11个稳定版本
| 1.0.10 | 2022年8月18日 |
|---|---|
| 1.0.9 | 2021年10月30日 |
| 1.0.8 | 2020年11月26日 |
| 1.0.7 | 2020年8月8日 |
| 1.0.0 | 2020年4月30日 |
#180 在 算法
30 每月下载量
52KB
546 行
计数排序
针对Iterator的计数排序实现。
支持的最低Rust版本
- Rust 1.56.0
- 由于迁移到2021版
使用方法
将依赖项添加到您的Cargo.toml
[dependencies]
counting_sort = "1.0.10"
例如,对于包含整数如u8、u16、i8、i16等的Vec,它可以立即“开箱即用”。
/*
* Add counting sort to your source code.
*/
use counting_sort::CountingSort;
let vec = vec![2,4,1,3];
// counting sort may fail, therefore a result is returned
let sorted_vec_result = vec.iter().cnt_sort();
assert!(sorted_vec_result.is_ok());
// if successful sorted elements were copied into a Vec
assert_eq!(vec![1,2,3,4], sorted_vec_result.unwrap());
发行说明
- 1.0.10
- 迁移到GitLab
- 1.0.9
- 迁移到2021版
- 修复了一些测试中的lint问题
- 1.0.8
- 修复了Rust 1.48.0之后的内文链接(参见通过名称链接项目)
- 添加了最新的tarpaulin cfg属性,以排除测试的代码覆盖率
- 修复了README.md中的错别字
- 1.0.7
- 添加了clippy配置(
all&pedantic) - 修复了clippy发现的问题
- 添加了clippy配置(
- 1.0.6
- 需要更新到最新版本的使用方法
- 清理了SVG链接
- 1.0.5
- 将SVG链接更改为GitHub仓库
- 1.0.4
- 默认分支重命名后,crates.io上的SVG链接损坏
- 1.0.3
- 修复了clippy发现的一些lint问题
- 查找类型
- 1.0.2
- 更新了
Readme.md,将license-file更改为license
- 更新了
- 1.0.1
- 向
Cargo.toml中添加了keywords、categories和license-file
- 向
代码覆盖率
[INFO tarpaulin] Coverage Results:
|| Uncovered Lines:
|| Tested/Total Lines:
|| src/lib.rs: 82/82
||
100.00% coverage, 82/82 lines covered
许可协议
设计目标
- 通过简单的算法学习更多Rust
- 尽可能高质量,因此
- 高代码覆盖率
- “长”代码注释
- 大量单元和集成测试
- 尽可能通用,考虑到迭代器和整数
- 我希望有一个接口,不仅限于切片或向量
- 我希望支持尽可能多的整数类型
- 一个可用的接口:“只需”在你的
cnt_sort、Vec、LinkedList等等上调用 - 轻微的内存消耗优化
- 安全性高于性能
- 例如,我会检查没有索引越界,尽管这仅在用户使用
cnt_sort_min_max方法时发生,最大值太小,当索引越界时 Rust 会引发恐慌
- 例如,我会检查没有索引越界,尽管这仅在用户使用
- 不破坏原始集合
- 实现可能会失败,尤其是在转换为索引期间
- 因此,元素不是从原始集合中移出,而是在迭代期间复制
稳定的计数排序
- 计数排序是一种稳定算法
- 实现这一点的选项之一是反向迭代集合(因此需要 DoubleEndedIterator)
- 当所有元素都是整数时,还可以选择另一个选项,它结合了两个循环,请参见这里的简要描述
- 由于没有整数特性,如果实现旨在尽可能通用(不将所有内容都作为宏实现),则此选项不可行
- 在此算法中实现了另一个选项
- 在计数值向量(或实际上是累计频率)中分配了一个额外的元素,代表小于最小值的值
- 显然,该元素不存在,仅在重新排序阶段使用
- 该元素用值 0 分配
- 在计算所有现有值的直方图(或更准确地说,它们映射到的索引)时,这个 0 号元素永远不会被访问
- 在计算累计频率(或前缀和)时,使用该元素,但它的值是 0,因此不会改变任何事情
- 在重新排序给定的集合(算法的最后阶段)时,应用了一个技巧
- 在重新排序每个元素时,它实际上使用先前元素的累计频率来计算元素在排序输出向量中的位置
- 这是由于在计数值向量(或累计频率向量)“开始”处分配了一个额外的元素
- 为了理解这一点,查看这个计数排序算法相当不错的可视化可能是有意义的
- 在重新排序期间,从集合的“后面”取出了一个元素
- 该元素随后被转换为索引(在上面的可视化中,元素与索引相同)
- 使用此索引,利用元素的累计频率来计算元素在排序输出向量中的位置
