1 个不稳定版本
| 0.3.0 | 2023年10月5日 |
|---|
#1280 在 数据结构 中
67KB
641 行
rust-bfield,B-field 概率型键值数据结构的实现
![]()
B-field 是一种存储键值对的创新概率数据结构(或者说,它是一种概率型关联数组或映射)。B-field 支持插入(insert)和查找(get)操作,并且与著名的 Bloom filter 具有多个数学和性能属性。
在 One Codex,我们使用 rust-bfield 包在生物信息学应用中高效地存储数十亿个长度为 $k$ 的核苷酸子串("k-mers")及其分类学身份之间的关联,每个 (kmer, value) 对只使用 6-7 个字节,对于最多 100,000 个独特的分类学 ID(不同值)和 0.1% 的错误率。我们希望其他人能够使用这个库(或其它语言的实现)在生物信息学及其他领域应用中。
注意:在下方的 实现细节 部分,我们详细介绍了 Rust 中此 B-field 实现的使用,并使用
code格式化和英文参数名称(例如,我们讨论 B-field 作为存储(key, value)对的数据结构)。在下面的 形式数据结构细节 部分,我们使用数学符号详细介绍了 B-field 的设计和机制(即,我们将其视为映射一组 $(x, y)$ 对的关联数组)。生成的 Rust 文档 包含了这两种表示,便于参考。
实现细节
一个B字段存储一个(key, value)映射,但并不直接存储键或值。这允许以高度空间效率地关联(key, value)映射,但代价是产生两类错误。
- 错误类型为假阳性(我们后面将其描述为以可调频率$\alpha$发生),对于未被插入B字段的
key,其get操作返回一个错误的value; - 不确定错误(我们后面将其描述为以频率$\beta$发生),在对于
key的get操作返回一个Indeterminate而不是特定的value。请注意,这种错误可能发生在既已插入B字段也尚未插入B字段的keys上。
通过适当的参数选择可以最小化这两类错误,并且实现零或接近零的不确定性错误率(即$\beta\approx0$)是非常简单的。
空间需求
虽然B字段的空间需求取决于离散值的数量和所需的错误率,以下是一些具有说明性的用例:
-
存储10亿个网页URL,...
-
将每个URL分配到少量类别值中(n=8),占用2.22Gb空间(参数包括ν=8,κ=1,α=0.1%;每个元素19位)
-
存储它们的IPv4前缀(n=32),占用3.16Gb空间(ν=24,κ=2,α=0.1%;每个元素27位)
-
在0.0.0.0/8地址块中存储它们的IP(n=16,777,216),占用8.9Gb空间(ν=51,κ=6,α=0.1%;每个元素76位)
-
确定它们是否属于集合(一个布隆过滤器!)占用1.75Gb空间(参数包括ν=1,κ=1,α=0.1%;每个元素15位)
我们没有对替代数据结构的空间节省进行估计,但任何存储平均每个键约40字节的结构都将比甚至关联约1600万个不同值的B字段大几倍。
-
-
存储10亿个DNA或RNA k-mers(“ACGTA...”),...
-
将它们与NCBI当前描述的约50万个细菌ID之一关联,占用6.93Gb空间(ν=62,κ=4,α=0.1%;每个元素59位)
-
使用3.65Gb存储它们在1000个数据集中最频繁观察到的数据集,ν=46,κ=2,α=0.1%;每个元素31位)
-
在数据集(例如使用约100个量化值)中量化它们的丰富度,占用2.91Gb空间(ν=15,κ=2,α=0.1%;每个元素25位)
这与存储2位编码的32-mers(或8个氨基酸字符)及其关联的32位值的原生实现进行比较,每个元素需要96位,没有任何索引或数据结构开销。
-
🛠 支持的操作和示例代码
此实现提供以下核心功能
- 可以使用
create函数创建B字段(有关更多详细信息,请参阅参数选择),然后通过迭代使用insert函数插入(key, value)对
use bfield::BField;
let tmp_dir = tempfile::tempdir().unwrap();
// Create a B-field in a temporary directory
// with a 1M bit array, 10 hash functions (k), a marker
