1 个稳定版本
使用旧的 Rust 2015
| 1.0.0 | 2018年5月2日 |
|---|
#38 in #freebsd
38KB
937 代码行
benchpmc
一个使用大多数 x86 CPU 中存在的 PMC(性能监视计数器)的黑盒基准测试运行器。
它重复运行二进制文件,计算配置计数器的平均值和相对标准偏差。它看起来就像这样
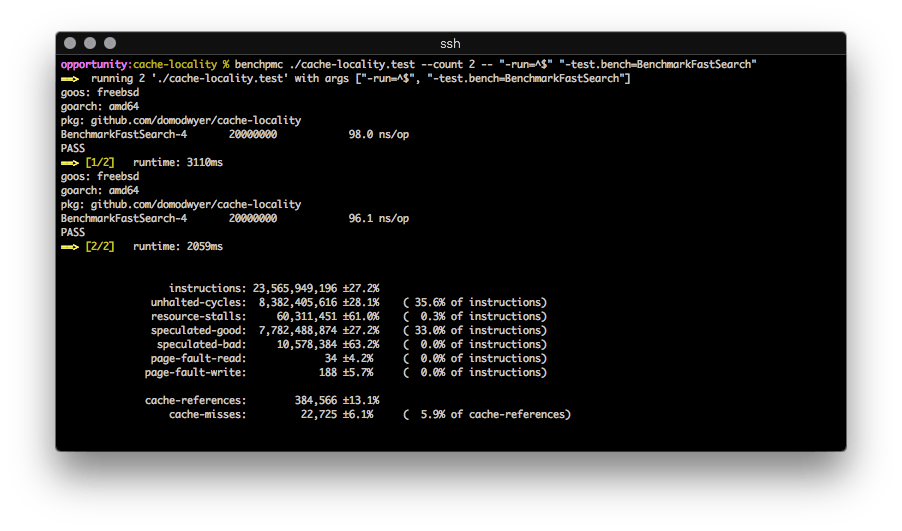
用户可以指定不同的 PMC 进行测量,尽管它们必须能够进行进程级别的操作(有些只能在系统范围内)。
该工具基于 FreeBSD 的 hwpmc 内核模块构建,因此您还需要安装该模块。
什么是 PMC?
PMC 是 CPU 硬件的一部分,通常用于对特定应用程序或算法的 CPU 微架构事件进行性能分析。使用 PMC,可以通过最小化 CPU 停顿、优化 CPU 缓存使用等来调整算法以获得更好的性能。
事件由 CPU 制造商定义(可以在 Intel 64 和 IA-32 架构软件开发者手册:第 3B 卷 中找到,其中事件位于 18.2.12 "预定义的架构性能事件" 部分中,表 18-1 "预定义架构性能事件的掩码和事件选择编码")。
为什么?
我在 FreeBSD 上进行了大量的基准测试工作,并且缺少 Linux perf 工具的快速统计概述。FreeBSD 随带 pmcstat,这很酷,但我真的很想能够重复运行二进制文件并快速获取一个很好的概述,同时进行微调。
并且我想用 rust 来构建它。
使用 benchpmc 进行分析
在这个例子中,我们将分析一个简单的预编译 Golang 基准测试,比较两个竞争算法 Sample A 和 Sample B(使用 go test -c 编译 stdlib 基准测试)
首先,我们需要了解这两个算法的性能
benchpmc ./algorithms.test -- "-run=^$" "-test.bench=BenchmarkSampleA"`
Sample A:
instructions: 19,031,333,328 ±0.0%
unhalted-cycles: 7,002,094,130 ±4.2% ( 36.8% of instructions)
resource-stalls: 175,771,059 ±68.2% ( 0.9% of instructions)
speculated-good: 6,285,556,182 ±0.0% ( 33.0% of instructions)
speculated-bad: 19,662,434 ±68.7% ( 0.1% of instructions)
page-fault-read: 28 ±0.0% ( 0.0% of instructions)
page-fault-write: 170 ±0.0% ( 0.0% of instructions)
cache-references: 202,174 ±4.0%
cache-misses: 10,756 ±30.7% ( 5.3% of cache-references)
Sample B:
instructions: 15,185,065,698 ±0.0%
unhalted-cycles: 5,436,809,490 ±0.4% ( 35.8% of instructions)
resource-stalls: 1,312,015,320 ±1.5% ( 8.6% of instructions)
speculated-good: 2,509,454,558 ±0.0% ( 16.5% of instructions)
speculated-bad: 2,376,762 ±69.7% ( 0.0% of instructions)
page-fault-read: 28 ±0.0% ( 0.0% of instructions)
page-fault-write: 170 ±0.0% ( 0.0% of instructions)
