32个稳定版本
| 1.35.2 | 2023年9月6日 |
|---|---|
| 1.34.0 | 2023年8月13日 |
| 1.32.0 | 2023年6月1日 |
| 1.31.0 | 2022年8月17日 |
| 1.15.0 | 2017年11月23日 |
#288 在 缓存 中
每月60次下载
130KB
2.5K SLoC
Bloom
![]()
![]()
![]()
![]()
Bloom是一个REST API缓存中间件,充当负载均衡器和REST API工作进程之间的反向代理。
它对您的API实现完全无感知,并且只需对现有API代码进行最小更改即可使用。
Bloom依赖于 redis,配置为缓存存储缓存数据。它用Rust编写,专注于稳定性、性能和低资源使用。
重要:如果您要实现的API遵循REST约定,则Bloom工作得很好。您的API需要使用HTTP读取方法,即 GET、HEAD、OPTIONS 仅作为读取方法(不要使用HTTP GET参数作为更新数据的方式)。
在Rust版本 rustc 1.71.1 (eb26296b5 2023-08-03) 上进行了测试
🇫🇷 在法国布勒斯特制作。
📰 Bloom项目最初在 我的个人日志中的一篇文章 中宣布。

谁在使用它?
 |
| Crisp |
👋 您使用Bloom并希望被列在这里? 联系我。
功能
- 同一个Bloom服务器可以同时用于不同的API工作进程,使用HTTP头
Bloom-Request-Shard(例如,主API使用分片0,搜索API使用分片1)。 - 在桶上存储缓存,使用HTTP头
Bloom-Response-Buckets在您的REST API响应中指定。 - 按认证令牌分组的缓存,不可能出现跨用户的缓存泄漏,使用标准的
AuthorizationHTTP头。 - 可以直接从您的REST API工作程序中使缓存过期,通过控制通道。
- 可按请求配置缓存策略,使用请求中转发到Bloom的负载均衡器的
Bloom-Request-*HTTP头。- 使用
Bloom-Request-Shard为API系统指定缓存碎片(默认碎片是0,最大值是15)。
- 使用
- 可按响应配置缓存策略,使用您的API响应中的
Bloom-Response-*HTTP头。- 使用
Bloom-Response-Ignore(值为1)禁用API路由的所有缓存。 - 使用
Bloom-Response-Buckets为API路由指定缓存桶(如果多个桶,则逗号分隔)。 - 使用
Bloom-Response-TTL为API路由指定缓存TTL(秒)(除默认TTL外,为秒数)。
- 使用
- 向非修改路由内容提供
304 Not Modified,降低带宽使用并加快用户请求的速度。
Bloom方法
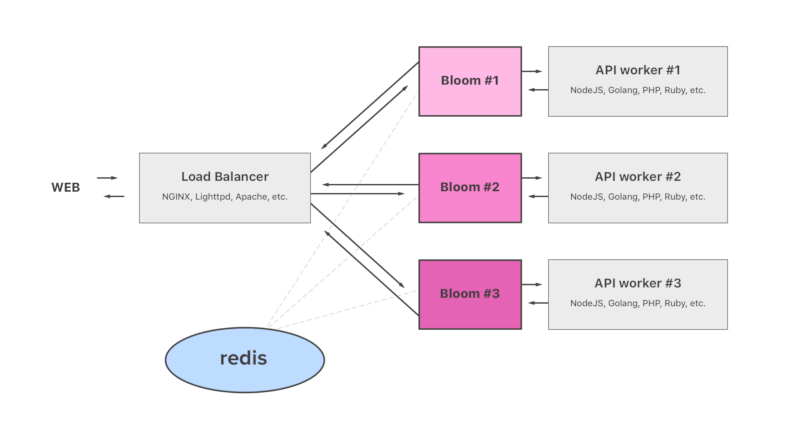
Bloom可以热插拔到位于现有负载均衡器(例如NGINX)和API工作程序(例如NodeJS)之间的位置。它最初是为了减少API流量激增或DOS/DDoS攻击时的工作负载和显著降低CPU使用而构建的。
可能有一个更简单的缓存方法,就是在负载均衡器级别为HTTP读取方法(GET、HEAD、OPTIONS)启用缓存。虽然作为一种解决方案很简单,但它不会与REST API一起工作。REST API本质上是动态内容,并且严重依赖于授权头。此外,如果由于某些数据库中的数据更新,缓存中的内容变得过时,任何缓存都需要在某个时候被清除。
你说NGINX Lua脚本可以很好地完成这项工作!但是,我坚信负载均衡器应该是简单的,并且只基于配置,而不需要脚本。由于负载均衡器是所有HTTP/WebSocket服务的入口点,你希望避免频繁的部署和自定义代码,并将缓存复杂性交给专门的中间件组件。
它是如何工作的?