- 此计算通过减去累计频率的值来实现
- 因此,考虑向量中的第一个元素是0号元素
- 此外,为了实现排序的稳定性,元素在排序后保持其顺序
- 当每个等效元素,即它们属于一个等价类,被放入输出向量时,该元素的(可能多次减少的)累计频率等于前一个元素的未修改累计频率
- 实际上,这个频率是上述等价类第一个元素的位置
- 因此,可以使用前一个元素的累计频率来计算元素在输出排序向量中的位置
- 显然,每次将元素放入排序输出向量时,都需要增加前一个元素的累计频率,以避免覆盖等效元素
- 最后说明:分配的累计频率的额外元素实际上表示集合的第一个最小值的索引:零
渐近性能
- 迭代所有
n个元素,并检查该值是否是新的最小值或最大值 - 分配大小为
d = max_value - min_value(即距离d)的计数值向量 - 再次迭代所有
n个元素以创建每个值的直方图 - 迭代计数值向量的所有
d个元素以计算前缀和 - 为存储排序元素分配新的向量
- 从前向后迭代所有
n个元素以将元素重新排序到新向量中
因此,渐近性能是 O(3n+d)。当使用 cnt_sort_min_max 函数(当知道最小值和最大值时),渐近性能是 O(2n+d)。
基准测试
- 与 slice.sort 和 count_sort 的比较
HW
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 36 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 42
Model name: Intel(R) Core(TM) i5-2410M CPU @ 2.30GHz
Stepping: 7
CPU MHz: 1721.799
CPU max MHz: 2900,0000
CPU min MHz: 800,0000
BogoMIPS: 4591.83
Virtualization: VT-x
L1d cache: 64 KiB
L1i cache: 64 KiB
L2 cache: 512 KiB
L3 cache: 3 MiB
NUMA node0 CPU(s): 0-3
Vulnerability Itlb multihit: KVM: Mitigation: Split huge pages
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full generic retpoline, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ht tm pbe syscall nx rdtscp l
m constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm
2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx lahf_lm epb pti ssbd ibrs ibpb stibp tpr_shadow
vnmi flexpriority ept vpid xsaveopt dtherm ida arat pln pts md_clear flush_l1d
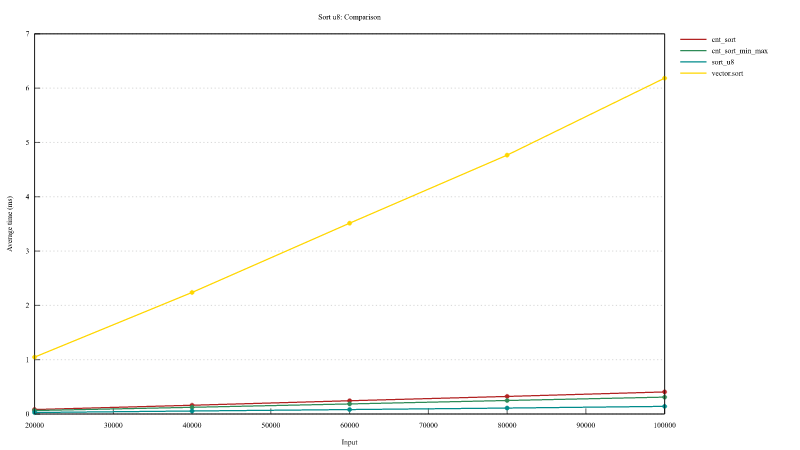
对 u8 进行排序
- 平均执行时间
- 距离:256
- 最小值 0
- 最大值 256
| 元素数量 | cnt_sort | cnt_sort_min_max | vector.sort | sort_u8 |
|---|---|---|---|---|
| 20000 | 82 us | 63 us | 1048 us | 27 us |
| 40000 | 161 us | 123 us | 2239 us | 55 us |
| 60000 | 244 us | 185 us | 3513 us | 82 us |
| 80000 | 323 us | 248 us | 4761 us | 109 us |
| 100000 | 406 us | 310 us | 6180 us | 137 us |
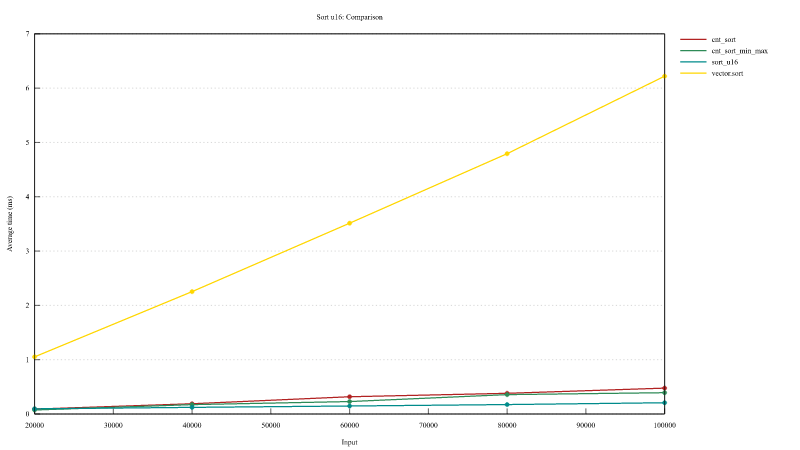
对 u16 进行排序
- 平均执行时间
- 距离:512
- 最小值 512
- 最大值 1024
- 这是计数排序实现的理想解决方案
| 元素数量 | cnt_sort | cnt_sort_min_max | vector.sort | sort_u16 |
|---|---|---|---|---|
| 20000 | 89 us | 73 us | 1051 us | 95 us |
| 40000 | 188 us | 172 us | 2250 us | 122 us |
| 60000 | 318 us | 229 us | 3513 us | 148 us |
| 80000 | 382 us | 355 us | 4785 us | 174 us |
| 100000 | 477 us | 392 us | 6200 us | 205 us |