16 个主要重大版本发布
| 新 40.1.0 | 2024 年 8 月 20 日 |
|---|---|
| 39.0.0 | 2024 年 7 月 2 日 |
| 38.0.1 | 2024 年 5 月 30 日 |
| 36.0.0 | 2024 年 3 月 10 日 |
| 20.0.0 | 2023 年 3 月 21 日 |
在 数据库实现 中排名第 35
每月下载量 150
375KB
8K SLoC
DataFusion 在 Python 中
![]()
![]()
这是一个绑定到 Apache Arrow 内存查询引擎 DataFusion 的 Python 库。
DataFusion 的 Python 绑定可以用作在 Python 中构建新数据系统的基础。以下是一些示例
- Dask SQL 使用 DataFusion 的 Python 绑定进行 SQL 解析、查询计划和逻辑计划优化,然后将逻辑计划转换为 Dask 操作以执行。
- DataFusion Ballista 是一个分布式 SQL 查询引擎,它扩展了 DataFusion 的 Python 绑定以用于分布式场景。
还可以直接使用这些 Python 绑定进行 DataFrame 和 SQL 操作,但您可能会发现 Polars 和 DuckDB 更适合此用例,因为它们更侧重于最终用户,并且比这些 Python 绑定维护得更积极。
特性
- 使用 SQL 或 DataFrame 对 CSV、Parquet 和 JSON 数据源执行查询。
- 使用 DataFusion 的查询优化器优化查询。
- 从 SQL 中执行用户定义的 Python 代码。
- 与支持 PyArrow 的 Pandas 和其他 DataFrame 库交换数据。
- 以 Substrait 格式序列化和反序列化查询计划。
- 支持将 SQL 查询转换为 Polars、Pandas 和 cuDF DataFrame 调用的实验性功能。
示例用法
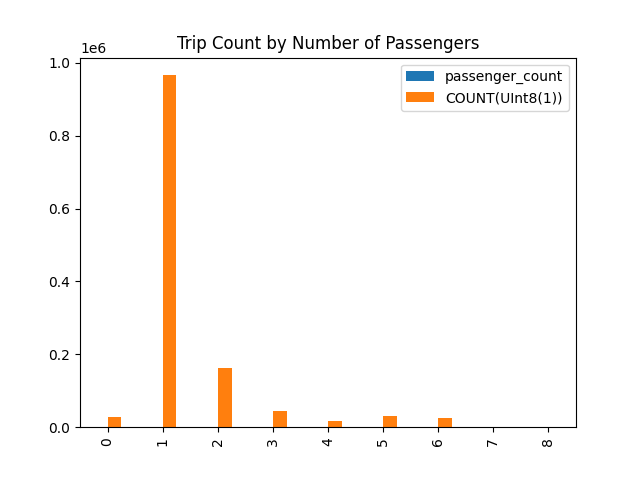
以下示例演示了使用 DataFusion 对 Parquet 文件运行 SQL 查询,将结果存储在 Pandas DataFrame 中,然后绘制图表。
本示例中使用的 Parquet 文件可以从以下页面下载
from datafusion import SessionContext
# Create a DataFusion context
ctx = SessionContext()
# Register table with context
ctx.register_parquet('taxi', 'yellow_tripdata_2021-01.parquet')
# Execute SQL
df = ctx.sql("select passenger_count, count(*) "
"from taxi "
"where passenger_count is not null "
"group by passenger_count "
"order by passenger_count")
# convert to Pandas
pandas_df = df.to_pandas()
# create a chart
fig = pandas_df.plot(kind="bar", title="Trip Count by Number of Passengers").get_figure()
fig.savefig('chart.png')
这会产生以下图表
配置
在创建上下文时,可以配置运行时(内存和磁盘设置)和配置设置。
runtime = (
RuntimeConfig()
.with_disk_manager_os()
.with_fair_spill_pool(10000000)
)
config = (
SessionConfig()
.with_create_default_catalog_and_schema(True)
.with_default_catalog_and_schema("foo", "bar")
.with_target_partitions(8)
.with_information_schema(True)
.with_repartition_joins(False)
.with_repartition_aggregations(False)
.with_repartition_windows(False)
.with_parquet_pruning(False)
.set("datafusion.execution.parquet.pushdown_filters", "true")
)
ctx = SessionContext(config, runtime)
有关更多信息,请参阅 API 文档。
打印上下文将显示当前配置设置。
print(ctx)
更多示例
有关更多信息,请参阅示例。
使用 DataFusion 执行查询
- 使用 SQL 查询 Parquet 文件
- 使用 DataFrame API 查询 Parquet 文件