Bloom安装在您的每个API工作程序的同一服务器上。从您的负载均衡器看,每个API工作程序都有一个Bloom实例。这样,您的负载均衡设置(例如,带有健康检查的轮询)不会被破坏。每个Bloom实例都可以设置为从其自己的LAN IP可见,然后这些Bloom实例可以指向本地回环上的API工作程序监听器。
Bloom充当自己的反向代理,并缓存读取HTTP方法(GET、HEAD、OPTIONS),而直接代理HTTP写入方法(POST、PATCH、PUT和其他方法)。所有Bloom实例共享LAN上可用的公共 redis 实例上的相同缓存存储。
Bloom是用Rust编写的,以确保内存安全、代码优雅,尤其是性能。Bloom可以编译成适用于您的服务器架构的本地代码。
布隆(Bloom)具有最小的静态配置,并依赖于您的API工作者提供的HTTP响应头来按响应配置缓存。这些HTTP头被布隆拦截,不会发送到您的负载均衡器响应。这些头部的格式为Bloom-Response-*。在向您的负载均衡器提供响应时,布隆设置一个缓存状态头,即Bloom-Status,可以在HTTP响应中公开看到(值可以是HIT、MISS或DIRECT——它有助于调试您的缓存配置)。
如何使用它?
安装
布隆是用Rust编写的。要安装它,可以从布隆发布页面下载版本,使用cargo install或从master拉取源代码。
👉 每个发布二进制文件都包含一个.asc签名文件,可以使用@valeriansaliou GPG公钥进行验证:🔑valeriansaliou.gpg.pub.asc。
从源代码安装
如果您已从Git拉取源代码,可以使用cargo构建它。
cargo build --release
构建的二进制文件可以在./target/release目录中找到。
从Cargo安装
您可以直接使用cargo install安装布隆。
cargo install bloom-server
请确保您的$PATH已正确配置为源Crate二进制文件,然后使用bloom命令运行布隆。
从软件包安装
Debian和Ubuntu软件包也可用。请参阅如何在Debian & Ubuntu上安装?部分。
从Docker Hub安装
您可能发现通过Docker运行布隆更方便。您可以在Docker Hub上找到预构建的布隆镜像,名为valeriansaliou/bloom。
首先,拉取valeriansaliou/bloom镜像
docker pull valeriansaliou/bloom:v1.35.2
然后,提供一个配置文件并运行它(将/path/to/your/bloom/config.cfg替换为您配置文件的路径)
docker run -p 8080:8080 -p 8811:8811 -v /path/to/your/bloom/config.cfg:/etc/bloom.cfg valeriansaliou/bloom:v1.35.2
在配置文件中,请确保
server.inet设置为0.0.0.0:8080(这允许布隆从容器外部访问)control.inet设置为0.0.0.0:8811(这允许布隆控制从容器外部访问)
布隆可以通过https://:8080访问,布隆控制可以通过tcp://localhost:8811访问。
配置
使用示例配置文件config.cfg并调整到您自己的环境。
请确保正确配置 [proxy] 部分,以便 Bloom 指向您的 API 工作主机和端口。
可用选项
以下是对可用配置选项的注释,包括允许的值
[server]
log_level(类型:字符串,允许:debug,info,warn,error,默认:error) — 日志的详细程度,在生产环境中设置为errorinet(类型:字符串,允许:IPv4 / IPv6 + 端口,默认:[::1]:8080) — Bloom 服务器应监听的宿主机和 TCP 端口
[control]
inet(类型:字符串,允许:IPv4 / IPv6 + 端口,默认:[::1]:8811) — Bloom 控制应监听的宿主机和 TCP 端口tcp_timeout(类型:整数,允许:秒,默认:300) — 空闲/死客户端连接到 Bloom 控制的超时时间
[proxy]
shard_default(类型:整数,允许:0到15,默认:0) — 在代理 HTTP 请求中没有指定分片时使用的默认分片索引
