1个不稳定版本
| 0.0.1 | 2024年5月13日 |
|---|
#19 在 #compiler-error
410KB
5.5K SLoC
Cabin
警告:Cabin处于预alpha阶段。它仍在积极开发中,甚至对小或实验性项目也无法正常工作。注意,未勾选的项目可能是目前尚未完成,甚至尚未开始。
一个非常简单、性能卓越且极其安全的编程语言。
哲学与动机
Cabin有三个“核心价值”
- 简单性
- 安全性
- 性能
最重要的是,Cabin旨在成为一个非常简单的语言,任何人都可以几乎在没有任何时间的情况下学习,同时不牺牲性能或安全性。
Cabin旨在填补这三个价值的“空白”
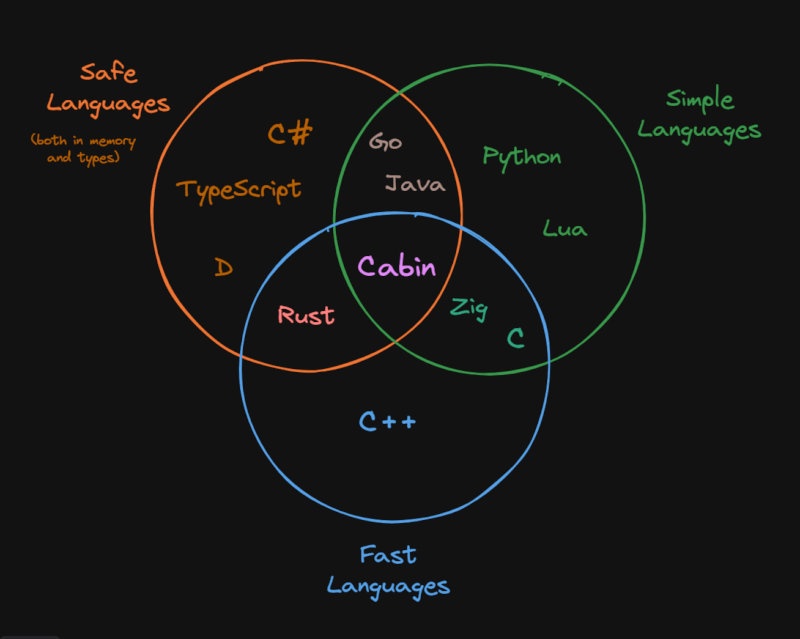
还有其他尝试填补这个空白,例如Nim和V。这只是其中之一。
Cabin主要受Lua、Rust、Go、Zig和V的启发。
优点
Cabin有几个特性使其具有吸引力。以下只是其中一些示例。
工具
默认情况下,Cabin编译器附带您在语言中感到舒适所需的所有工具
- 项目创建器:创建带有设置配置文件和源文件夹的新Cabin项目。
- 运行器:运行Cabin代码而不输出任何永久文件
- 编译器:将Cabin代码编译为本机二进制可执行文件
- 格式化器:将Cabin代码格式化为单一统一风格
- 转译器:将Cabin代码转译为C
- 检查器:提供包括错误、警告、提示和信息在内的代码诊断。
- 包管理器:管理Cabin依赖项,发布cabin包等。
这些工具的详细文档如下。此外,Cabin的语言支持扩展适用于大多数流行的文本编辑器
- Visual Studio Code: vscode-cabin
- Neovim: cabin.nvim
- 可用的Cabin语言服务器在
mason.nvim - Cabin treesitter解析器通过
nvim-treesitter提供
- 可用的Cabin语言服务器在
- Vim: vim-cabin
详细且易于阅读的错误
Cabin在命令行生成非常详细且易于阅读的错误
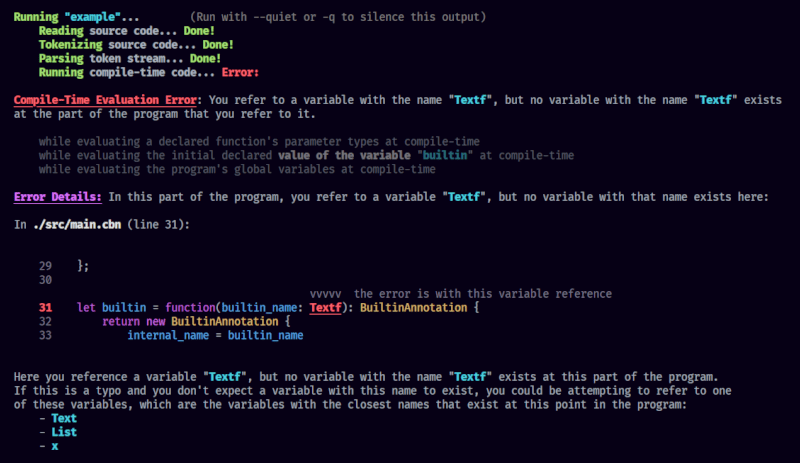
以下是一个示例
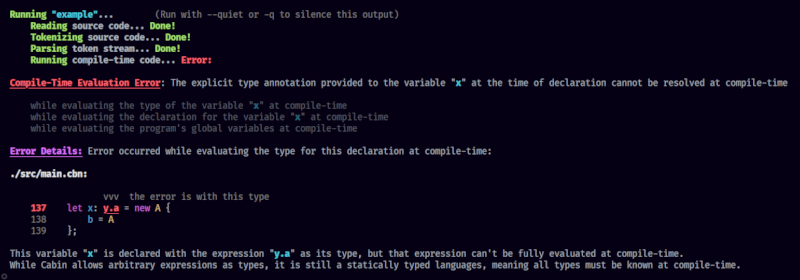
错误显示了发生的情况,包括编译器在这一点之前所执行的操作的跟踪。此外,还提供了一个带颜色的代码片段,显示错误的地点,该地点在代码中以粗体、下划线并加红色高亮显示,同时用一些箭头指向错误的位置。错误还显示了相对于项目根目录发生错误的文件,并以粗体红色显示错误发生的行号。最后,列出了更详细的错误解释,包括当可能时如何修复它的建议。
Cabin 通过标志允许更多“结构化”的错误——即以 JSON 或 TOML 等格式打印的错误。这主要用于将 Cabin 错误集成到 IDE 和 linter 中作为诊断。默认格式化模式是可读的,将输出上述内容。
无垃圾回收的思考不周的内存管理
Cabin 并没有为开发者提供内存语义。也就是说,内存不是通过类似 malloc 或 free 这样的方式手动管理的,没有所有者或借用语义等。然而,Cabin 并不是垃圾回收的。Cabin 在编译时而不是运行时拥有其自己的系统来决定何时需要清理变量。你可以将其视为“编译时垃圾回收”——这意味着你得到了垃圾回收的好处(不需要担心内存管理),而没有性能损失。
