 Python 的伪代码来描述这个想法
# Initialize the result
tokens = []
# Loop until all of the input is consumed
remaining_input = input.trim();
while len(remaining_input) > 0:
# Try to match regular expression tokens
for (regex_token, regex) in grammar.regular_expressions:
if match := regex.start_matches(remaining_input):
# We have a match so add it to result
tokens.push(regex_token)
# And shrink remaining input
remaining_input = remaining_input[match.end:].trim()
break
# No regular expression tokens matched
else:
# So try to match constant tokens
for constant_token in grammar.constant_tokens:
if remaining_input.startswith(constant_token):
# We have a match so add it to result
tokens.push(constant_token)
# And shrink remaining input
remaining_input = remaining_input[len(constant_token):]
break
# No tokens matched
else:
raise TokenizationError
# Lastly, add the end of input token so the parser eventually accepts.
tokens.push($)
词法分析后的示例输入
%b '+' %b '*' %b $
7) 解析分词
最后,这是一个类似 Python 的伪代码来描述解析算法
# Initialize the parsing state
state_stack = [ 0 ]
tree_stack = []
remaining_tokens.reverse()
# Get the first token
current_token = remaining_tokens.pop()
# Loop until algorithm either accepts or rejects
while True:
# Get the current state
current_state = state_stack[-1]
# Get the action to take from ACTION table
action_to_take = action_table[current_state, current_token]
# If the action is to shift
if action_to_take == Shift(next_state):
# Create a terminal tree for the current token and push it to the tree stack
tree_stack.push(TerminalNode(current_token));
# Pop the next token
current_token = remaining_tokens.pop()
# Transition to the next state according to ACTION table
state_stack.push(next_state);
# If the action is to reduce
elif action_to_take == Reduce(rule_index):
# Get the length of the pattern of the rule, say N
rule = grammar.rules[rule_index]
pattern_length = len(rule.pattern)
# Create a non-terminal tree with last N items in the tree stack
tree = NonTerminalNode(rule.symbol, tree_stack[-pattern_length:])
# Shrink state and tree stacks
tree_stack = tree_stack[:-pattern_length]
state_stack = state_stack[:-pattern_length]
# Push the new tree to the tree stack
tree_stack.push(tree)
# Transition to the next state according to GOTO table
state_stack.push(goto_table[state_stack[-1], rule.symbol])
# If the action is to accept
elif action_to_take == Accept(rule_index):
# Create a final non-terminal tree with everything in the tree stack and return it
return NonTerminalNode(grammar.start_symbol, tree_stack)
# No action can be taken, so input is not well-formed
else:
# So raise an error
raise ParsingError
示例输入的解析步骤
+------+-------------+----------------+--------------------+----------------------+
| Step | State Stack | Symbol Stack | Remaining Input | Action Taken |
+------+-------------+----------------+--------------------+----------------------+
| 0 | 0 | | %b '+' %b '*' %b $ | Shift 4 |
+------+-------------+----------------+--------------------+----------------------+
| 1 | 0 4 | %b | '+' %b '*' %b $ | Reduce4 T -> %b |
+------+-------------+----------------+--------------------+----------------------+
| 2 | 0 3 | T | '+' %b '*' %b $ | Reduce3 F -> T |
+------+-------------+----------------+--------------------+----------------------+
| 3 | 0 2 | F | '+' %b '*' %b $ | Reduce1 E -> F |
+------+-------------+----------------+--------------------+----------------------+
| 4 | 0 1 | E | '+' %b '*' %b $ | Shift 7 |
+------+-------------+----------------+--------------------+----------------------+
| 5 | 0 1 7 | E '+' | %b '*' %b $ | Shift 4 |
+------+-------------+----------------+--------------------+----------------------+
| 6 | 0 1 7 4 | E '+' %b | '*' %b $ | Reduce4 T -> %b |
+------+-------------+----------------+--------------------+----------------------+
| 7 | 0 1 7 3 | E '+' T | '*' %b $ | Reduce3 F -> T |
+------+-------------+----------------+--------------------+----------------------+
| 8 | 0 1 7 8 | E '+' F | '*' %b $ | Shift 5 |
+------+-------------+----------------+--------------------+----------------------+
| 9 | 0 1 7 8 5 | E '+' F '*' | %b $ | Shift 4 |
+------+-------------+----------------+--------------------+----------------------+
| 10 | 0 1 7 8 5 4 | E '+' F '*' %b | $ | Reduce4 T -> %b |
+------+-------------+----------------+--------------------+----------------------+
| 11 | 0 1 7 8 5 6 | E '+' F '*' T | $ | Reduce2 F -> F '*' T |
+------+-------------+----------------+--------------------+----------------------+
| 12 | 0 1 7 8 | E '+' F | $ | Accept0 E -> E '+' F |
+------+-------------+----------------+--------------------+----------------------+
最后,示例输入的解析树
E
├─ E
│ └─ F
│ └─ T
│ └─ 1
├─ +
└─ F
├─ F
│ └─ T
│ └─ 0
├─ *
└─ T
└─ 1
有任何基准测试吗?
是的,尽管 dotlr 不是一个性能导向的项目,但我认为有一个基准测试套件来查看更改对其性能的影响是很有趣的,所以我创建了一些 JSON 语法并进行了解析基准测试。
您可以在项目目录中运行以下命令来执行基准测试
cargo bench
这个命令在我的计算机上打印了以下内容,它有一个 Intel i7-12700K CPU
...
Parsing JSON/Simple time: [262.04 ms 263.31 ms 264.60 ms]
thrpt: [94.218 MiB/s 94.680 MiB/s 95.138 MiB/s]
...
Parsing JSON/Optimized time: [181.44 ms 181.63 ms 181.82 ms]
thrpt: [137.11 MiB/s 137.26 MiB/s 137.40 MiB/s]
...
此外,它还会生成一个包含详细图表的HTML报告。您可以在运行命令后,在target/criterion/report/index.html找到此报告。
对于JSON解析器来说,性能并不理想,但这也是预料之中的,因为它不是主要目标。您可以自由地创建pull请求以改进解析性能,希望在不改变库的可读性的情况下进行。
此外,请注意,这些基准测试仅针对解析步骤。分词不是本库的重点,而且坦白地说,其实现并不最佳。
我可以修改它吗?
当然,您可以自由地从GitHub上的dotlr进行fork,将fork克隆到您的机器上,启动您喜欢的IDE,并做出任何您想要的修改。
如果您有任何对dotlr有益的修改,请不要忘记开启一个pull请求!
你在创建此项目时使用了哪些资源?
- https://www3.nd.edu/~dthain/compilerbook/chapter4.pdf
- https://soroushj.github.io/lr1-parser-vis/
- https://jsmachines.sourceforge.net/machines/lr1.html
它的许可方式是什么?
dotlr是免费的、开源的,并且拥有许可权!
此仓库中的所有代码均采用以下两种许可方式之一进行双重许可:
- MIT许可(LICENSE-MIT 或 https://open-source.org.cn/licenses/MIT)
- Apache许可2.0版(LICENSE-APACHE 或 https://apache.ac.cn/licenses/LICENSE-2.0)
这意味着您可以选择您喜欢的许可方式!
依赖项
~8–18MB
~189K SLoC