6个版本
| 0.9.5 | 2020年6月18日 |
|---|---|
| 0.9.4 | 2019年5月2日 |
| 0.9.2 | 2019年4月20日 |
在 硬件支持 中排名 356
每月下载量 35
3MB
3.5K SLoC
![]()
![]()
![]()
autoperf
autoperf 简化了在英特尔机器上使用性能计数器对程序进行测量的过程。您不必学习如何测量每个事件并手动在计数器寄存器或 perf 中编程事件值,而是可以使用 autoperf,它会重复运行您的程序,直到测量到机器上的每个性能事件。autoperf 尝试计算一个计划,以最大化每次运行的测量事件数量,并最小化总运行次数,同时避免计数器上事件的多路复用。

背景
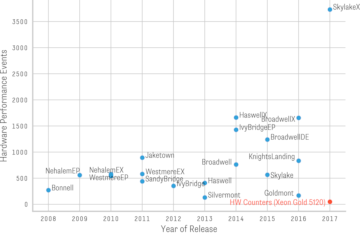
性能监控单元通常在性能事件和计数器之间进行区分。事件指的是微观架构层面的观察(例如,TLB 缺失、页面访问等),而计数器是硬件寄存器,用于计算事件的发生次数。右边的图显示了不同英特尔微观架构的不同可观察事件数量。请注意,当前系统提供了大量可能的监控事件。每个 PMU 的可测量计数器数量有限(通常从两个到八个)。例如,如果在 SkylakeX(Xeon Gold 5120)机器上的所有 PMU 上测量相同的事件,我们最多只能观察到 48 个不同的事件(不进行采样)。autoperf 简化了完全测量和记录给定程序每个性能事件的流程。在我们的屏幕会话中,记录在一个具有 ~3500 个不同事件的 SkylakeX 机器上,我们可以看到 autoperf 自动运行程序 1357 次,并在每次运行中测量和记录不同的事件集。
安装
已知 autoperf 与 Ubuntu 18.04 在 Skylake 和 IvyBridge/SandyBridge 架构上一起工作。所有英特尔架构都应正常工作,如果不起作用,请提交错误请求。autoperf 基于 Linux 项目中的 perf 和一些其他库构建,可以使用以下方法安装
$ sudo apt-get update
$ sudo apt-get install likwid cpuid hwloc numactl util-linux
要运行示例分析脚本,您需要以下 python3 库
$ pip3 install ascii_graph matplotlib pandas argparse numpy
您还需要 rust 编译器的 夜间版本,最好使用 rustup 安装
$ curl https://sh.rustup.rs -sSf | sh -s -- -y --default-toolchain nightly
$ source $HOME/.cargo/env
autoperf 已发布在 crates.io 上,因此一旦您安装了 rust 和 cargo,您就可以直接从那里获取
$ cargo +nightly install autoperf
或者,您可以克隆并自行构建仓库
$ git clone https://github.com/gz/autoperf.git
$ cd autoperf
$ cargo build --release
$ ./target/release/autoperf --help
autoperf 使用 perf 内部与 Linux 和性能计数器硬件接口。perf 建议禁用以下设置。因此,如果这些配置不符合以下设置,autoperf 将检查这些配置的值,并拒绝启动
sudo sh -c 'echo 0 >> /proc/sys/kernel/kptr_restrict'
sudo sh -c 'echo 0 > /proc/sys/kernel/nmi_watchdog'
sudo sh -c 'echo -1 > /proc/sys/kernel/perf_event_paranoid'
用法
autoperf有几个命令,使用--help以获得所有选项的更全面概述。
性能分析
profile命令通过多次运行一个程序,直到测量到每个性能事件,来为单个程序进行性能分析。例如,
$ autoperf profile sleep 2
会重复运行sleep 2,同时每次使用性能计数器测量不同的性能事件。完成后,您将找到一个包含来自单个运行测量结果的许多csv文件的out文件夹。
汇总结果
要将所有这些运行汇总到单个CSV结果文件中,可以使用aggregate命令
$ autoperf aggregate ./out
这将进行一些合理性检查,并生成一个results.csv(简化的示例)文件,其中包含所有测量数据。
分析结果
性能事件在每个核心(和其他监控单元)上单独测量。使用timeseries.py可以通过取平均值、标准差、最小值、最大值等来汇总事件,并生成时间序列矩阵(见简化的示例)。
python3 analyze/profile/timeseries.py ./out
现在您有了所有数据,所以您可以开始提出一些问题。例如,以下脚本告诉您在程序运行时事件是如何相关的
$ python3 analyze/profile/correlation.py ./out
$ open out/correlation_heatmap.png
上述autoperf profile sleep 2命令的事件相关性如下(每个点代表两个测量性能事件之间的时间序列相关性,这是来自具有大约1700个非零事件测量的Skylake机器): 
您也可以查看单个事件
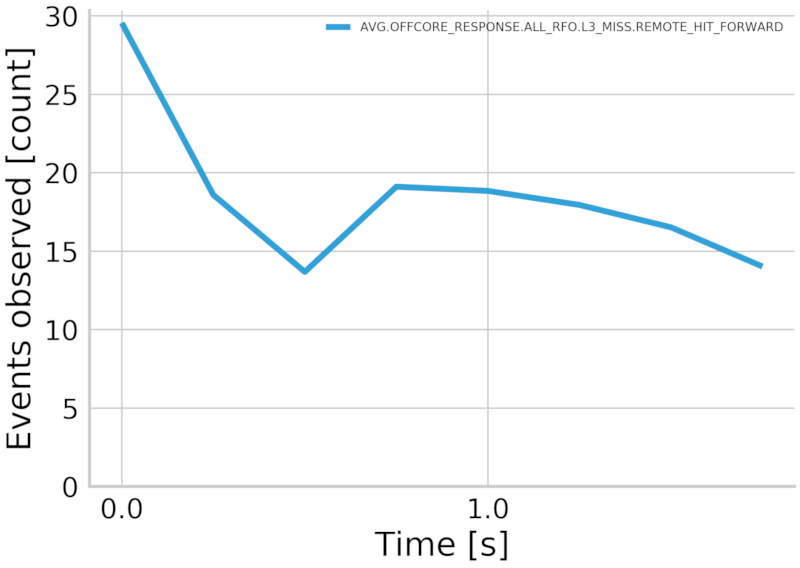
python3 analyze/profile/event_detail.py --resultdir ./out --features AVG.OFFCORE_RESPONSE.ALL_RFO.L3_MISS.REMOTE_HIT_FORWARD
analyze文件夹中还有更多脚本,可以更好地处理捕获的数据集。请查看。
我可以用这个做什么?
autoperf允许您快速收集大量的性能(或训练)数据,并以定量方式对其进行分析。例如,我们最初开发autoperf是为了构建Barrelfish调度器可以用来检测应用程序降级并做出更好调度决策的ML分类器。autoperf可以收集这些数据来生成这样的分类器,而不需要关于事件领域的知识,只需了解如何测量它们即可。
您可以在以下链接中了解更多关于我们的实验
- https://dl.acm.org/citation.cfm?id=2967360.2967375
- https://www.research-collection.ethz.ch/handle/20.500.11850/155854
最后但同样重要的是,autoperf可能在许多其他场景中很有用
- 找出哪些性能事件与您的作业相关
- 分析和查找您的代码或不同版本的代码中的性能问题
- 生成检测硬件漏洞(旁路通道/spectre/meltdown等)的分类器
- ...
依赖关系
~9–18MB
~196K SLoC