默认为编译时
Cabin 有一种独特的功能,能够在编译时运行代码。然而,与大多数具有此功能的其他语言(如 Zig 的 comptime 或 Jai 的 #run)不同,Cabin 默认在编译时运行代码。这意味着如果代码 可以 在编译时运行,它就会运行。这意味着 Cabin 可以报告其他语言通常完全无法检测到的错误,并且自动优化以获得最佳运行时性能。
当然,如果你想在运行时执行某些操作,如写入文件,你可以使用 run 关键字强制执行,在这种情况下,它会看起来像这样:run write_file(filename, contents)。运行关键字强制其后的表达式(但不是其子表达式!)在运行时而不是编译时运行。Cabin 可以 在编译时写入文件,但你可能不希望这样做,所以这就是你使用 run 表达式的地方。一些函数,包括 write_file,被标记为 #[runtime_preferred];在编译时调用这些函数将给出一个(可抑制的)警告,表明你正在调用通常在运行时使用的编译时函数。
你可以将“可以在编译时运行的”看作是一棵树——传递给 Cabin 程序的命令行参数在编译时是未知的。因此,依赖于这些参数的表达式在编译时也不会被评估。依赖于那些表达式结果的表达式也不会在编译时评估,依此类推。任何不依赖于用户输入的表达式都可以,并且将在编译时评估。
与Zig相比,Cabin在编译时代码的一个优点是,Cabin使用统一的API来运行编译时代码和运行时代码。例如,在Zig中,要在编译时读取一个文件,你使用@embedFile,但要在运行时读取文件,你做类似以下操作:try std.fs.cwd().openFile(filename, .{});然后从那里使用读取器读取它。在Cabin中,API是相同的:您可以使用read_file(filename)在编译时或运行时读取文件,这只是一个普通的Cabin函数,就像Cabin中的所有函数一样,可以在运行时或编译时调用。这意味着您不需要记住两种不同方式做同样的事情。
工具参考
默认情况下,Cabin编译器附带以下工具
- 项目创建器:创建带有设置配置文件和源文件夹的新Cabin项目。
- 运行器:运行Cabin代码而不输出任何永久文件
- 编译器:将Cabin代码编译为本机二进制可执行文件
- 格式化器:将Cabin代码格式化为单一统一风格
- 转译器:将Cabin代码转译为C
- 检查器:提供包括错误、警告、提示和信息在内的代码诊断。
- 包管理器:管理Cabin依赖项,发布cabin包等。
运行器
使用cabin run <filename.cbn>可以运行单个Cabin文件。在底层,这会将代码转换为C语言,将其存储在临时文件中,将C代码转换为本地可执行文件,将其存储在临时文件中,然后运行本地可执行文件并删除这两个文件。这使得可以在没有特定位置保存代码的情况下运行代码。
如果使用cabin run而没有文件名作为参数,它将假定您处于Cabin项目中,并运行该项目,使用配置文件(./cabin.toml)和将src/main.cbn作为要运行的源文件。