// width of 39 (ν), weight of 4 (κ), 4 secondary arrays, and
// an uncorrected β error of 0.1
let mut bfield: BField<String> = BField::create(
"/tmp/", // directory
"bfield", // filename (used as base filename)
1_000_000, // size (in bits)
10, // n_hashes (k)
39, // marker_width (ν)
4, // n_marker_bits (weight / κ)
0.1, // secondary_scaledown (uncorrected β)
0.025, // max_scaledown
4, // n_secondaries
false, // in_memory
String::new() // other_params
).expect("Failed to build B-field");
// Insert integers 0-10,000 as key-value pairs (10k keys, 10k distinct values)
for p in 0..4u32 {
for i in 0..10_000u32 {
bfield.insert(&i.to_be_bytes().to_vec(), i, p as usize);
}
}
- 创建后,可以使用
load函数从包含生成的mmap和相关文件的目录中加载 B 场,可选地加载。一旦创建或加载,就可以直接使用get函数查询 B 场,该函数将返回None、Indeterminate或Some(BFieldValue)(当前是Some(u32)的别名,见下文 限制 了解更多细节)。
use bfield::BField;
// Load based on filename of the first array ".0.bfd"
let bfield: BField<String> = BField::load("/tmp/bfield.0.bfd", true).expect("Failed to load B-field");
for i in 0..10_000u32 {
let value = bfield.get(&i.to_be_bytes().to_vec());
}
可以使用 cargo docs 生成附加文档,并托管在 docs.rs 上,以获取最新的 rust-bfield 版本。
🚧 rust-bfield 实现的当前限制
此实现存在一些当前限制
u32值:目前,此实现仅允许存储u32值,尽管可以通过将它们用作映射值的数组索引(例如,[value1, value2, value3, ...])来映射到任何其他任意值。- 无参数选择辅助:目前,
create函数需要手动指定所有 B 场参数。未来的接口可能会自动(并且确定性地)根据关于离散values数量(下文的 $\theta$)以及期望的假阳性错误率和不确定性错误率(下文的 $\alpha$ 和 $\beta$)等信息自动选择最佳参数。 - 无高级插入管理:由于创建一个没有不确定性错误($\beta \approx 0$)的 B 场需要设置
n_secondaries个插入(例如,约 4 个),因此需要迭代插入的所有元素n_secondaries次(参见 benchmark.rs 中的粗略示例)。一个高级插入函数将接受Iterable数据结构并管理执行必要的重复插入以供最终用户使用。
正式数据结构细节
概述
与仅支持集合成员查询的 Bloom 过滤器不同,B 场可以有效地存储一系列 $x, y$ 键值对,其中 $S$ 是存储的 $x$ 值的集合($|S|=n$),$D$ 是所有可能的 $y$ 值的集合($f:S \to D$),而 $\theta$ 代表 B 场的“值范围”($max(D)=\theta$)。换句话说,如果 $f(x)=y$ 是将所有 $x$ 值映射到其相应 $y$ 值的函数,则 $D$ 是函数 $f(x)$ 的定义域。
B 场具有其他概率性和确定性数据结构关联键值的一些优点。具体来说,B 场具有独特的属性组合,使其非常适合存储映射到少量离散值的非常大的键值集。