shard(类型:整数,允许:0到15,默认:0) — 分片索引(在请求 Bloom 时通过Bloom-Request-Shard路由)host(类型:字符串,允许:主机名,IPv4,IPv6,默认:localhost) — 要代理到该分片的目标宿主机(即 API 监听的位置)port(类型:整数,允许:TCP 端口,默认:3000) — 要代理到该分片的目标 TCP 端口(即 API 监听的位置)
[cache]
ttl_default(类型:整数,允许:秒,默认:600) — 默认缓存 TTL(秒),当没有提供Bloom-Response-TTL时executor_pool(类型:整数,允许:0到(2^16)-1,默认:16) — 缓存执行器池大小(可以同时执行多少个缓存请求)disable_read(类型:布尔值,允许:true,false,默认:false) — 是否禁用缓存读取(对测试很有用)disable_write(类型: 布尔型, 允许值:true,false, 默认值:false) — 是否禁用缓存写入(适用于测试)compress_body(类型: 布尔型, 允许值:true,false, 默认值:true) — 在存储时是否压缩正文(使用 Brotli;通常可以减少正文大小40%)
[redis]
host(类型: 字符串, 允许值: 主机名,IPv4,IPv6,默认值:localhost) — 目标 Redis 主机port(类型: 整数, 允许值: TCP 端口,默认值:6379) — 目标 Redis TCP 端口password(类型: 字符串, 允许值: 密码值,默认值: 无) — Redis 密码(如果没有密码,不要设置此键)database(类型: 整数, 允许值:0到255,默认值:0) — 目标 Redis 数据库pool_size(类型: 整数, 允许值:0到(2^32)-1,默认值:80) — Redis 连接池大小(应略高于cache.executor_pool,因为它同时被 Bloom 代理和 Bloom 控制使用)max_lifetime_seconds(类型: 整数, 允许值: 秒,默认值:60) — Redis 连接的最大存活时间(你希望它小于5分钟,因为这会影响连接断开后的重连延迟)idle_timeout_seconds(类型: 整数, 允许值: 秒,默认值:600) — 空闲/死亡连接池连接到 Redis 的超时时间connection_timeout_seconds(类型: 整数, 允许值: 秒,默认值:1) — 超时时间,在秒内认为 Redis 已死,并发出一个不使用缓存而直接连接到 API 的DIRECT连接(保持这个值较低,因为当 Redis 不可用时,它决定了在忽略 Redis 响应并直接代理之前需要等待多长时间)max_key_size(类型: 整数, 允许值: 字节,默认值:256000) — 在 Redis 中存储键的最大数据大小(字节,防止缓存非常大的响应)max_key_expiration(类型: 整数, 允许值: 秒,默认值:2592000) — 在 Redis 中缓存的键的最大 TTL(防止错误的Bloom-Response-TTL值)
环境变量
你可以在配置文件中使用 环境变量。
这是一个使用环境变量的示例配置
[cache]
compress_body = "${BLOOM_COMPRESS_BODY}"
[redis]
host = "${BLOOM_REDIS_HOST}"
然后,你可以运行 Bloom,提供所有已声明的环境变量
BLOOM_REDIS_HOST=localhost BLOOM_COMPRESS_BODY=false \
./bloom -c /path/to/config.cfg
注意:它只能用于字符串和布尔值
运行 Bloom
Bloom 可以这样运行
./bloom -c/path/to/config.cfg
重要:确保为你的基础设施上运行的每个 API 工作进程启动一个 Bloom 实例。Bloom 本身不管理负载均衡逻辑,因此你应该为每个 API 工作进程实例有一个 Bloom 实例,并且仍然依赖于例如 NGINX 进行负载均衡。
配置负载均衡器
一旦Bloom启动并指向您的API,您就可以配置您的负载均衡器指向Bloom IP和端口(而不是之前指向的API IP和端口)。
NGINX说明
➡️ 配置现有的代理规则集
Bloom需要您的负载均衡器在代理客户端请求到Bloom时设置Bloom-Request-Shard HTTP头。此头告诉Bloom使用哪个缓存分片来存储数据(这样,您可以有一个用于不同API子系统的单个Bloom实例,它们在同一服务器上监听)。
# Your existing ruleset goes here
proxy_pass http://(...)
