17 个版本
| 0.3.3 | 2024 年 5 月 10 日 |
|---|---|
| 0.3.2 | 2023 年 9 月 10 日 |
| 0.3.1 | 2022 年 10 月 31 日 |
| 0.3.1-alpha.1 | 2022 年 5 月 30 日 |
| 0.2.0 | 2021 年 7 月 29 日 |
#90 在 数据库接口 中
每月 215 次下载
在 pigeon-rs 中使用
550KB
13K SLoC
ConnectorX 


从  加载到
加载到 ![]() ,最快的方式。
,最快的方式。
ConnectorX 允许您以最快和最内存高效的方式将数据从数据库加载到 Python 中。
您只需要一行代码
import connectorx as cx
cx.read_sql("postgresql://username:password@server:port/database", "SELECT * FROM lineitem")
可选地,您可以通过指定分区列来使用并行来加速数据加载。
import connectorx as cx
cx.read_sql("postgresql://username:password@server:port/database", "SELECT * FROM lineitem", partition_on="l_orderkey", partition_num=10)
函数将通过将指定的列**均匀**分割到分区数量来分区查询。ConnectorX将为每个分区分配一个线程以并行加载和写入数据。目前,我们支持对**数值**列(**不能包含 NULL**)进行**SPJA**查询的分区。
安装
pip install connectorx
有关如何从源代码构建 python 轮的详细信息,请参阅 此处。
性能
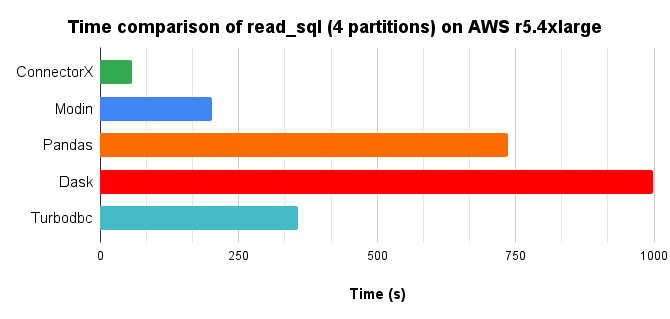
我们通过将 10 倍的 TPC-H lineitem 表(8.6GB)从 Postgres 加载到 DataFrame,并使用 4 核并行,比较了 Python 中提供 read_sql 函数的不同解决方案。
时间图表,越低越好。
内存消耗图表,越低越好。
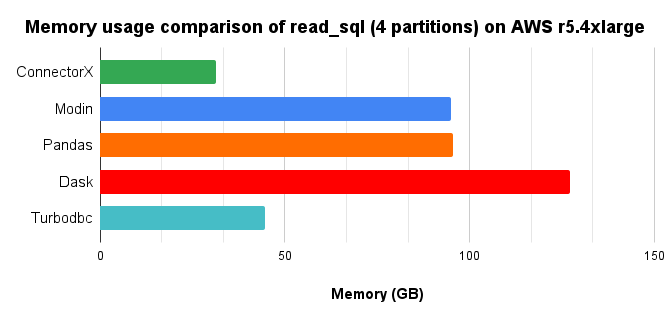
总结来说,ConnectorX最多节省3倍的内存和21倍的时间(与Pandas相比,节省3倍内存和13倍时间)。更多内容请访问这里。
ConnectorX是如何在保持内存占用低的同时实现闪电般速度的?
我们观察到,现有的解决方案在下载数据时,或多或少都会多次进行数据复制。此外,在Python中实现数据密集型应用程序还会带来额外的开销。
ConnectorX是用Rust编写的,遵循“零复制”原则。这使得它能够充分利用CPU,成为缓存和分支预测友好的程序。此外,ConnectorX的架构确保数据只会被复制一次,直接从源到目的地。
ConnectorX是如何下载数据的?
在接收到查询,例如SELECT * FROM lineitem后,ConnectorX首先发送一个LIMIT 1查询SELECT * FROM lineitem LIMIT 1以获取结果集的模式。
然后,如果指定了partition_on,ConnectorX将发送SELECT MIN($partition_on), MAX($partition_on) FROM (SELECT * FROM lineitem)以确定分区列的范围。之后,原始查询将根据最小/最大信息拆分为分区,例如SELECT * FROM (SELECT * FROM lineitem) WHERE $partition_on > 0 AND $partition_on <="tt class="const-num const-num-int">10000以获取分区大小。如果没有指定分区,ConnectorX将执行全表扫描以获取分区大小。
然后,ConnectorX将执行分区查询以下载数据。执行计划包括以下步骤:
下载开始后,每个分区将有一个线程,以便在分区级别并行下载数据。线程将向数据库发出对应分区的查询,然后将返回的数据以流式的方式写入目标,按行或按列(取决于数据库)。
支持的源和目标
示例连接字符串、每个数据源支持的协议和数据类型可以在这里找到。
有关更多计划中的数据源,请查看我们的讨论。
源
- Postgres
- Mysql
- Mariadb(通过mysql协议)
- Sqlite
- Redshift(通过postgres协议)
- Clickhouse(通过mysql协议)
- SQL Server
- Azure SQL Database(通过mssql协议)
- Oracle
- Big Query
- Trino
- ODBC(进行中)
- ...
目标
- Pandas
- PyArrow
- Modin(通过Pandas)
- Dask(通过Pandas)
- Polars(通过PyArrow)
文档
文档:https://sfu-db.github.io/connector-x/intro.html Rust文档:稳定版 夜间版
下一计划
查看我们的讨论,参与决定我们的下一个计划!
历史基准结果
https://sfu-db.github.io/connector-x/dev/bench/
开发者指南
请参阅开发者指南以获取有关开发ConnectorX的信息。
支持
您随时欢迎
- 在我们的github 讨论中提问和提出新想法。
- 在stackoverflow上提问。请确保附上#connectorx。
使用ConnectorX的组织和项目
![]()
![]()

要在此处添加您的项目/组织,请回复我们的帖子这里
引用ConnectorX
如果您使用ConnectorX,请考虑引用以下论文
Xiaoying Wang,Weiyuan Wu,Jinze Wu,Yizhou Chen,Nick Zrymiak,Changbo Qu,Lampros Flokas,George Chow,Jiannan Wang,Tianzheng Wang,Eugene Wu,Qingqing Zhou. ConnectorX:加速从数据库到Dataframes的数据加载。 VLDB 2022.
BibTeX条目
@article{connectorx2022,
author = {Xiaoying Wang and Weiyuan Wu and Jinze Wu and Yizhou Chen and Nick Zrymiak and Changbo Qu and Lampros Flokas and George Chow and Jiannan Wang and Tianzheng Wang and Eugene Wu and Qingqing Zhou},
title = {ConnectorX: Accelerating Data Loading From Databases to Dataframes},
journal = {Proc. {VLDB} Endow.},
volume = {15},
number = {11},
pages = {2994--3003},
year = {2022},
url = {https://www.vldb.org/pvldb/vol15/p2994-wang.pdf},
}
贡献者











































依赖
~7–38MB
~704K SLoC