- 空间效率:B 场以高度空间有效的方式存储键值对,优化了内存使用。对于许多常见的用例或配置,可以使用仅占用数十个千兆字节的存储空间来存储数十亿个元素(或每个键值对几个字节)。这些空间需求与 B 场中元素的数量 $n$ 成线性比例(即 B 场具有 $O(n)$ 空间复杂度)。
- 速度:B字段针对键值对的内存存储进行了优化,计算开销小,内存访问次数少(实现速度应类似于布隆过滤器)。所有B字段的插入和查找操作的时间复杂度均为$O(1)$。
- 明确定义和有界错误:概率性关联数组可能存在三种主要的错误类型。
- 误报:当数据结构在$x\notin S$时返回值$y$时发生误报(而不是返回
None或等效值)。B字段在错误率$\alpha$下会表现出误报。通过降低空间效率,可以选择参数使得$\alpha$任意小。误报是概率性数据结构的常见特征,但与确定性数据结构(例如哈希表)相比,B字段的一个缺点。 - 不确定性:表示为$\beta$的不确定性错误是数据结构返回两个或更多可能的值$y$的元素$x \in S$的速率。这可能表现为可能$y$值的向量或错误类型(例如,此实现返回
Indeterminate)。虽然组成B字段的内部数组各自独立表现出大量的$\beta$错误,但适当的B字段参数选择允许$\beta = 0$或$\beta \approx 0$。 - 错误检索/映射错误:当数据结构查询$x \in S$并返回错误的值$y$时,会发生错误检索或映射错误$\gamma$,其中$f(x) \ne y$。B字段不可能发生错误检索。
- 误报:当数据结构在$x\notin S$时返回值$y$时发生误报(而不是返回
B字段的实现
⚠️ 警告:本节提供了B字段数据结构背后的数学的详细概述,旨在为对那些机制或正在实现新B字段库的人提供帮助。许多读者可能更喜欢跳转到总结B字段属性子节。
B字段通过将$y$编码为二进制模式或字符串,然后使用$k$个不同的哈希函数$(h_{1}..h_{k})$将每个插入元素$x$的该二进制模式插入到一系列位数组中来实现。虽然以下许多实现细节对熟悉通用哈希数据结构和布隆过滤器的人来说都很熟悉,但B字段是为存储键值对而不是简单的集合成员信息而设计的。B字段的基本构造需要以下步骤
1. 配置。
作为第一步,用户需要选择几个配置选项,这将决定初始B字段的构建方式。这些关键配置变量包括
(a) 所希望的误报最大比率$\alpha$。
(b) 预期要存储的值的数量$n$,其中$n=|S|$。如果向B字段中插入超过$n$个元素,则预期的误报率将超过$\alpha$。
(c) 所有可能$y$值的集合的最大值$\theta$。请注意,使用此处概述的默认编码系统,$y$值的范围$D$必须包含所有或非负整数的子集${1, ..., \theta}$或${0, ..., \theta - 1}$。但是,可以通过简单地使用$y$作为索引或指针到集合$D\prime$中的一个值来将其映射到任何具有至多$\theta$个不同值的集合(在这种情况下,$y$作为中间值)。其中$|D\prime| = \theta$。
(d) 值 $\nu$ 和一个值 $\kappa$,使得 ${\nu \choose \kappa}\ge\theta$,其中 ${\nu \choose \kappa}$ 是组合公式,但使用 $\nu$ 作为参数而不是更常见的 $n$(用于 B 场和 Bloom 过滤器表示 $S$ 的基数或 $|S|$)和 $\kappa$ 代替更常见的 $k$(用于枚举所需哈希函数 $h_{1}...h_{k}$ 的数量)
$$ {\nu \choose \kappa}=\frac{\nu!}{\kappa!(\nu-\kappa)!} $$
由于 B 场将值 $y$ 编码到 $\nu$ 长度的位串中,恰好有 $\kappa$ 个 1(或从信息论的角度看,汉明重量为 $\kappa$),因此最好同时做到:(i) 最小化 $\kappa$;和(ii) 在选择 $\nu$ 和 $\kappa$ 时保持 $\nu$ 与 $\kappa$ 的数量级一致。例如,在选取 $\nu$ 和 $\kappa$ 的值,使得 ${\nu \choose \kappa} \ge 1000$ 时,最好设置 $\nu = 20$ 和 $\kappa = 3$(${\nu \choose \kappa} = 1140$)而不是设置 $\nu = 1000$ 和 $\kappa = 1$。这一点将在后续关于错误率和 B 场操作的讨论中变得清晰。
2. 位阵列大小和哈希函数选择。
