3 个版本 (稳定版)
| 1.0.1 | 2021年11月22日 |
|---|---|
| 1.0.0 | 2021年11月18日 |
| 0.0.0 | 2021年9月23日 |
1637 在 密码学 中排名
每月下载量 37 次
77KB
2K SLoC
Cracken
Cracken 是一个用纯 Rust 安全编写(更多信息请参阅 talk/)的快速密码词表生成器、Smartlist 创建和密码混合掩码分析工具。受到像 maskprocessor、hashcat、Crunch 以及 🤗 HuggingFace 的 tokenizers 等优秀工具的启发。
什么?为什么?哇?
在 DeepSec2021 上,我们提出了一种新的分析方法,通过利用 NLP 分词器分析密码作为混合掩码,利用密码中的常见子串(更多信息请参阅 talk/)。
我们的方法将密码分解为其子词,而不是仅仅是一个字符掩码。例如,"HelloWorld123!" 分解为 "['Hello', 'World', '123!']",因为这些三个子词在其他密码中非常常见。
混合掩码 & Smartlists
- 📄 Smartlists - 使用 NLP 分词器从密码创建的紧凑且具有代表性的子词列表
- 🎭 混合掩码 - 将密码表示为词表和字符的组合(例如
?w1?w2?l?d)
使用 Smartlists 和混合掩码分析 RockYou 密码
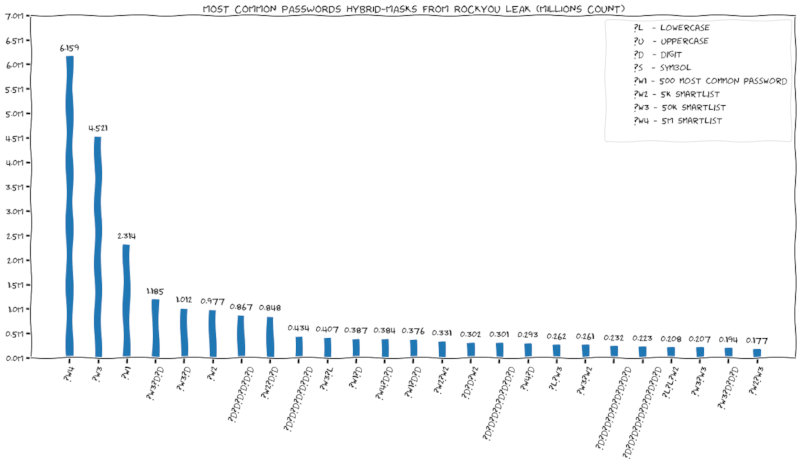
完整表格 在这里
Cracken 🐙 用于
- ✅ 非常非常快速地生成
混合-掩码🦸⚡💨(请参阅 性能 部分) - ✅ 构建
Smartlists- 从给定的密码文件中生成紧凑且具有代表性的子词列表(使用 🤗 HuggingFace 的 tokenizers) - ✅ 分析密码的
混合掩码- 建立密码候选者的统计信息(再次非常快速)
使用Cracken的可能工作流程
简单
- 从混合掩码生成候选词汇表 - 例如
cracken -w rockyou.txt -w 100-most-common.txt '?w1?w2?d?d?d?d?s' - 您可以将Cracken生成的密码传递给
hashcat、john或您喜欢的密码破解工具
高级
- 从现有密码创建智能列表 -
cracken create - 分析明文密码列表 -
cracken entropy - 使用最常见的
混合掩码快速生成密码候选者 -cracken generate -i hybrid-masks.txt
有关更多详细信息,请参阅使用说明部分
入门
下载(目前仅限Linux): 最新发布 🔗
有关更多安装选项,请参阅 安装 部分
运行Cracken
生成所有以大写字母开头,后跟6个小写字母,然后是数字的8位单词
$ cracken -o pwdz.lst '?u?l?l?l?l?l?l?d'
生成带有年份后缀(1000-2999)的两个词汇表的单词 <firstname><lastname><year>
$ cracken --wordlist firstnames.txt --wordlist lastnames.lst --charset '12' '?w1?w2?1?d?d?d'
从rockyou.txt中提取的子单词创建一个50k大小的智能列表
$ cracken create -f rockyou.txt -m 50000 --smartlist smart.lst
使用智能列表估算密码HelloWorld123!的混合掩码的熵
$ cracken entropy -f smart.lst 'HelloWorld123!'
hybrid-min-split: ["hello", "world1", "2", "3", "!"]
