6 个版本 (3 个重大变更)
使用旧的 Rust 2015
| 0.5.1 | 2017年11月20日 |
|---|---|
| 0.5.0 | 2017年11月17日 |
| 0.4.0 | 2017年11月2日 |
| 0.3.1 | 2017年5月16日 |
| 0.2.2 | 2017年5月4日 |
在 #spmc 中排名第 13
每月下载量 21 次
17KB
127 行
针对活动突发优化的线程池。
设计用于以下用例:单个线程产生工作,然后必须由工作线程池执行。工作产生不频繁,但会在短时间内集中产生。因此,在正常操作中,池中的线程会睡眠,直到某个事件需要它们突然醒来。这些线程在再次睡眠之前会执行一些工作。
有关详细信息,请参阅文档。
lib.rs:
一个具有低、一致延迟的 SPMC 通道,适用于值批量到达且必须立即处理的场景。
burst-pool 与常规 spmc 通道的主要区别在于:当所有工作线程都忙时,发送失败。这允许发送者尽可能多地分配工作,然后以不同的方式处理溢出工作(可能通过丢弃)。
性能
tl;dr: 与 spmc 大致相同。当工作线程数量少于核心数量时表现最佳。
我正在使用出色的 spmc 包作为基准。spmc 提供了一个可靠的不可限定通道,并且当池过载时,它具有正常的“队列”语义(与 burst-pool 的“返回给发送者”语义相反)。我们关心的指标是 enqueue→recv 延迟。以下是核密度估计。标签中的“n/m”表示“向 m 个工作线程发送 n 条消息”。
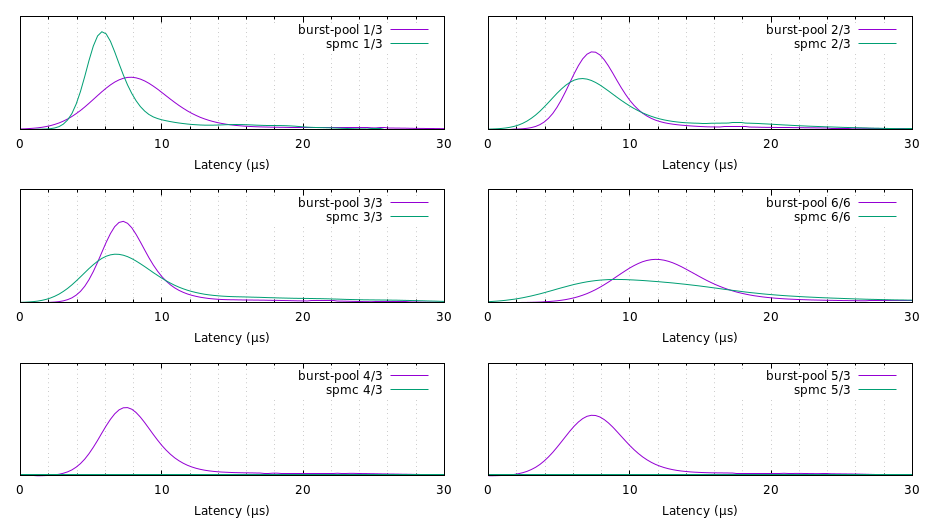
以下是我对这些数字的解释
- 将工作线程数量固定为 3 并更改发送的消息数量似乎对 burst-pool 的性能没有影响。另一方面,当池利用率低(1/3)时,spmc 的表现有可比性,但随着消息数量的增加(2/3)而逐渐变差,直到在饱和情况下(3/3)与 burst-pool 大致相同。
- 当池过载(4/3,5/3)时,我们看到两个包的语义差异。在 burst-pool 基准测试中,只发送了 3 条消息,其中 2 条被丢弃。在 spmc 基准测试中,所有 5 条消息都被发送,产生了一个双峰分布,第二个峰值约为 1000 μs。(这似乎会搞乱 gnuplot。)
- 比较两个饱和基准测试(3/3,6/6),我们看到另一个差异。当工作线程数量少于可用核心数量(3/3)时,我们看到性能大致相同,但 burst-pool 在超出核心数量(6/6)时退化得更差。
- 响应时间通常比 spmc 更可靠(即方差更低),除了 1/3 基准测试。
这些观察结果与预期的性能特性一致。(见下文“设计”。)
运行 cargo bench 在您的机器上做一些测量;同时还有一个gnuplot脚本,您可以用它来可视化结果。(提示:如果您的结果明显比上面差很多,那么您的内核可能过于急切地关闭CPU核心。如果您更关心延迟而不是电池寿命,请考虑设置max_cstate = 0。)
用法
API需要两次调用才能实际向接收器发送消息:首先,您将消息放入您的工作者的邮箱之一(enqueue);然后唤醒工作者,通知它检查其邮箱(wake_all)。如果发送者可以找到空的邮箱来放置消息(即,至少有一个您的工作者目前正在调用recv时阻塞),则调用enqueue将成功。如果enqueue失败,您将收到您的消息。如果成功,消息将在下一次您调用wake_all时被精确地接收一次。
#
#
// Create a handle for sending strings
let mut sender: Sender<String> = Sender::new();
// Create a handle for receiving strings, and pass it off to a worker thread.
// Repeat this step as necessary.
let mut receiver: Receiver<String> = sender.mk_receiver();
let th = std::thread::spawn(move ||
loop {
let x = receiver.recv().unwrap();
println!("{}", x);
}
);
// Give the worker thread some time to spawn
sleep_ms(10);
// Send a string to the worker and unblock it
sender.enqueue(Box::new(String::from("hello")));
sender.wake_all();
sleep_ms(10); // wait for it to process the first string
// Send another string
sender.enqueue(Box::new(String::from("world!")));
sender.wake_all();
sleep_ms(10);
// Drop the send handle, signalling the worker to shutdown
std::mem::drop(sender);
th.join().unwrap_err(); // RecvError::Orphaned
设计
每个接收器都有一个“槽位”,可以是空的、阻塞的,或者包含指向某些工作的指针。每当接收器的槽位为空时,它会通过轮询eventfd来进入睡眠状态。当发出工作负载时,发送者遍历槽位,将工作负载放入空槽位中。然后,它通过信号eventfd唤醒所有睡眠的接收器。如果接收器醒来并发现其槽位中有工作负载,它将取走工作负载并阻塞其槽位。如果接收器醒来并发现其槽位仍然为空,它将返回睡眠状态。当接收器完成处理工作负载后,它将解锁其槽位。
这种设计意味着我们预计enqueue→recv延迟将独立于发送的数据包数量。然而,我们预计一旦工作者线程数量超过可用的核心数量,它就会变得非常糟糕。基准测试结果与这些预期一致。
可移植性
此crate仅适用于Linux。
依赖关系
~2MB
~39K SLoC