接下来,需要为 B 场中使用的 primary 位阵列选择一个大小,并选择适当的哈希函数数量 $k$。由于 B 场以类似于 Bloom 过滤器的方式将输入键哈希到一个位阵列中,因此可以采用相同的底层公式来选择位阵列的最佳大小和哈希函数的数量,只是 B 场需要一个 $m\kappa$-位阵列,而简单的 Bloom 过滤器需要一个 $m$-位阵列(此处 $p$ 代表单个位错误的概率,将在以下 5b 中进一步定义)
$$ m=-\frac{{n\ln p}}{(\ln2)^{2}} $$ $$ k=\frac{m}{n}\ln2 $$
至于哈希函数本身的选择,任何具有良好伪随机性和分布特性的哈希函数都足以用于 B 场。虽然前面的方程假设了一个完全随机的哈希函数,但 B 场与非线性哈希函数(如 MurmurHash3 或类似的哈希函数)的性能相当。再次强调,虽然从理论上讲,哈希函数集合应该是完全独立的,但在实践中,为了性能原因,可以使用 2 个独立的哈希函数作为种子,然后放松剩余哈希函数的独立性要求,即,两个种子哈希函数 $h_{a}(x)$ 和 $h_{b}(x)$ 可以用来创建 $k$ 个组合哈希函数,每个定义如下:$h_{k}(x)=h_{a}(x) \times ((n-1) \times h_{b}(x))$(有关详细信息,请参阅 Kirsch 和 Mitzenmacher 2008)
3. 位阵列分配。
现在已计算出 $m$ 并选择了 $\kappa$,我们分配一个 $m\kappa$-位内存阵列,将所有位最初设置为 0。请注意,B 场可能使用多个位阵列,这个初始的 $m\kappa$-位阵列被称为 B 场 $\mathtt{Array_{0}}$。
4. 键值插入。
接下来,将 B 场的键 $(x_{1}...x_{n})$ 和它们相应的值 $(y_{1}...y_{n})$ 插入。这需要对 $x_{1}...x_{n}$ 中的所有 $x$ 执行两个步骤或函数。
(a) $\mathtt{ENCODE}$。$\mathtt{ENCODE}$ 操作将给定的值 $y$ 转换为一个 $\nu$ 长度的二进制字符串,其中包含 $\kappa$ 个 1,以便插入到 B 场的 primary 数组 $(\mathtt{Array_{0}})$ 中。使用标准编码系统,这仅仅是简单地将 $y$ 转换为所有 $\nu \choose \kappa$ 组合的 lexicographic 排序中的第 $y$ 个 $\nu$ 长度 $\kappa$ 权重位串(例如,如果 $\nu = 4$ 和 $\kappa = 1$,则 1 转换为 0001)。其他甚至和奇偶权重编码方案也可以在此步骤中使用(例如,纠错码),但在此处不详细说明或进一步评估。图 1 说明了 $\mathtt{ENCODE}$(和 $\mathtt{DECODE}$)操作的工作原理,其中 $\nu = 5, \kappa = 2$。

图 1: $\nu = 5$ 和 $\kappa = 2$ 的示例 $\mathtt{ENCODE}$ 和 $\mathtt{DECODE}$ 操作。
(b) $\mathtt{INSERT}$操作。$\mathtt{INSERT}$操作将编码值$y$(与键$x$相关联)放入B字段。首先,对$x$应用$k$个哈希函数$(h_{1}(x)...h_{k}(x))$,然后取每个值的$\mathtt{mod}(m\kappa)$(即,使用位数组大小$m\kappa$对哈希值$h(x)$应用取模操作)。这$k$个哈希值,其中$0 \le h(x) \mathtt{mod} m\kappa \le m\kappa$,用作将编码值$y$进行位或插入的索引,其中$\nu$长度位串的第一位是$h(x) \mathtt{mod} m\kappa$,最后一位是$h(x) \mathtt{mod} m\kappa + \nu - 1$。在将第一个$x, y$键值对插入到空的$\mathtt{Array_{0}}$的情况下,其中$k=6, \nu=5, \kappa=2$且$y=2$(不切实际的值但有助于说明),结果将是将位串00101以$(k=6)$次位或方式放入$m\kappa$位数组中,总共翻转12位($k \times \kappa$)。图2展示了对于键值对$y=2$和配置为$\nu = 5, \kappa = 2$和$k=6$的B字段的一个示例$\mathtt{INSERT}$操作。该操作对于插入到$\mathtt{Array_{0}}$或任何次要数组(下文将进一步描述)是相同的。