# Adds the 'Bloom-Request-Shard' header for Bloom
proxy_set_header Bloom-Request-Shard 0;
➡️ 调整现有的CORS规则(如果使用的话)
如果您的API运行在专用的主机名上(例如,https://api.crisp.chat是Crisp),请不要忘记相应地调整您的CORS规则,以便API Web客户端(即浏览器)可以利用Bloom添加的ETag头。这将有助于在较慢的网络中加快API读取请求。 如果您没有现有的CORS规则,您可能不需要它们,所以忽略此条。
# Merge those headers with your existing CORS rules
add_header 'Access-Control-Allow-Headers' 'If-Match, If-None-Match' always;
add_header 'Access-Control-Expose-Headers' 'Vary, ETag' always;
请注意,分片号是0到15的整数(8位无符号数,限制为16个分片)。
Bloom添加的响应头包括
浏览器添加的请求头,这是由于Bloom添加了上述请求头的结果
请注意,您需要将新的请求和响应头都添加到您的CORS规则中。如果您忘记了任何一个,对您的API的请求可能会在某些浏览器(例如,使用PATCH请求的Chrome)上开始失败。
配置您的API
现在,Bloom在您的API前面运行并在其 behalf 上提供服务;您的API可以指导Bloom如何根据每个响应的行为。
您的API可以向Bloom发送私有HTTP头,这些头由Bloom使用并在发送给请求客户端的响应中删除(Bloom-Response-* HTTP头)。
请注意,您的API不应以压缩格式提供响应。请禁用应用程序服务器上的任何Gzip或Brotli中间件,因为Bloom无法解码压缩的响应体。动态内容的压缩应由负载均衡器本身处理。
➡️ 不要缓存响应
要告诉Bloom不要缓存响应,将以下HTTP头作为API响应的一部分发送
Bloom-响应-忽略: 1
默认情况下,Bloom保留所有安全缓存的响应,只要它们匹配以下两个条件
1. 可缓存方法
GETHEADOPTIONS
2. 可缓存状态
OKNon-Authoritative InformationNo ContentReset ContentPartial ContentMulti-StatusAlready ReportedMultiple ChoicesMoved PermanentlyFoundSee OtherPermanent RedirectUnauthorizedPayment RequiredForbiddenNot FoundMethod Not AllowedGoneURIToo LongUnsupported Media Type范围不满足期望失败I‘m一壶茶锁定失败依赖需要前置条件请求头字段过大未实现未扩展
如需查找匹配的状态码,请参阅维基百科上的状态码列表。
➡️ 在响应缓存上设置过期时间
要告诉Bloom在响应缓存上使用特定的过期时间(缓存失效后的时间,客户端请求时将获取新的响应),请将以下HTTP头作为API响应的一部分发送(此处为60秒的TTL)
Bloom-响应-TTL: 60
默认情况下,Bloom设置TTL为600秒(10分钟),但可以通过config.cfg进行配置。
➡️ 标记缓存响应(用于Bloom控制缓存清除)
如果您想使用Bloom控制来程序化清除缓存响应(见缓存能否程序化过期?),则需要在这些响应被缓存时进行标记。您可以告诉Bloom在1个或多个桶中对缓存响应进行标记,如下所示
Bloom-响应-桶:user_id:10012,heavy_route:1203
然后,当您需要清除标识为10012的用户标记的响应时,可以在user_id:10012桶上调用Bloom控制缓存清除。对于heavy_route:1203桶的操作流程类似。
默认情况下,缓存响应没有标签,因此无法通过Bloom控制直接清除。
如何在Debian & Ubuntu上安装它?
Bloom为基于Debian的系统(Debian、Ubuntu等)提供了预构建包。
重要提示:Bloom目前只提供针对Debian 10、11 & 12的64位包(代号:buster、bullseye & bookworm)。您仍然可以在其他Debian版本以及Ubuntu上使用它们。
1️⃣ 添加Bloom APT仓库(例如,对于Debian bookworm)
echo "deb [signed-by=/usr/share/keyrings/valeriansaliou_bloom.gpg] https://packagecloud.io/valeriansaliou/bloom/debian/ bookworm main" > /etc/apt/sources.list.d/valeriansaliou_bloom.list
curl -fsSL https://packagecloud.io/valeriansaliou/bloom/gpgkey | gpg --dearmor -o /usr/share/keyrings/valeriansaliou_bloom.gpg
apt-get update
2️⃣ 安装Bloom包
apt-get install bloom
3️⃣ 编辑预填充的Bloom配置文件
nano /etc/bloom.cfg
4️⃣ 重新启动Bloom
service bloom restart
它有多快、多轻量?