hybrid-mask: ?w1?w1?d?d?s
hybrid-min-entropy: 42.73
--
charset-mask: ?l?l?l?l?l?l?l?l?l?l?d?d?d?s
charset-mask-entropy: 61.97
性能
截至编写本文时,Cracken可能是世界上最快的词汇表生成器
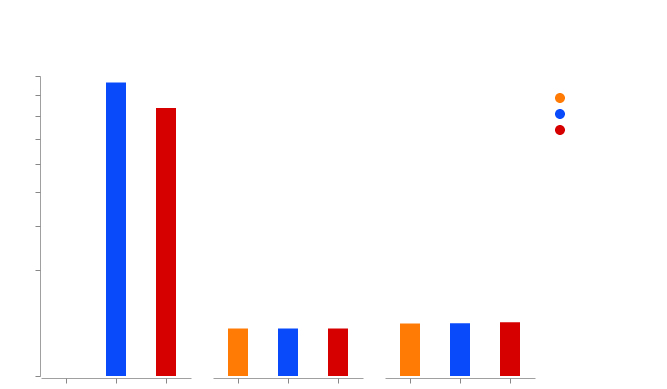
Cracken的性能比hashcat的C语言编写的快速maskprocessor提高了约25%。
Cracken可以每核心生成约2 GB/s。
有关更多详细信息,请参阅benchmarks/ 🔗
为什么速度很重要?典型的GPU每秒可以测试数十亿个密码,具体取决于密码散列函数。当词汇表生成器每秒生成的单词少于破解工具可以处理时,破解速度将降低。
混合掩码分析性能
Cracken使用 A* 算法快速分析密码。它可以以每秒 ~100k 个密码 的速度找到密码文件的最低混合掩码(使用 cracken entropy -f words1.txt -f words2.txt ... -p pwds.txt)
安装
安装Cracken或从源代码编译
下载二进制文件(目前仅限Linux)
从 发布 🔗 下载最新版本
从源代码构建(所有平台)
Cracken是用Rust编写的,需要rustc来编译。Cracken应该支持Rust支持的所有平台。
有关cargo 🔗的安装说明
有两种从源代码构建的方法 - 使用crates.io上的cargo安装(首选)或手动从源代码编译。
1. 从crates.io安装(首选)
使用cargo安装
$ cargo install cracken
2. 从源代码构建
克隆 Cracken
$ git clone https://github.com/shmuelamar/cracken
构建 Cracken
$ cd cracken
$ cargo build --release
运行它
$ ./target/release/cracken --help
使用信息
$ cracken --help
Cracken v1.0.0 - a fast password wordlist generator
USAGE:
cracken [SUBCOMMAND]
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
SUBCOMMANDS:
generate (default) - Generates newline separated words according to given mask and wordlist files
create Create a new smartlist from input file(s)
entropy
Computes the estimated entropy of password or password file.
The entropy of a password is the log2(len(keyspace)) of the password.
There are two types of keyspace size estimations:
* mask - keyspace of each char (digit=10, lowercase=26...).
* hybrid - finding minimal split into subwords and charsets.
For specific subcommand help run: cracken <subcommand> --help
Example Usage:
## Generate Subcommand Examples:
# all digits from 00000000 to 99999999
cracken ?d?d?d?d?d?d?d?d
# all digits from 0 to 99999999
cracken -m 1 ?d?d?d?d?d?d?d?d
# words with pwd prefix - pwd0000 to pwd9999
cracken pwd?d?d?d?d
# all passwords of length 8 starting with upper then 6 lowers then digit
cracken ?u?l?l?l?l?l?l?d
# same as above, write output to pwds.txt instead of stdout
cracken -o pwds.txt ?u?l?l?l?l?l?l?d
# custom charset - all hex values
cracken -c 0123456789abcdef '?1?1?1?1'
# 4 custom charsets - the order determines the id of the charset
cracken -c 01 -c ab -c de -c ef '?1?2?3?4'
# 4 lowercase chars with years 2000-2019 suffix
cracken -c 01 '?l?l?l?l20?1?d'
# starts with firstname from wordlist followed by 4 digits
cracken -w firstnames.txt '?w1?d?d?d?d'
# starts with firstname from wordlist with lastname from wordlist ending with symbol
cracken -w firstnames.txt -w lastnames.txt -c '!@#$' '?w1?w2?1'
# repeating wordlists multiple times and combining charsets
cracken -w verbs.txt -w nouns.txt '?w1?w2?w1?w2?w2?d?d?d'
## Create Smartlists Subcommand Examples:
# create smartlist from single file into smart.txt
cracken create -f rockyou.txt --smartlist smart.txt
# create smartlist from multiple files with multiple tokenization algorithms
cracken create -t bpe -t unigram -t wordpiece -f rockyou.txt -f passwords.txt -f wikipedia.txt --smartlist smart.txt
# create smartlist with minimum subword length of 3 and max numbers-only subwords of size 6
cracken create -f rockyou.txt --min-word-len 3 --numbers-max-size 6 --smartlist smart.txt
## Entropy Subcommand Examples:
# estimating entropy of a password
cracken entropy --smartlist vocab.txt 'helloworld123!'