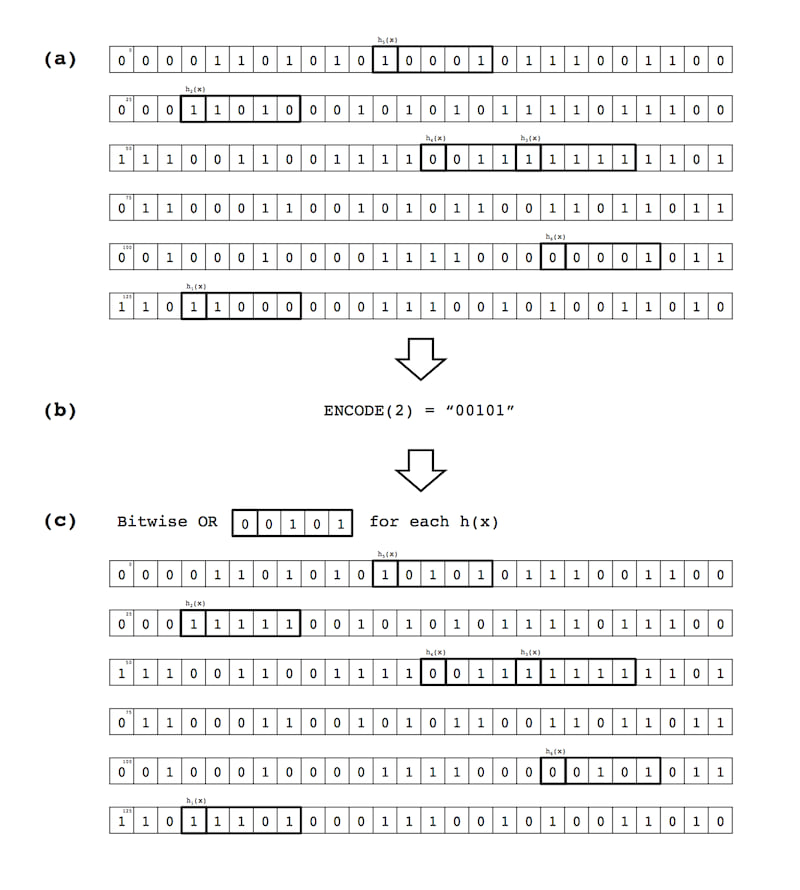
图2: 样本$\mathtt{INSERT}$操作:(a) 对输入键$x$哈希$k$次,提供$k$个B字段数组的索引位置;(b) 将与键$x$相关联的值$y$编码成一个$\nu$长度的、$\kappa$权重的位串(此处$y=2, \nu=5$和$\kappa=2$);(c) 对数组的$\nu$长度切片与表示编码值$y$的$\nu$长度位串进行位或操作,对所有$k$个哈希函数$h_{1}(x)...h_{k}(x)$执行此操作。
5. 后续B字段数组的构建
为了描述构建后续数组$\mathtt{Array_{1}}...\mathtt{Array_{a-1}}$的过程,其中$a$是B字段中位数组的总数,我们简要概述:(a) 如何执行$\mathtt{LOOKUP}$操作;以及(b) 到目前为止构建的B字段的错误类型。
5(a). $\mathtt{LOOKUP}$操作。
$\mathtt{LOOKUP}$操作与$\mathtt{INSERT}$操作类似。对于给定的$x_{i}$,使用哈希函数$h_{1}...h_{k}$(所有$\mathtt{mod} m\kappa$)对$x_{i}$哈希$k$次。在每个索引位置$h_{1}(x_{i})...h_{k}(x_{i})$取一个$\nu$长度的位串,并与初始的$\nu$长度全1位串进行位与操作(即,汉明权重为$\nu$)。使用图2中的先例,如果以下6个5位串${10101, 11111, 00111, 11111, 00101, 11101}$在B字段$\mathtt{Array_{0}}$的$h_{1}(x_{i})...h_{k}(x_{i})$处找到,则这些位串的位与结果为$00101$,我们将它$\mathtt{DECODE}$为得到$y_{i}$的值2。图3详细说明了这个样本$\mathtt{LOOKUP}$操作。
$\mathtt{LOOKUP}$操作可能产生以下结果
-
汉明权重$\lt \kappa$的位串指示$x \notin S$。这是由于在4(b)中详细说明的$\mathtt{INSERT}$操作插入$\kappa$个1,通过位或操作,保证后续对同一元素的任何$\mathtt{LOOKUP}$至少返回$\kappa$个1。在这种情况下,B字段实现应该返回
None或类似值,表示$x_{i} \notin S$。 -
汉明权重$=\kappa$的位串。在这种情况下,我们$\mathtt{DECODE}$生成的位串(简单地是图1中详细说明的$\mathtt{ENCODE}$操作的逆操作)并返回与键$x_{i}$映射的值$y_{i}$。此操作将以$\alpha$(在5(b)中以下将推导出)的假阳性率错误地返回$x \notin S$的$y_{i}$。
-
最后,将具有大于 $\kappa$ 的汉明权重的位字符串以概率 $\beta$(如5(b)部分中所述)检索出来。这代表了一个具有超过 $\kappa$ 个1的
不确定结果。通过构建后续的B字段数组 $\mathtt{Array_{1}}...\mathtt{Array_{a-1}}$,实现了$\beta$的大幅降低。
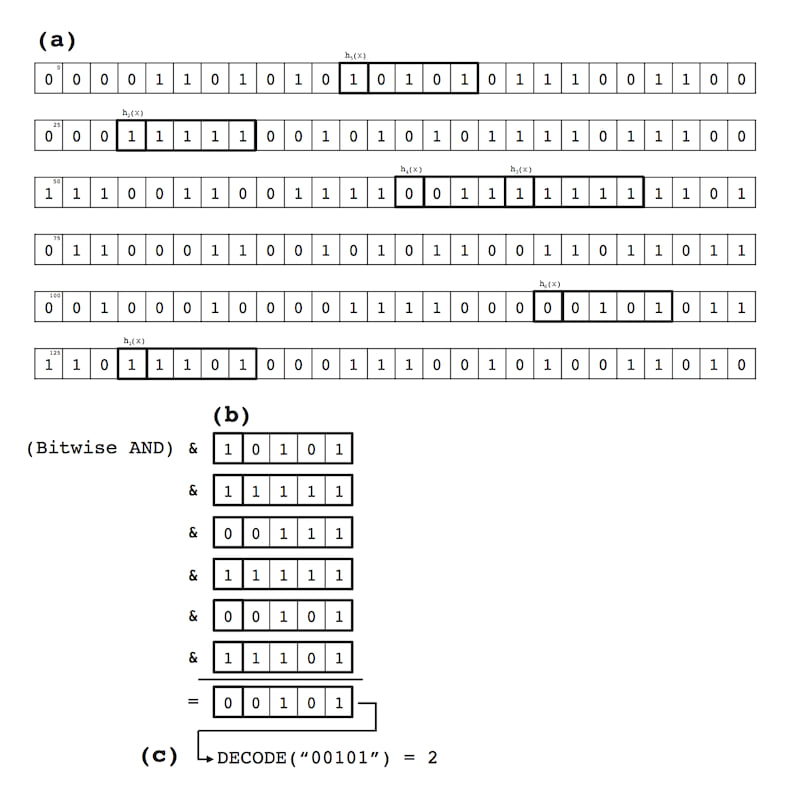
图3:示例 $\mathtt{LOOKUP}$ 操作:(a)对密钥 $x$ 进行 $k$ 次哈希,并从B字段数组中提取出 $\nu$ 长度、$\kappa$ 权重的位字符串;(b)将 $k$ 个位字符串进行按位与操作;(c)将结果位字符串进行 $\mathtt{DECODE}$ 解码以恢复与密钥 $x$ 关联的值 $y$。
5(b)。B字段错误率详细说明。
如上所述,B字段 $\mathtt{Array_{0}}$ 中的 $\mathtt{LOOKUP}$ 操作既存在假阳性($\alpha$)错误,也存在不确定性($\beta$)错误。这些错误率可以根据上述 $\mathtt{INSERT}$ 操作的机制简单推导出来,该机制为每个 $k$ 个哈希函数在位数组中设置至多 $\kappa$ 个随机位。请注意,这些属性和错误率与布隆过滤器类似,实际上,当 $\nu = 1, \kappa = 1$ 且仅使用单个位数组时,B字段 等同于布隆过滤器(因为它在每次操作中设置单个位)。