cache-references: 178,634 ±2.0%
cache-misses: 11,103 ±31.1% ( 6.2% of cache-references)
这两个算法之间几乎没有区别,实际上,它们的运行时间(未显示)也非常相似,但让我们探索资源停滞相对增加 8% 的原因,以突出 PMC 的粒度。
使用 benchpmc 测量特定的 RESOURCE_STALLS 事件
benchpmc ./algorithms.test --event="RESOURCE_STALLS.ANY" \
--event="RESOURCE_STALLS.LB" --event="RESOURCE_STALLS.SB" \
--event="RESOURCE_STALLS.ROB" --event="RESOURCE_STALLS.FCSW" \
--event="RESOURCE_STALLS.MXCSR" -- \
"-run=^$" "-test.bench=BenchmarkSampleA"
Sample A:
RESOURCE_STALLS.ANY: 183,901,679 ±65.3%
RESOURCE_STALLS.LB: 94,318,196 ±65.8%
RESOURCE_STALLS.SB: 432,623 ±5.3%
RESOURCE_STALLS.ROB: 196,738 ±7.5%
RESOURCE_STALLS.FCSW: 0
RESOURCE_STALLS.MXCSR: 0
Sample B:
RESOURCE_STALLS.ANY: 1,309,699,802 ±2.8%
RESOURCE_STALLS.LB: 1,308,448,313 ±2.8%
RESOURCE_STALLS.SB: 1,331,845 ±33.1%
RESOURCE_STALLS.ROB: 213,417 ±11.9%
RESOURCE_STALLS.FCSW: 0
RESOURCE_STALLS.MXCSR: 0
在RESOURCE_STALLS.LB中的巨大差异表明,由于所有CPU内存加载缓冲区都过载,从L1缓存中拉取数据导致执行中断。
首先检查L1/L2/LLC的命中情况,确保两个样本之间分布相对均匀,很明显,样本B相对于样本A进行了更多的L1缓存读取,并且在L1缓存内部发生了许多银行冲突,这是Sandy Bridge特有的问题。
Sample A:
MEM_LOAD_UOPS_RETIRED.L1_HIT: 3,491,840,931 ±0.0%
MEM_LOAD_UOPS_RETIRED.L2_HIT: 19,813 ±4.1%
MEM_LOAD_UOPS_RETIRED.LLC_HIT: 28,959 ±4.7%
L1D_BLOCKS.BANK_CONFLICT_CYCLES: 7,532,592 ±44.2%
Sample B:
MEM_LOAD_UOPS_RETIRED.L1_HIT: 5,022,114,366 ±0.0%
MEM_LOAD_UOPS_RETIRED.L2_HIT: 18,528 ±5.3%
MEM_LOAD_UOPS_RETIRED.LLC_HIT: 24,369 ±3.5%
L1D_BLOCKS.BANK_CONFLICT_CYCLES: 53,973,890 ±12.4%
这表明我们正在处理一个“热点”数据集,它完全适合在一个非常紧密的循环中L1缓存中,而在样本B中的内存访问模式导致了许多阻塞的L1读取,部分原因是银行冲突:增加了7.1倍,这几乎与观察到的RESOURCE_STALLS.ANY增加相吻合,当你考虑到额外L1读取的开销。
PMCs非常强大,对吧?
安装
可以从发布页面下载二进制文件,或者使用cargo build自行编译。显然需要一个FreeBSD盒子,因为它使用了hwpmc内核模块。
我不期待它会有特别受欢迎(说到利基市场...),但如果它有用或者你有问题,请随时给我发电子邮件!
依赖关系
~3MB
~49K SLoC