13 个不稳定版本
| 0.7.0 | 2024年5月14日 |
|---|---|
| 0.6.2 | 2024年1月14日 |
| 0.6.1 | 2022年10月24日 |
| 0.5.1 | 2021年7月11日 |
| 0.1.0 | 2018年1月26日 |
#83 in 解析器实现
2,818 每月下载量
在 8 个crate中(4个直接) 使用
64KB
1K SLoC
Bitter
读取位直到苦涩的尽头
![]()
![]()
![]()
Bitter以平台无关的方式以所需的端序格式读取位。与其他位读取器相比,性能是其显著特点。更多信息请参见基准测试。
特性
- ✔ 支持 little endian、big endian 和 native endian 格式
- ✔ 请求任意数量的位(最多64位)和字节
- ✔ 便于请求常见数据类型(例如:
u8...u64,f64,等等) - ✔ 多吉比特每秒吞吐量最快的位读取器
- ✔ 无分配、无依赖和无 panic
- ✔
no_std兼容
使用自动模式快速开始
以下示例很好地展示了主要API表面区域以解码16位数据模型。它在易用性和速度之间取得了良好的平衡。
use bitter::{BitReader, LittleEndianReader};
let mut bits = LittleEndianReader::new(&[0xff, 0x04]);
assert_eq!(bits.bytes_remaining(), 2);
assert_eq!(bits.read_bit(), Some(true));
assert_eq!(bits.bytes_remaining(), 1);
assert_eq!(bits.read_u8(), Some(0x7f));
assert!(bits.has_bits_remaining(7));
assert_eq!(bits.read_bits(7), Some(0x02));
以“read_”前缀命名的函数俗称为“自动模式”,因为不需要管理预览缓冲区中的底层位。
手动模式
可以通过利用编码数据中的模式来摊销内部状态逻辑管理,从而解锁额外的性能。我们可以将前面的示例重写,以利用我们将要解码16位的领域知识。
use bitter::{BitReader, LittleEndianReader};
let mut bits = LittleEndianReader::new(&[0xff, 0x04]);
// ... snip code that may have read some bits
// We first check that there's enough total bits
if !bits.has_bits_remaining(16) {
panic!("not enough bits remaining");
}
// Despite there being enough data, the lookahead buffer may not be sufficient
if bits.lookahead_bits() < 16 {
bits.refill_lookahead();
assert!(bits.lookahead_bits() >= 16)
}
// We use a combination of peek and consume instead of read_*
assert_eq!(bits.peek(1), 1);
bits.consume(1);
// Notice how the return type is not an `Option`
assert_eq!(bits.peek(8), 0x7f);
bits.consume(8);
// We can switch back to auto mode any time
assert!(bits.has_bits_remaining(7));
assert_eq!(bits.read_bits(7), Some(0x02));
填充、预览和消费组合是手动模式的基本构建块,允许对热循环进行细粒度管理。手动模式API的表面区域有意保持紧凑,以保持简单。自动模式API更大,因为该API应该是首选。
手动模式和自动模式之间的一个主要区别是,不能预览超过预览缓冲区中的内容。由于预览缓冲区将在 MAX_READ_BITS 和 63 位之间变化,因此需要编写逻辑来将超过 MAX_READ_BITS 的预览在选择的端序中拼接起来。
手动模式可能会让人感到畏惧,但它可能是解码比特流最快的方式之一,因为它基于Fabian Giesen关于阅读比特的出色系列文章中的第4个变体。[阅读原文](https://fgiesen.wordpress.com/2018/02/20/reading-bits-in-far-too-many-ways-part-2/)。其他人也采用了这种底层技术来[显著加速DEFLATE](https://dougallj.wordpress.com/2022/08/20/faster-zlib-deflate-decompression-on-the-apple-m1-and-x86/)。
以下是一个手动模式读取60比特的示例
use bitter::{BitReader, LittleEndianReader};
let data: [u8; 8] = [0xab, 0xcd, 0xef, 0x01, 0x23, 0x45, 0x67, 0x89];
let mut bits = LittleEndianReader::new(&data);
// ... snip ... maybe some bits are read here.