首先,我们需要确定在将 $k$ 个位字符串进行按位与操作后,$\nu$ 长度位字符串中的任意单个位出错的可能性(这里描述为 $p$,单个位错误的概率)。单个位未由单个哈希函数(每个哈希函数翻转 $\kappa$ 位)设置成1的概率是
$$1-\frac{\kappa}{m\kappa}$$
然后我们可以约掉 $\kappa$
$$1-\frac{1}{m}$$
因此,单个位对于任何 $k$ 个哈希函数都没有被设置的几率是
$$(1-\frac{1}{m})^{k}$$
在将 $x_{1}...x_{n}$ 插入位数组 $n$ 次之后,给定位仍然为0的几率是
$$(1 - \frac{1}{m})^{kn}$$
而它被设置成1的几率是
$$1-(1 - \frac{1}{m})^{kn}$$
在构成给定位数组的 $\mathtt{LOOKUP}$ 操作的 $k$ 次单独访问(每个哈希函数一次)之后,单个位被错误地设置成1的几率是
$$(1-(1-\frac{1}{m})^{kn})^{k} \approx (1-e^{-kn/m})^{k}$$
将上述最优 $m$ 和 $k$ 值的公式代入得到
$$p=(1-e^{(-m/n \ln 2)n/m})^{(m/n \ln 2)}$$
其中 $p$ 是在执行 $\mathtt{INSERT}$ 操作之前,$\nu$ 位字符串中编码给定值 $y_{i}$ 的单个位被设置成1的概率(即随后的 $\mathtt{LOOKUP}$ 将因假阳性或不确定性错误而失败)。
使用 $p$,我们可以推导出B字段整体 $\mathtt{Array_{0}}$ 的假阳性概率($\alpha_{0}$)。由于假阳性定义为在 $\nu$ 位字符串中有超过 $\kappa$ 个位翻转成1,因此 $\alpha_{0}$ 是 $\mathit{CumBinom}(\nu, \kappa, p)$,其中 $\mathit{CumBinom}$ 是累积二项分布的右尾
$$\alpha=Pr(X\ge\kappa)=\sum_{i=\kappa}^{\nu}{\nu \choose i}p^{i}(1-p)^{\nu-i}$$
相应地,$\beta$ 是给定值 $x \in S$ 返回具有超过 $\kappa$ 个位翻转成1的 $\nu$ 长度位字符串的概率(至少 $\kappa$ 个位由 $\mathtt{INSERT}$ 操作设置成1)。这对应于 $\mathit{CumBinom}(\nu - \kappa, 1, p)$。如果不进行修正,$\beta$ 对于许多应用来说太高(尽管对于其他应用是可用的),因此,B字段构建的下一步是努力修正 $\beta$ 使得 $\beta \approx 0$。这种修正将所有值 $\ge \kappa$ 的累积二项分布的 $\alpha$ 降低到恰好 $\kappa$ 的二项分布,即 ${\nu \choose \kappa}p^{\kappa}(1-p)^{\nu-\kappa}$。
5(c). 通过构建额外的位数组减少$\beta$误差
鉴于这些误差率$\alpha$和$\beta$,一个额外的校正是有益的。为了(几乎)消除不确定性误差率$\beta$(作为副作用,大幅度减少假阳性误差率$\alpha$的幅度),我们在第一次将所有输入密钥$x_{1}...x_{n}$完整插入到$\mathtt{Array_{0}}$之后,再次遍历所有这些输入密钥。然而,这一次,我们不是将它们插入到$\mathtt{Array_{0}}$中,而是执行一个$\mathtt{LOOKUP}$操作,并记录每个$x_{i}$的每个$\nu$位字符串$(w_{i})$的汉明重量。如果$w_{i} \gt \kappa$,我们有一个不确定性错误,因为已知的$x \in S$没有返回其相应的$\nu$长度$\kappa$重量位字符串。对于$x_{1}...x_{n}$的子集,其中$w_{i} \gt \kappa$包含$\beta n$个元素。然后,将这个$\beta n$子集插入第二个数组$\mathtt{Array_{1}}$中,它是在上述步骤创建的,但是它的大小缩小到约为$\beta m\kappa$位,并且只存储$\beta n$个元素,而不是$n$个键值对。