# estimating entropy of a passwords file with a charset mask entropy (default is hybrid)
cracken entropy --smartlist vocab.txt -t charset -p passwords.txt
# estimating the entropy of a passwords file
cracken entropy --smartlist vocab.txt -p passwords.txt
cracken-v1.0.0 linux-x86_64 compiler: rustc 1.56.1 (59eed8a2a 2021-11-01)
more info at: https://github.com/shmuelamar/cracken
生成子命令使用信息
$ cracken generate --help
cracken-generate
(default) - Generates newline separated words according to given mask and wordlist files
USAGE:
cracken generate [FLAGS] [OPTIONS] <mask> --masks-file <masks-file>
FLAGS:
-h, --help
Prints help information
-s, --stats
prints the number of words this command will generate and exits
-V, --version
Prints version information
OPTIONS:
-c, --custom-charset <custom-charset>...
custom charset (string of chars). up to 9 custom charsets - ?1 to ?9. use ?1 on the mask for the first charset
-i, --masks-file <masks-file>
a file containing masks to generate
-x, --maxlen <max-length>
maximum length of the mask to start from
-m, --minlen <min-length>
minimum length of the mask to start from
-o, --output-file <output-file>
output file to write the wordlist to, defaults to stdout
-w, --wordlist <wordlist>...
filename containing newline (0xA) separated words. note: currently all wordlists loaded to memory
ARGS:
<mask>
the wordlist mask to generate.
available masks are:
builtin charsets:
?d - digits: "0123456789"
?l - lowercase: "abcdefghijklmnopqrstuvwxyz"
?u - uppercase: "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
?s - symbols: " !\"\#$%&'()*+,-./:;<=>?@[\\]^_`{|}~"
?a - all characters: ?d + ?l + ?u + ?s
?b - all binary values: (0-255)
custom charsets ?1 to ?9:
?1 - first custom charset specified by --charset 'mychars'
wordlists ?w1 to ?w9:
?w1 - first wordlist specified by --wordlist 'my-wordlist.txt'
创建智能列表子命令使用信息
$ cracken create --help
cracken-create
Create a new smartlist from input file(s)
USAGE:
cracken create [FLAGS] [OPTIONS] --file <file>... --smartlist <smartlist>
FLAGS:
-h, --help Prints help information
-q, --quiet disables printing progress bar
-V, --version Prints version information
OPTIONS:
-f, --file <file>... input filename, can be specified multiple times for multiple files
--min-frequency <min_frequency> minimum frequency of a word, relevant only for BPE tokenizer
-l, --min-word-len <min_word_len> filters words shorter than the specified length
--numbers-max-size <numbers_max_size> filters numbers (all digits) longer than the specified size
-o, --smartlist <smartlist> output smartlist filename
-t, --tokenizer <tokenizer>... tokenizer to use, can be specified multiple times.
one of: bpe,unigram,wordpiece [default: bpe] [possible values: bpe, unigram, wordpiece]
-m, --vocab-max-size <vocab_max_size> max vocabulary size
熵子命令使用信息
$ cracken entropy --help
cracken-entropy
Computes the estimated entropy of password or password file.
The entropy of a password is the log2(len(keyspace)) of the password.
There are two types of keyspace size estimations:
* mask - keyspace of each char (digit=10, lowercase=26...).
* hybrid - finding minimal split into subwords and charsets.
USAGE:
cracken entropy [FLAGS] [OPTIONS] <password> --smartlist <smartlist>...
FLAGS:
-h, --help Prints help information
-s, --summary output summary of entropy for password
-V, --version Prints version information
OPTIONS:
-t, --mask-type <mask_type> type of mask to output, one of: charsets(charsets only), hybrid(charsets+wordlists) [possible values: hybrid, charset]
-p, --passwords-file <passwords-file> newline separated password file to estimate entropy for
-f, --smartlist <smartlist>... smartlist input file to estimate entropy with, a newline separated text file
ARGS:
<password> password to
许可证
Cracken 使用 MIT 许可证。**本项目必须仅用于合法目的⚖️**
贡献
Cracken 正在积极开发中,如果您想帮助,以下是此项目的部分路线图。请随时提交 PR 和打开问题。
依赖项
~19MB
~375K SLoC