选项
--quiet或-q[bool]:以“安静”模式运行cabin文件。这将不会打印解析或词法分析进度更新,但会打印错误。--emit-c或-c[filename]:将转换后的C代码输出到指定的文件。
编译器
使用cabin build <filename.cbn> <output>将单个Cabin文件编译成本地二进制可执行文件。在底层,这会将Cabin代码转换为C语言,编译C代码到本地可执行文件(在<output>),然后删除临时C文件。如果没有为<output>提供参数,则默认命名输出文件<filename>(无.cbn的源文件名)并将其放置在源文件相同的目录中。
如果使用cabin build而没有额外的参数,它将假定您处于Cabin项目中,并构建该项目,使用配置文件(./cabin.toml)和将src/main.cbn作为要构建的主文件。
选项
--quiet或-qbool:以“安静”模式运行 cabin 文件。这不会打印解析或词法分析进度更新,但会打印错误。--emit-c或-c[filename]:将转换后的C代码输出到指定的文件。
格式化工具
Cabin 内置了一个无偏见的格式化工具,使用 cabin format <filename.cbn>。这将格式化单个 Cabin 文件。运行 cabin format 而不指定文件参数将假定您正在 Cabin 项目中,并将格式化项目中的所有文件。没有可以传递以自定义格式的选项,这是设计决定的。所有 Cabin 代码看起来都一样。
--quiet或-qbool:以“安静”模式运行 cabin 文件。这不会打印解析或词法分析进度更新,但会打印错误。
转换器
Cabin 可以转换为 C 代码。这不会是漂亮的 C 代码,但足以让人阅读。这通过 cabin transpile <filename.cbn> <output.c> 实现,它将 filename.cbn 中的代码转换为等价的 C 代码,并将其输出到 <output.c>。如果没有指定输出,文件将命名为 filename.c(原始源文件名,但使用 .c 扩展名而不是 .cbn)。
选项
--quiet或-qbool:以“安静”模式运行 cabin 文件。这不会打印解析或词法分析进度更新,但会打印错误。--tolanguage:将 Cabin 转换为指定的语言。目前只支持 C 语言。
代码检查器
Cabin 通过 cabin check 内置了一个代码检查器。Cabin 代码检查器有两个可以切换的模式:开发者模式和发布模式。开发者模式提供基本的代码检查,如编译器错误。发布模式提供针对生产就绪代码的全面代码检查,包括诸如缺少文档等琐碎的问题。开发者模式是代码检查器的默认模式,在许多 IDE 和文本编辑器中,您可以通过快捷键在这两种模式之间切换。
选项
--mode或-m["develop" | "release"]:用于检查项目的模式。--format["json" | "toml" | "yaml" | "human"](默认“human”):输出结果的格式。传递“human”(默认值)将输出美观、易于阅读的诊断信息。为了获得 IDE 集成所需的结构化诊断信息,请使用json、toml或yaml。