这个二级数组$\mathtt{Array_{1}}$允许在$\mathtt{Array_{0}}$中对$x_{i}$的不确定性$\mathtt{LOOKUP}$操作产生$\gt \kappa$ 1位,然后对$\mathtt{Array_{1}}$执行第二次查找。由于$x_{i}$产生$\gt \kappa$ 1位的概率对于$\mathtt{Array_{0}}$和$\mathtt{Array_{1}}$(除了整体大小和存储的键值对数量外,参数相同)都是$\beta$,因此通过添加$\mathtt{Array_{1}}$,不确定性率从$\beta$降低到$\beta^2$。
可以添加更多的数组$\mathtt{Array_{2}}...\mathtt{Array_{a-1}}$,直到形成一组$a$个数组,选择$a$使得$\beta^{a}n \lt 1$(尽管在实践中,通常只需选择一个值$a$,使得只有少数几个元素被插入到$\mathtt{Array_{a-1}}$)。这些二级数组还具有降低假阳性率$\alpha$的效果,因为假阳性$x_{i} \notin S$产生$\gt \kappa$ 1位也会导致对$\mathtt{Array_{1}}$(以及$\mathtt{Array_{2}}...\mathtt{Array_{a-1}}$)进行检查。这降低了假阳性率$\alpha$从累积二项式分布到简单二项式${\nu \choose \kappa}p^{\kappa}(1-p)^{\nu-\kappa}$。或者,我们可以将其理解为将$\alpha$错误可能发生的情况从任何$\ge \kappa$ 1位翻转的$x_{i} \notin S$减少到两种情况:(1)当$x_{i} \notin S$的$\mathtt{Array_{0}}$中恰好$\kappa$位1位(简单二项式);或者(2)在$\mathtt{Array_{0}}...\mathtt{Array_{a-2}}$中翻转的$\gt \kappa$ 1位非常多,而在$\mathtt{Array_{a-1}}$中恰好$\kappa$位翻转的极其罕见的情况。第二种情况的可能性应该约为0,因为随着每个二级数组的添加,翻转$\gt \kappa$位的机会会指数级下降。
总结来说,这个在$\mathtt{Array_{0}}$($\mathtt{Array_{1}}...\mathtt{Array_{a-1}}$)之后的二级数组级联降低了假阳性率$\alpha$从累积二项式分布到$\kappa$个单个位错误二项式分布,并消除了所有不确定性错误(即$\beta = 0$或$\beta \approx 0$)。并且,这种误差减少是以对B字段空间效率的相当小的成本实现的。回想一下,B字段的原始空间需求$\mathtt{Array_{0}}$是$m\kappa$位,其中$m=-\frac{n \ln \alpha}{(\ln 2)^{2}}$,$\kappa$是选择${\nu \choose \kappa} \gt \theta$的值,其中$\theta$是存储值$y_{1}...y_{n}$或$|D|$的域的最大值,在这种情况下$y_{1}...y_{n}$是$1...n$。因此,$\mathtt{Array_{0}}$需要$\beta^{0}m\kappa$位,而$\mathtt{Array_{1}}$需要$\beta^{1}m\kappa$位,而$\mathtt{Array_{a-1}}$需要$\beta^{a-1}m\kappa$位。将所有这些都除以$m\kappa$位,揭示了底层的几何级数
$$1+\beta^{1}+...+\beta^{a-1}$$
其和可以简单地表示为
$$\frac{1}{1 - \beta}$$
因此,具有一个主 $\mathtt{Array_{0}}$ 和 $a - 1$ 个辅助数组的 B 场的总空间需求仅为 $\frac{1}{1-\beta}m\kappa$ 比特。在许多使用场景中,初始未校正的不确定性率 $0.05 \le \beta \le 0.20$ 不会很罕见。对于 5.3% $(\frac{1}{0.95})$ 或 25.0% $(\frac{1}{0.80})$ 的空间惩罚进行校正通常是一个良好的权衡,尽管可以通过仅使用 $\mathtt{Array_{0}}$ 来构建 B 场,但这需要管理 $\beta$ 个不确定性错误在键值查找中。
B 场属性总结
简要总结,B 场是一个概率性的关联数组或映射,具有以下独特的属性集
-