- 运行 SQL 查询并将结果存储在 Pandas DataFrame 中
- 使用 Python 用户定义函数 (UDF) 运行 SQL 查询
- 使用 Python 用户定义聚合函数 (UDAF) 运行 SQL 查询
- 查询 PyArrow 数据
- 创建 dataframe
- 导出 dataframe
运行用户定义的 Python 代码
Substrait 支持
如何安装(从 pip)
Pip
pip install datafusion
# or
python -m pip install datafusion
Conda
conda install -c conda-forge datafusion
您可以通过运行以下命令来验证安装:
>>> import datafusion
>>> datafusion.__version__
'0.6.0'
如何开发
这假设您已安装 rust 和 cargo。我们使用 pyo3 和 maturin 推荐的工作流程。
此工作流程中使用的 Maturin 工具可以通过 Conda 或 Pip 安装。两种方法都应该提供相同的使用体验。提供多种方法只是为了满足开发者的偏好。Conda 和 Pip 的引导过程如下。
引导(Conda)
# fetch this repo
git clone git@github.com:apache/datafusion-python.git
# create the conda environment for dev
conda env create -f ./conda/environments/datafusion-dev.yaml -n datafusion-dev
# activate the conda environment
conda activate datafusion-dev
引导(Pip)
# fetch this repo
git clone git@github.com:apache/datafusion-python.git
# prepare development environment (used to build wheel / install in development)
python3 -m venv venv
# activate the venv
source venv/bin/activate
# update pip itself if necessary
python -m pip install -U pip
# install dependencies (for Python 3.8+)
python -m pip install -r requirements.in
测试依赖于 git 子模块中的测试数据。
git submodule init
git submodule update
每当 rust 代码更改(您的更改或通过 git pull)时
# make sure you activate the venv using "source venv/bin/activate" first
maturin develop
python -m pytest
运行和安装 pre-commit 钩子
arrow-datafusion-python 利用 pre-commit 帮助开发者进行代码 linting,以帮助减少因 linting 错误而最终在 CI 中失败的提交次数。使用 pre-commit 钩子是可选的,但对于保持 PR 清洁和简洁非常有帮助。
您可以通过运行 pre-commit install 来安装我们的 pre-commit 钩子,这将在您的 ARROW_DATAFUSION_PYTHON_ROOT/.github 目录中安装配置,并在您每次进行提交时运行,如果发现违规的 lint,则无法完成提交,让您可以在推送之前在本地进行更改。
您也可以通过简单地运行 pre-commit run --all-files
不使用 pre-commit 运行 linters
ci/scripts 中有脚本用于运行 Rust 和 Python linters。
./ci/scripts/python_lint.sh
./ci/scripts/rust_clippy.sh
./ci/scripts/rust_fmt.sh
./ci/scripts/rust_toml_fmt.sh
如何更新依赖项
要更改测试依赖项,更改 requirements.in 并运行
# install pip-tools (this can be done only once), also consider running in venv
python -m pip install pip-tools
python -m piptools compile --generate-hashes -o requirements-310.txt
要更新依赖项,请使用 -U 运行
python -m piptools compile -U --generate-hashes -o requirements-310.txt
更多详细信息在此
依赖项
~72MB
~1.5M SLoC