包管理器
Cabin 工具链包含几个用于包管理的命令
cabin add <package>- 向包添加依赖项。--version或-v- 添加特定版本的依赖项
cabin remove <package>- 从包中删除依赖项。cabin publish- 发布包。选项--major或-M- 自动将版本号增加 1.0.0--minor或-m- 自动将版本号增加 0.1.0--patch或-p- 自动将版本号增加 0.0.1
限制
虽然Cabin的设计旨在提供某些特定的好处,但其中一些也伴随着缺点。以下列举了一些。
无缓存
每次都需要重新编译您的代码,即使它完全未更改。嗯,不完全是这样——我们可以在编译时评估之后跳过所有内容(这是将代码转换为C代码并编译C代码),但程序始终需要重新分词和解析,即使它未更改。大多数语言可以存储二进制可执行文件并检查您的程序是否未更改,然后只需重新运行可执行文件即可。然而,在Cabin中,最终的二进制可执行文件不包含有关程序的所有信息——特别是编译时代码。例如,如果您的代码在编译时打印某些内容,这不会出现在最终的执行文件中,并且在第二次运行相同的代码时会产生不同的结果,因为编译时代码不会运行且不会打印任何内容。这比缓存的价值更大,所以目前我们无法完全缓存预编译程序。
但这并非不可能;从理论上讲,我们可以序列化解析后的抽象语法树(AST),然后在程序未更改的情况下将其反序列化为代码中的AST,但这并不是我们的首要任务。序列化很复杂,因为AST具有递归性质,而且还没有确凿的证据表明它总是比重新编译更快(读取序列化文件并将数据解析为AST比直接分词和解析代码更快吗?谁说得准呢?)。所以,目前这并不是我们的首要任务,而且即使代码与上次运行完全相同,每次运行时也必须从头开始完全重新编译代码。
基于用户的条件编译
编译后的可执行文件可能因编译时的用户输入而不同。例如,您可以在编译时调用terminal.input函数,并在编译时对结果进行处理,生成的可执行文件对于不同的人编译的结果可能不同。因此,一些函数如terminal.input被标记为#[runtime_only],这意味着如果它在编译时而不是在运行时被调用,编译器会发出警告。然而,这只是一个警告,而不是错误。Cabin关于简单性的哲学理念是不要做出特殊例外,因此所有函数都可以在编译时运行,包括如terminal.input这样的函数。警告会阻止编译,但不会阻止根据用户输入或用户的编译环境(如编译时读取文件)编译不同的可执行文件。可能存在问题的函数,如terminal.input和file.read,被标记为#[runtime_only]以阻止在编译时运行。
C编译速度受限于C
目前(可能永远不是这样),Cabin在编译为本地二进制文件之前先编译为C。这意味着无论编译器多么优化,它编译的速度至少会比C慢(在编译方面)。这不是一个大问题,因为现代C编译器已经非常优化,速度很快,但值得注意的是,目前存在这个严格的下限,并且在使用当前的编译系统的情况下,Cabin永远不可能在这个领域超过C。
依赖项
~7–18MB
~251K SLoC