创建与插入:总创建时间为 $O(n)$,插入为 $O(1)$,平均需要 $\frac{\kappa}{1-\beta}$ 次哈希计算和内存访问,最坏情况下需要 $a\kappa$ 次哈希计算和内存访问。常见的 $a$ 值约为 4。
-
查找:查找为 $O(1)$,需要与插入相同的哈希计算和内存访问次数。
-
空间复杂度:空间复杂度为 $O(n)$,需要 $\frac{m\kappa}{1-\beta}$ 比特,其中 $m$、$\kappa$ 和 $\beta$ 如上定义($\mathtt{Array_{0}}$ 需要 $m\kappa$ 比特,而整个 B 场需要额外的 $1 - \frac{1}{1-\beta}$ 倍因素)。
参数选择
一个高效的 B 场需要选择最优的 $\nu$、$\kappa$、B 场 $\mathtt{Array_{0}}$ 的大小($m\kappa$)以及计算辅助数组所需的缩放因子(未校正的 $\beta$)。此处包含的 参数选择笔记本 为计算这些参数提供了一个模板。
扩展
对 B 场设计的许多扩展是可能的,但在此尚未实现。以下概述了其中一些
- 可变性:虽然此实现旨在支持不可变 B 场,但可以实现可变 B 场。例如,$\mathtt{INSERT}$ 操作可以保存并连续或批量重放,以确保所有元素 $x \in S$ 都被正确插入到 B 场的主和辅助数组中。
- 缓存局部性:通过将哈希函数 $h_{1}(x)...h_{k}(x)$ 的一个子集设置为在先前的内存访问的小固定偏移量处进行查找(即,将 $h_{2}(x)$ 设置为在 $h_{1}(x)$ 之后在固定窗口内选择一个随机位置,以利用缓存局部性)来优化内存访问速度。
- 替代编码方案:虽然上述简单编码方案非常适合相对均匀分布在域 $\theta$ 上的 $y$ 值,但可以更改编码方案,例如(i)使用纠错码或(ii)为出现频率更高的 $y$ 值子集使用不同的权重(以最小化 B 场数组的“填充”),以及其他可能性。
何时考虑替代数据结构
- 当存储具有许多不同
(x, y)对的关联数组或映射(例如,简单的哈希表)时,可能是一个更好的选择(例如,存储 1M 个键,800,000 个不同的值)。有关 B 场最佳用例的详细信息,请参阅 正式数据结构概述 和 参数选择。 - 对于任何注入函数映射(例如,对于每个 $x$ 都有一个唯一的 $y$ 值的情况),[最小] 完美哈希函数(可能配对 Bloom 过滤器或其他支持集合成员查询的数据结构)是一个更好的选择
- 尽管在配置适当的参数时可以将其减少为布隆过滤器,但布隆过滤器(或可能是XOR 过滤器)对于支持简单的集合成员查询来说,比B字段是一个更好的选择。
历史
B字段数据结构是由Nick Greenfield(@boydgreenfield)和Nik Krumm(@nkrumm)于2013年合作开发的,作为DTRA 2013算法挑战赛(部分细节可在Jonathan Eisen的博客这里找到,主要内容已不再在线)的一部分。在Python、Cython和C的初始概念验证实现之后,2014年由@boydgreenfield开发了一个Nim实现,并在One Codex的核心宏基因组分类器中用于生产环境约4年(首次描述这里)。Dominik Picheta(@dom96)和Alex Bowe(@alexbowe)在2015年为nim-bfield实现贡献了额外的增强和想法。
2017年,Roderick Bovee(@bovee)将nim-bfield库移植到Rust实现中,该实现继续用于One Codex平台背后的第二代宏基因组分类器。Vincent Prouillet(@Keats)和Gerrit Gerritsen(@GSGerritsen)自2020年以来贡献了额外的工作(以及文档!)并维护着rust-bfield存储库。
2021年2月,One Codex被Invitae收购,该库继续作为其宏基因组分类平台的一部分使用。2022年9月,One Codex团队将公司从Invitae中剥离出来,并决定开源并免费提供B字段库。我们已尽力在此处进行文档记录,并希望您觉得它有用!❤️
其他用例
如果您觉得这个存储库很有用,我们很乐意听取您的反馈并在此处记录您的用例。请随时为此README的该部分打开一个PR或给我们发一封邮件!👋
许可证
此源代码在Apache 2许可证下提供,附带专利许可(以确保在2014年专利的情况下,无障碍使用rust-bfield存储库)。
依赖关系
~0.8–1.5MB
~33K SLoC