Bloom是用Rust编写的,可以编译为您的架构的本地代码。与Golang等相比,Rust不携带GC(垃圾收集器),这对于高吞吐量/高负载的生产系统通常是个坏消息(因为GC会暂停所有程序指令执行一段时间,这取决于内存中保留的引用数量)。
请注意,Bloom在内存管理方面做出了一些妥协。为了简化,大量使用了堆分配对象。即您的API工作者的响应在发送给客户端之前完全缓存在内存中;这有好处,即可以从您的API工作者尽可能快地清除数据,即使请求客户端的带宽非常慢。
在Crisp的生产环境中,我们运行了多个Bloom实例(每个API工作者一个)。每个实例处理约250个HTTP RPS(每秒请求数),以及约500个Bloom控制RPS(例如,缓存清除)。每个Bloom实例运行在单个2016 Xeon vCPU上,配以512MB RAM。Bloom处理的HTTP请求在读取(GET、HEAD、OPTIONS)和写入(POST、PATCH、PUT以及其他)之间平衡。
在如此负载下运行Bloom的服务器获得了以下htop反馈

如您所见,Bloom 只消耗CPU时间的很小一部分(不到5%)和很小的RAM占用(大约5%,即大约25MB)。在这样的小型服务器上,我们可以预测Bloom可以扩展到更高的速率(例如,10k RPS),而不会对系统造成太大压力(底层NodeJS API工作进程会首先过热,因为它比Bloom重得多)。
如果您希望Bloom处理非常高的RPS,请确保将cache.executor_pool和redis.pool_size选项调整到更高的值(如果您的Redis链接有少量延迟,这可能会限制您的RPS - 因为Redis连接是阻塞的)。
它是如何处理认证路由的?
认证路由通常由REST API用于返回请求者用户的私有数据。由于Bloom是一个缓存系统,防止从认证路由中发生缓存泄漏至关重要。Bloom通过为发送HTTP Authorization头部的请求隔离缓存来轻松解决这个问题。这是默认的安全行为。
如果请求的路由没有HTTP Authorization头(即请求是匿名/公开的),无论HTTP响应代码如何,Bloom都会将该响应缓存起来。
由于您的HTTP Authorization头包含敏感的认证数据(例如,用户名和密码),Bloom将这些值以散列形式存储在redis中(使用加密散列函数)。这样,即使您的redis数据库泄露,攻击者也无法恢复认证密钥对。
缓存可以被程序性地过期吗?
是的。由于您的现有API工作进程已经在他们的端执行数据库更新,因此它们已经非常清楚哪些数据 - 可能会被Bloom缓存 - 已过时。因此,Bloom提供了一种有效的方法来告诉它过期给定桶的缓存。这个系统被称为Bloom Control。
Bloom可以配置为监听TCP套接字以公开缓存控制接口。默认TCP端口是8811。Bloom实现了一个基本的命令-确认协议。
这样,您的API工作进程(或您的基础设施中的任何其他工作进程)都可以告诉Bloom
- 过期给定桶的缓存。请注意,由于给定的桶可能包含不同HTTP
Authorization头部的缓存变体,当您清除桶的缓存时,会同时清除所有身份验证令牌的桶缓存。 - 过期给定HTTP
Authorization头部的缓存。如果用户注销并撤销他们的身份验证令牌,这很有用。
➡️ 可用命令
FLUSHB <namespace>:清除给定桶命名空间的缓存FLUSHA <authorization>:清除给定授权的缓存SHARD <shard>:选择要使用的连接分片PING:ping服务器QUIT:停止连接
⬇️ 控制流示例
telnet bloom.local 8811
Trying ::1...
Connected to bloom.local.
Escape character is '^]'.
CONNECTED <bloom v1.0.0>
HASHREQ hxHw4AXWSS
HASHRES 753a5309
STARTED
SHARD 1
OK
FLUSHB 2eb6c00c
OK
FLUSHA b44c6f8e
OK
PING
PONG
QUIT
ENDED quit
Connection closed by foreign host.
注意:在发出任何命令之前,Bloom要求客户端验证其哈希函数与Bloom内部哈希函数(使用HASHREQ和HASHRES交换)的一致性。使用FarmHash对键进行哈希,使用FarmHash.fingerprint32()计算结果,可能在不同的架构上有所不同。这样,可以预先防止大多数奇怪的Bloom Control问题。
📦 Bloom Control库
- NodeJS:node-bloom-control
👉 找不到您编程语言的库?自己构建一个并在此处引用!(《联系我》)
🔥 报告漏洞
如果您在Bloom中发现了漏洞,欢迎您直接向 @valeriansaliou 报告,通过发送加密邮件至 valerian@valeriansaliou.name。请不要在公共GitHub问题中报告漏洞,因为它们可能会被恶意人士利用来攻击运行未修补Bloom实例的生产服务器。
⚠️ 您必须使用 @valeriansaliou GPG公钥加密您的邮件:[🔑valeriansaliou.gpg.pub.asc](https://valeriansaliou.name/files/keys/valeriansaliou.gpg.pub.asc)。
依赖项
~32MB
~622K SLoC