let expected = 0x0967_4523_01EF_CDAB;
let bits_to_read = 60u32;
bits.refill_lookahead();
let lo_len = bits.lookahead_bits();
let lo = bits.peek(lo_len);
bits.consume(lo_len);
let left = bits_to_read - lo_len;
bits.refill_lookahead();
let hi_len = bits.lookahead_bits().min(left);
let hi = bits.peek(hi_len);
bits.consume(hi_len);
assert_eq!(expected, (hi << lo_len) + lo);
上述内容并不是对在手动模式下模拟更大读取的最佳方法的推荐。例如,可能最好先清空缓冲区,或者使用`MAX_READ_BITS`计算`lo`,而不是查询`lookahead_bits`。始终为您的环境进行性能分析。
未检查模式
Bitter揭示了最后一个技巧,它以牺牲安全性和增加假设为代价,将性能提升到11。欢迎来到未检查的填充API(称为“未检查”),它只能在缓冲区至少还有8个字节时调用。少于这个量可能会造成无效的内存访问。优点是这个API解锁了无分支比特读取的圣杯。
始终考虑在更高层次上保护未检查的访问
use bitter::{BitReader, LittleEndianReader};
let mut bits = LittleEndianReader::new(&[0u8; 100]);
let objects_to_read = 10;
let object_bits = 56;
let bitter_padding = 64;
// make sure we have enough data to read all our objects and there is enough
// data leftover so bitter can unalign read 8 bytes without fear of reading past
// the end of the buffer.
if bits.has_bits_remaining(objects_to_read * object_bits + bitter_padding) {
for _ in 0..objects_to_read {
unsafe { bits.refill_lookahead_unchecked() };
let _field1 = bits.peek(2);
bits.consume(2);
let _field2 = bits.peek(18);
bits.consume(18);
let _field3 = bits.peek(18);
bits.consume(18);
let _field4 = bits.peek(18);
bits.consume(18);
}
}
所有三种模式:自动、手动和未检查都可以根据需要混合使用。
no_std包
这个包有一个默认启用的功能,即std。要在no_std环境中使用此包,请在您的Cargo.toml中添加以下内容
[dependencies]
bitter = { version = "x", default-features = false }
与其他库的比较
Bitter并不是第一个处理比特的Rust库。诸如nom、bitvec、bitstream_io和bitreader等所有包都处理比特读取。选择Bitter的原因是速度。
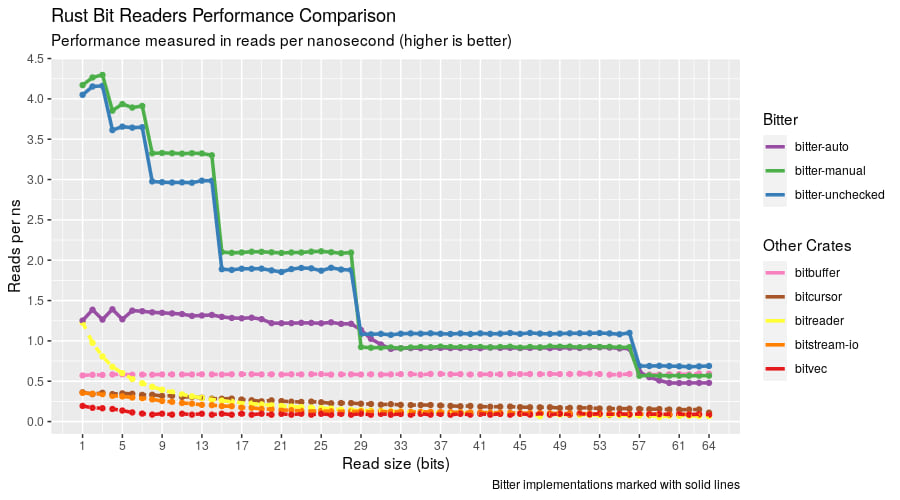
要点
- Bitter是使用最安全的自动API的Rust比特读取库中速度最快的库
- 使用手动或未检查API将小比特读取链接起来,可以让Bitter每纳秒执行多个读取命令
- 在大型读取大小下,bitter API与下一个最快的(bitbuffer)之间的差异开始减小。
基准测试
以下命令用于运行基准测试
(cd compare && cargo clean && cargo bench)
find ./compare/target -path "*bit-reading*" -wholename "*/new/raw.csv" -print0 \
| xargs -0 xsv cat rows > assets/bitter-benchmark-data.csv
可以使用在资产目录中找到的R脚本进行分析。请注意,基准测试将因机器而异